Inférence IA
NVIDIA Dynamo
Faites évoluer et mettez en œuvre rapidement l'inférence IA.
Aperçu
Le système d'exploitation de l'IA
La mise en œuvre efficace des modèles de langage de pointe actuels nécessite souvent des ressources qui dépassent la capacité d'un seul GPU voire d'un nœud entier, ce qui rend le déploiement multi-nœuds distribué essentiel pour l'inférence IA.
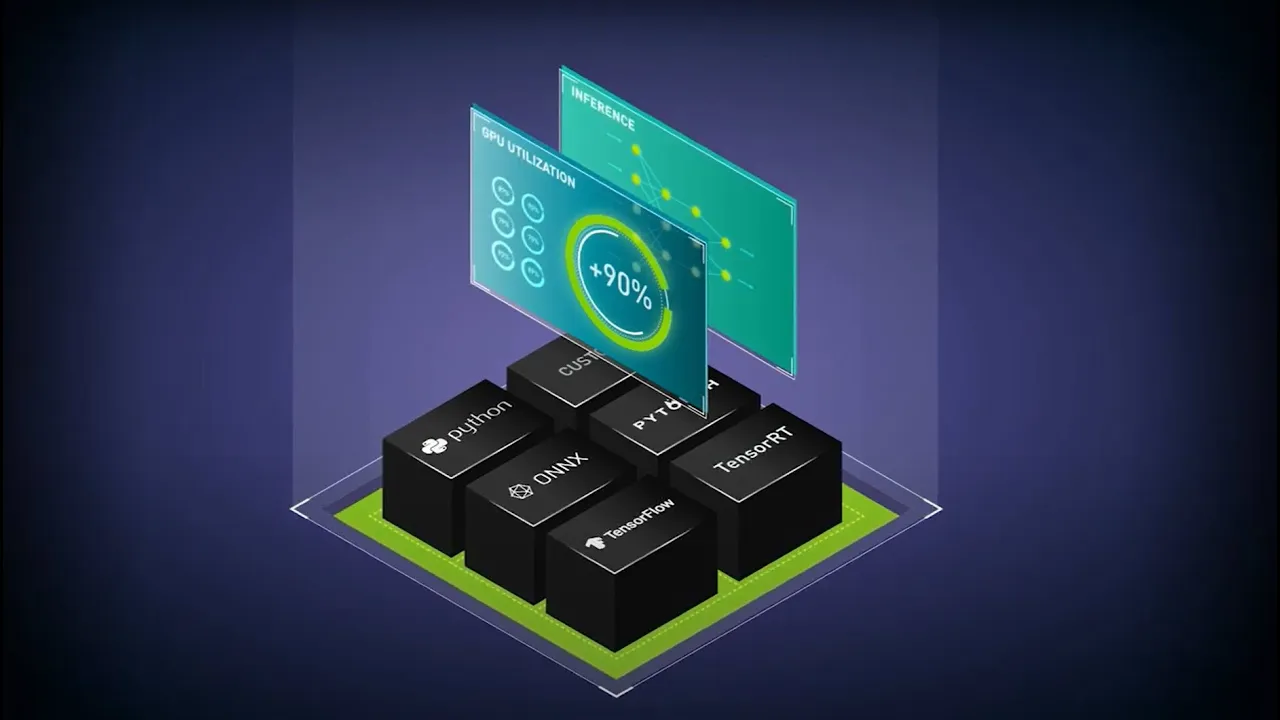
NVIDIA Dynamo est un framework de service d'inférence distribué open source conçu pour déployer des modèles dans des environnements multi-nœuds à l'échelle des Data Centers. Cette solution prend en charge les moteurs d'inférence open source (notamment SGLang, NVIDIA TensorRT™ LLM et vLLM) et simplifie les complexités de la mise en service distribuée en désagrégeant les phases d'inférence sur différents GPU, en acheminant intelligemment les demandes vers le GPU approprié pour éviter les calculs redondants et en étendant la mémoire GPU à des niveaux de stockage à haut rendement grâce à la mise en cache des données.
Les microservices NVIDIA NIM™ incluront les capacités de NVIDIA Dynamo pour fournir une option de déploiement rapide et facile. NVIDIA Dynamo sera également pris en charge et disponible avec NVIDIA AI Enterprise.
Découvrez NVIDIA Dynamo de plus près
Framework d'inférence distribué à faible latence pour la mise à l'échelle des modèles d'IA de raisonnement.
 jusqu'à 15 fois par rapport aux systèmes basés sur Hopper.")
Des benchmarks indépendants montrent que la combinaison de NVIDIA GB300 NVL72 et de NVIDIA Dynamo améliore le débit des modèles MoE (Mixture of Experts) jusqu'à 50 fois par rapport aux systèmes basés sur NVIDIA Hopper™.
Le GB300 NVL72 connecte 72 GPU via NVIDIA NVLink™ à haute vitesse, ce qui permet une communication experte à faible latence essentielle pour les modèles de raisonnement MoE. NVIDIA Dynamo améliore l'efficacité grâce à une inférence désagrégée, en divisant les phases de pré-remplissage et de décodage entre les nœuds pour une optimisation indépendante. Ensemble, GB300 NVL72 et NVIDIA Dynamo forment une pile haute performance optimisée pour l'inférence MoE à grande échelle.
Fonctionnalités
Découvrez les fonctionnalités de NVIDIA Dynamo



