Tutorials

April 23, 2024
Democratizing AI Workflows with Union.ai and NVIDIA DGX Cloud

April 23, 2024
Webinar: Enhance LLMs with RAG and Accelerate Enterprise AI with Pure Storage and NVIDIA
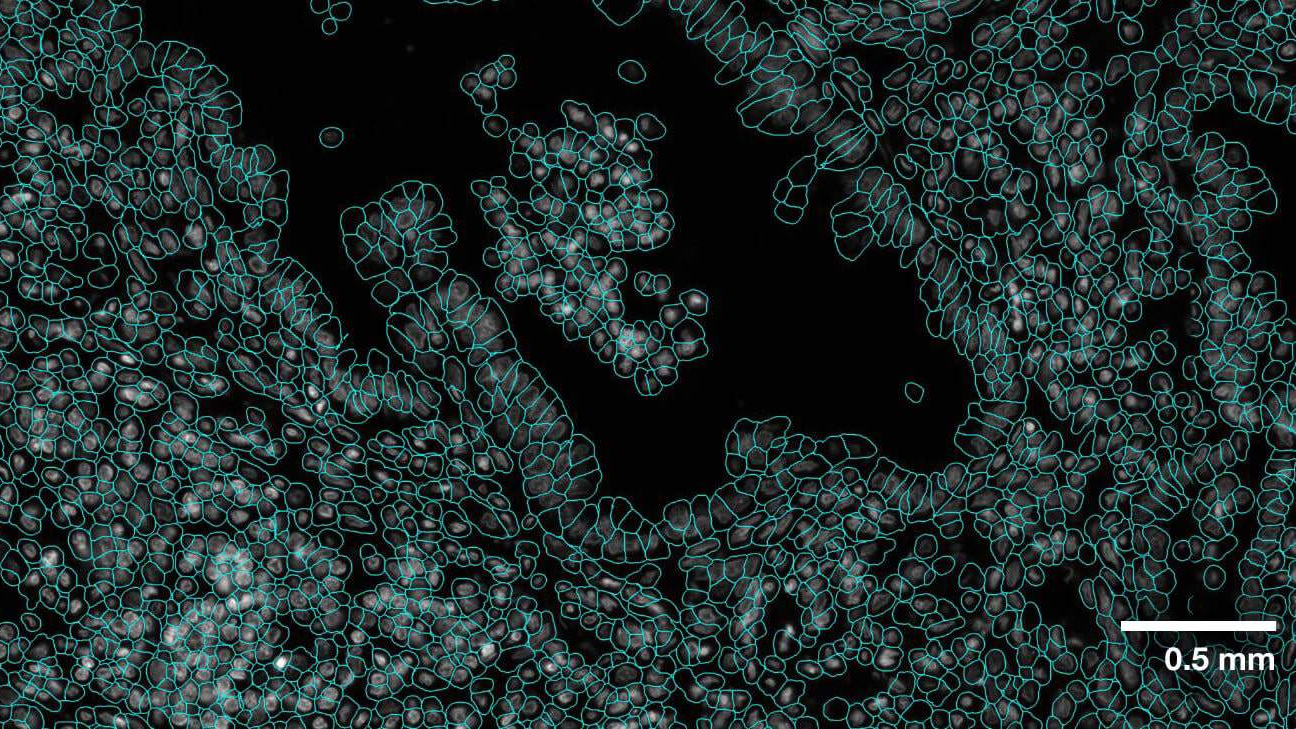
April 22, 2024
Advancing Cell Segmentation and Morphology Analysis with NVIDIA AI Foundation Model VISTA-2D
News

April 22, 2024
Just Released: NVIDIA Modulus v24.04

April 11, 2024
New Video Series: OpenUSD for Developers

March 19, 2024
Generative AI for Digital Humans and New AI-powered NVIDIA RTX Lighting

March 19, 2024
NVIDIA Speech and Translation AI Models Set Records for Speed and Accuracy
Training



Model Parallelism: Building and Deploying Large Neural Networks
Instructor-Led, Certificate Available
