According to Thomas Davenport in the updated version of Competing on Analytics, analytical technology has changed dramatically over the last decade, with more powerful and less expensive distributed computing across commodity servers, and improved machine learning (ML) technologies, enabling companies to store and analyze many different types of data and far more of it.
Preface: Why are GPUs Driving the Next Wave of Data Science?
The Evolution of Data Analytics
The Beginning of Big Data Processing
Google invented a distributed file system and MapReduce, a resilient distributed processing framework, in order to index the exploding volume of content on the web, across large clusters of commodity servers. The Google file system (GFS) partitioned, distributed, and replicated file data across the data nodes in a cluster. MapReduce distributed computation across the data nodes in a cluster: users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs and a reduce function that merges all intermediate values associated with the same intermediate key. Both the GFS and MapReduce were designed for fault tolerance by failing over to another node for data or processing.
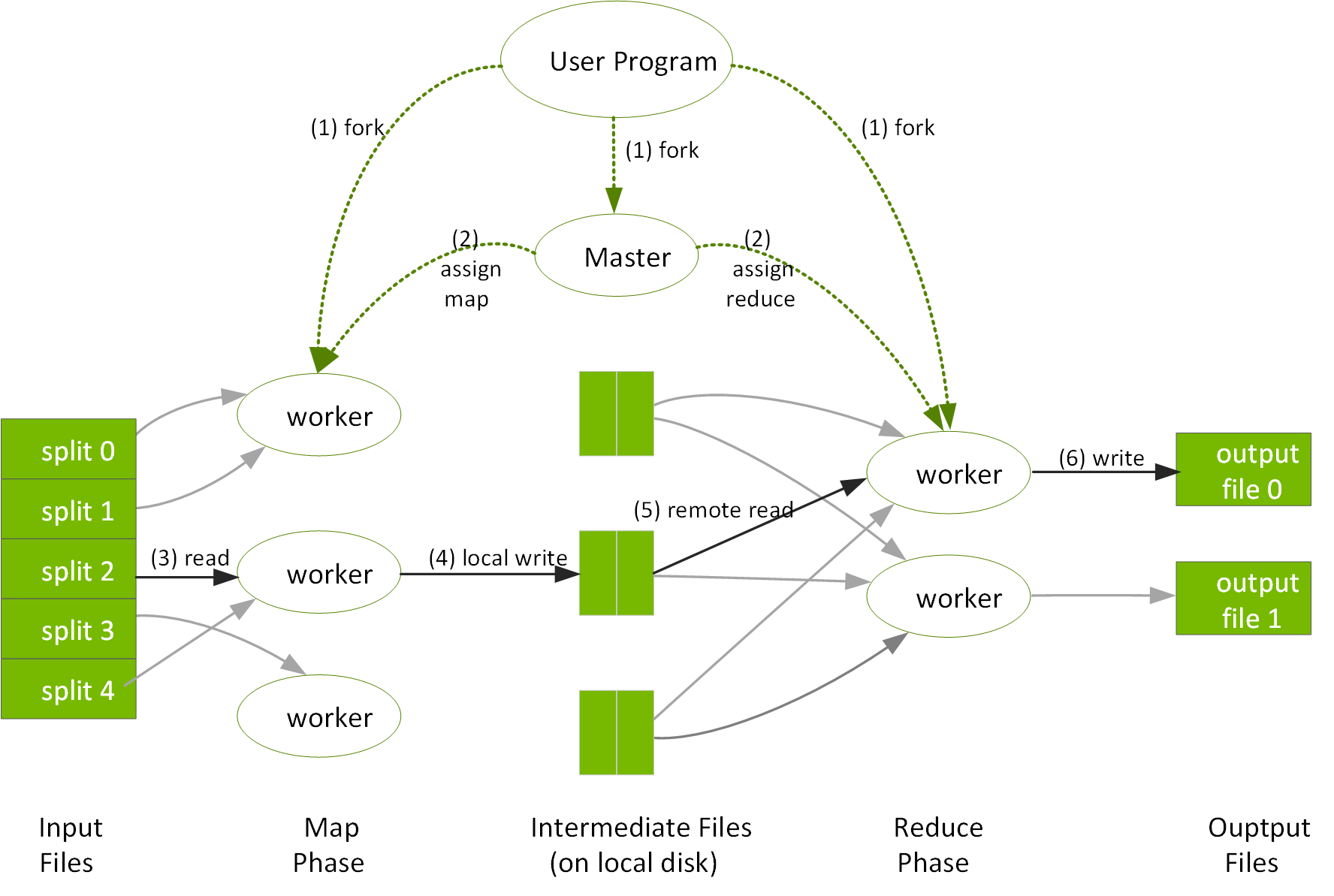
Reference: MapReduce Google White Paper
A year after Google published a white paper describing the MapReduce framework, Doug Cutting and Mike Cafarella created Apache Hadoop.
However, Hadoop performance is bottlenecked by its model of checkpointing results to disk. At the same time, Hadoop adoption has been hindered by the low-level programming model of MapReduce. Data pipelines and iterative algorithms require chaining multiple MapReduce jobs together, which can be difficult to program and cause a lot of reading and writing to disk.