")

")


Accélérez l'inférence distribuée
NVIDIA Dynamo est entièrement open source, ce qui vous offre une transparence et une flexibilité totales. Déployez NVIDIA Dynamo, contribuez à sa croissance et intégrez-le facilement dans votre pile existante.
Découvrez cette offre sur GitHub et rejoignez la communauté !
Avantages
Les avantages de NVIDIA Dynamo

Passez facilement d'un GPU à des milliers de GPU
Simplifiez et automatisez la configuration des clusters de GPU avec des outils préconstruits et faciles à déployer et permettez une auto-mise à l'échelle dynamique avec des métriques spécifiques aux LLM en temps réel, évitant ainsi le sur-ou le sous-approvisionnement des ressources GPU.

Augmentez la capacité de traitement d'inférence tout en réduisant les coûts
Exploitez les optimisations avancées de service d'inférence LLM, telles que le service désagrégé et la mise à l'échelle automatique en fonction de la topologie, pour augmenter le nombre de demandes d'inférence traitées sans compromettre l'expérience utilisateur.

Adaptez votre infrastructure d'IA pour l'avenir et évitez des migrations coûteuses
La conception ouverte et modulaire vous permet de sélectionner facilement les composants d'inférence qui répondent à vos besoins uniques, garantissant ainsi la compatibilité avec votre pile d'IA existante et évitant les projets de migration coûteux.

Accélérez les délais de déploiement de nouveaux modèles d'IA en production
La prise en charge par NVIDIA Dynamo de tous les principaux frameworks, notamment NVIDIA TensorRT-LLM, vLLM, SGLang, PyTorch et bien d'autres encore, garantit votre capacité à déployer rapidement de nouveaux modèles d'IA générative, quel que soit leur backend.
Partenaires de l'écosystème Dynamo

Cas d'utilisation
Déploiement de l'IA avec NVIDIA Dynamo
Découvrez comment vous pouvez stimuler l'innovation grâce à NVIDIA Dynamo.
-
Modèles de raisonnement de traitement
-
Mise à l'échelle de l'IA avec Kubernetes
-
Déploiement d'agents d'IA
-
Génération de code
Traitement de modèles de raisonnement
Les modèles de raisonnement génèrent plus de jetons pour résoudre des problèmes complexes, ce qui augmente les coûts d'inférence. NVIDIA Dynamo optimise ces modèles grâce à des fonctionnalités telles que la distribution désagrégée. Cette approche sépare les phases de calcul de pré-remplissage et de décodage dans des GPU distincts, ce qui permet aux équipes d'inférence d'IA d'optimiser chaque phase de manière indépendante. Il en résulte une meilleure utilisation des ressources, plus de requêtes traitées par GPU et une réduction des coûts d'inférence. Combiné au modèle NVIDIA GB200 NVL72, NVIDIA Dynamo augmente jusqu'à 15 fois les performances de composition.

Mise à l'échelle de l'IA avec Kubernetes
À mesure que les modèles d'IA deviennent trop grands pour s'insérer sur un seul nœud, leur exploitation efficace devient plus complexe. L'inférence distribuée nécessite de diviser les modèles sur plusieurs nœuds, ce qui ajoute de la complexité en matière d'orchestration, de mise à l'échelle et de communication dans les environnements basés sur Kubernetes. La garantie de fonctionnement de ces nœuds en tant qu'unité cohésive, en particulier dans les charges de travail dynamiques, exige une gestion minutieuse. NVIDIA Dynamo simplifie cette tâche en utilisant Grove, qui gère la planification, la mise à l'échelle et le service en toute simplicité, afin que vous puissiez vous concentrer sur le déploiement de l'IA et non sur la gestion de l'infrastructure.

Agents d'IA évolutifs
Les agents d'IA génèrent d'énormes quantités de cache KV lorsqu'ils travaillent en temps réel avec plusieurs modèles : LLM, systèmes de récupération et outils spécialisés. Ce cache KV dépasse souvent la capacité de la mémoire GPU, ce qui crée un goulet d'étranglement en matière de mise à l'échelle et de performances.
Pour surmonter les limitations de la mémoire GPU, la mise en cache des données KV dans la mémoire hôte ou le stockage externe augmente la capacité, ce qui permet aux agents d'IA d'évoluer sans contraintes. NVIDIA Dynamo simplifie cette tâche grâce à son système de gestion KV Cache Manager et à l'intégration à des outils open source tels que LMCache afin de garantir une gestion efficace du cache et des performances évolutives des agents d'IA.

Génération de code
La génération de code nécessite souvent un raffinement itératif pour ajuster les invites, clarifier les exigences ou déboguer les résultats en fonction des réponses du modèle. Ce va-et-vient nécessite un nouveau calcul du contexte à chaque exécution de l'utilisateur, ce qui augmente les coûts d'inférence. NVIDIA Dynamo optimise ce processus en permettant la réutilisation du contexte.
Le routeur compatible LLM de NVIDIA Dynamo gère intelligemment le cache KV sur les clusters GPU multi-nœuds. Il achemine les requêtes en fonction du chevauchement de cache, les dirigeant vers les GPU offrant le potentiel de réutilisation le plus élevé. Cela permet de minimiser les calculs redondants et garantit des performances équilibrées lors des déploiements à grande échelle.

Témoignages clients
Découvrez ce que les leaders de l'industrie ont à dire sur NVIDIA Dynamo
Cohere
« La mise à l'échelle des modèles d'IA avancés nécessite une planification multi-GPU sophistiquée, une coordination transparente et des bibliothèques de communication à faible latence qui transfèrent facilement les contextes de raisonnement dans la mémoire et le stockage. Nous nous attendons à ce que Dynamo nous aide à offrir une expérience utilisateur de premier ordre à nos clients professionnels. »
Saurabh Baji, vice-président principal de l'ingénierie chez Cohere
Perplexity AI
« Nous traitons des centaines de millions de requêtes par mois, et nous nous appuyons sur les GPU et les logiciels d'inférence de NVIDIA pour offrir les performances, la fiabilité et l'évolutivité qu'exigent notre entreprise et nos utilisateurs. Nous avons hâte d'exploiter Dynamo et ses capacités de service distribué améliorées pour obtenir encore plus d'efficacité en matière de service d'inférence et répondre aux exigences de calcul des nouveaux modèles de raisonnement d'IA. »
Denis Yarats, CTO de Perplexity AI.
Together AI
« Faire évoluer les modèles de raisonnement de manière rentable nécessite de nouvelles techniques d'inférence avancées, notamment une prestation désagrégée et un routage sensible au contexte. Together AI fournit des performances de pointe pour l'industrie à l'aide de notre moteur d'inférence propriétaire. L'ouverture et la modularité de NVIDIA Dynamo nous permettront de connecter facilement ses composants à notre moteur pour répondre à plus de requêtes tout en optimisant l'utilisation des ressources, ce qui maximisera notre investissement dans le calcul accéléré. »
Ce Zhang, CTO de Together AI.
Études de cas
Comment les leaders de l'industrie améliorent le déploiement de modèles avec la plateforme NVIDIA Dynamo
NVIDIA Blackwell Ultra offre des performances jusqu'à 50 fois supérieures et des coûts 35 fois inférieurs pour l'IA agentique
Conçu pour accélérer la nouvelle génération d'IA agentique, NVIDIA Blackwell Ultra offre des performances d'inférence révolutionnaires à des coûts considérablement réduits. Les fournisseurs Cloud tels que Microsoft, CoreWeave et Oracle Cloud Infrastructure déploient des systèmes NVIDIA GB300 NVL72 à grande échelle pour des cas d'utilisation à faible latence et à long contexte, tels que le codage agentique et les assistants de codage.
Cette initiative de mise à niveau axée sur l'excellence permet la co-conception approfondie sur NVIDIA Blackwell, NVLink™ et NVLink Switch pour l’évolutivité, NVFP4 pour la précision, NVIDIA Dynamo et les LLM TensorRT™ pour la vitesse et la flexibilité, ainsi que le développement avec les frameworks communautaires SGLang, vLLM et bien plus encore.

Ressources
Actualités de l'Inférence avec NVIDIA
-
Articles de blog
-
Sessions
-
Formation
-
Vidéos












Étapes suivantes
Vous voulez vous lancer ?
Téléchargez sur GitHub et rejoignez la communauté !

Pour les développeurs
Découvrez tout ce dont vous avez besoin pour commencer à développer avec NVIDIA Dynamo, notamment la documentation la plus récente ainsi que des didacticiels, des articles techniques et plus encore.

Contactez-nous
Discutez avec un spécialiste des produits NVIDIA pour savoir comment passer du stade de pilote à la phase de production en bénéficiant de la garantie de sécurité, de stabilité d'API et du support technique de NVIDIA AI Enterprise.