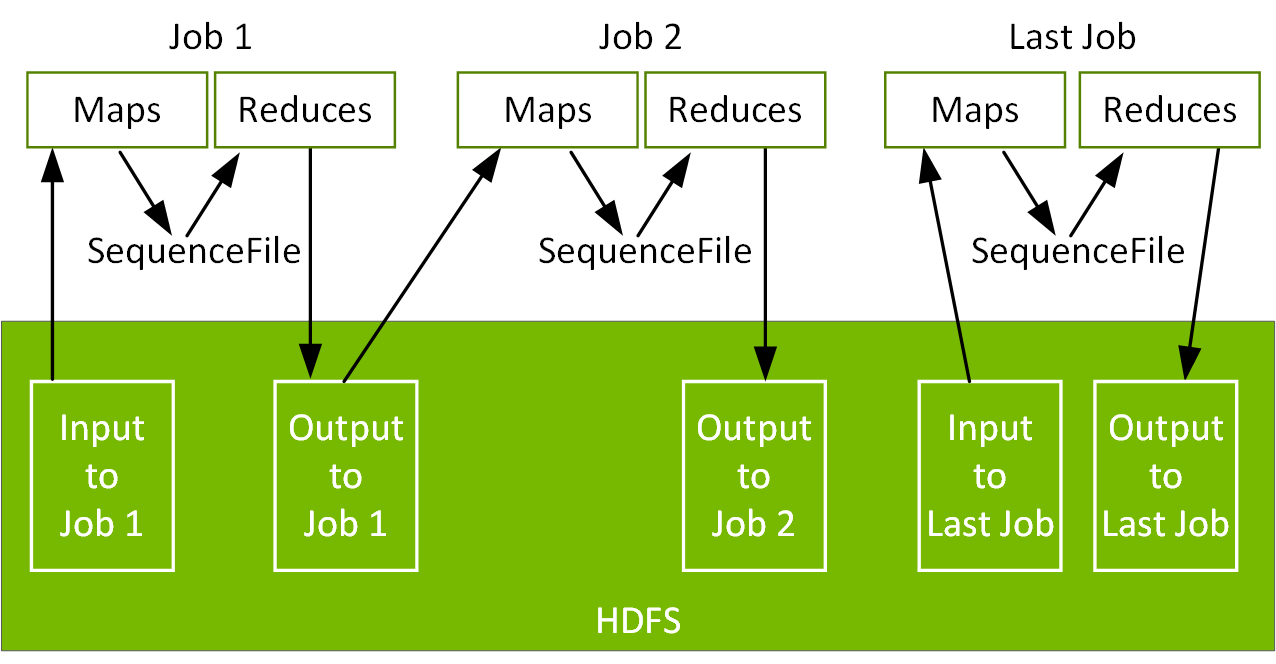
Apache Spark Makes Big Data Processing Faster and Easier
Apache Spark started as a research project at UC Berkeley in the AMPLab, became a top level Apache Software Foundation project in 2014, and is now maintained by a community of hundreds of developers from hundreds of organizations. Spark was developed with the goal of keeping the benefits of MapReduce’s scalable, distributed, fault-tolerant processing framework, while making it more efficient and easier to use. Spark is more efficient than MapReduce for data pipelines and iterative algorithms because it caches data in memory across iterations and uses lighter weight threads. Spark also provides a richer functional programming model than MapReduce.
Distributed Datasheet
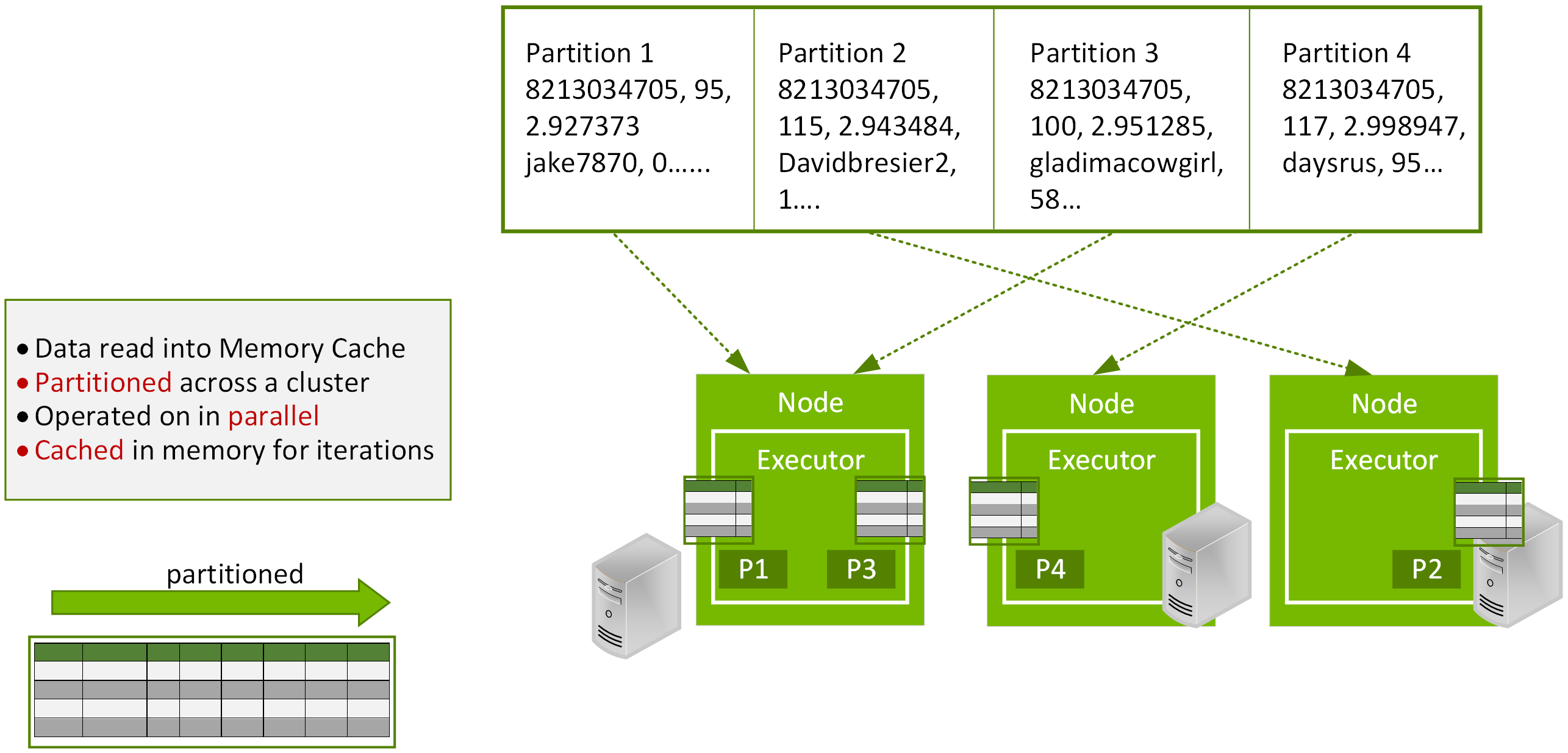
Spark mitigated the I/O problems found in Hadoop, but now the bottleneck has shifted from I/O to compute for a growing number of applications. This performance bottleneck has been thwarted with the advent of GPU-accelerated computation.
GPUs Accelerate Computer Processing
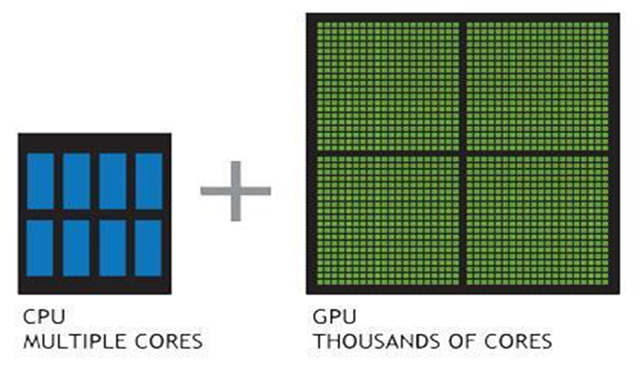
Graphics Processing Units (GPUs) are popular for their extraordinarily low price per flop (performance) and are addressing the compute performance bottleneck today by speeding up multi-core servers for parallel processing.
A CPU consists of a few cores, optimized for sequential serial processing. Whereas, a GPU has a massively parallel architecture consisting of thousands of smaller, more efficient cores designed for handling multiple tasks simultaneously. GPUs are capable of processing data much faster than configurations containing CPUs alone.
Once large amounts of data need to be broadcasted, aggregated, or collected across nodes in a cluster, the network can become a bottleneck. GPUDirect Remote direct memory access with the NVIDIA Collective Communications Library can solve this bottleneck by allowing GPUs to communicate directly with each other, across nodes, for faster multi-GPU and multi-node reduction operations.
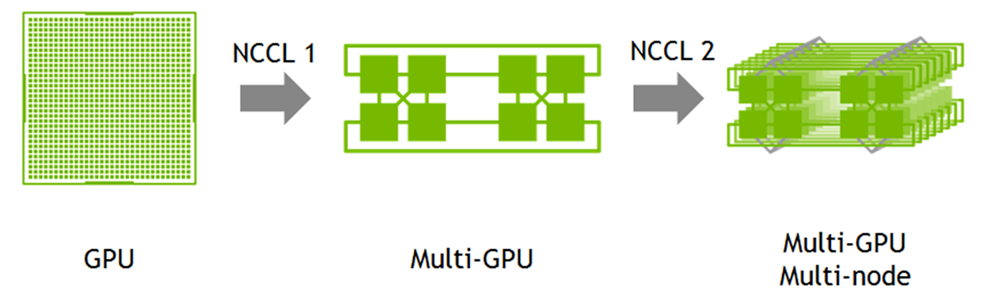
The benefits of GPUDirect RDMA are also critical for large, complex extract, transform, load (ETL) workloads, allowing them to operate as if they were on one massive server.
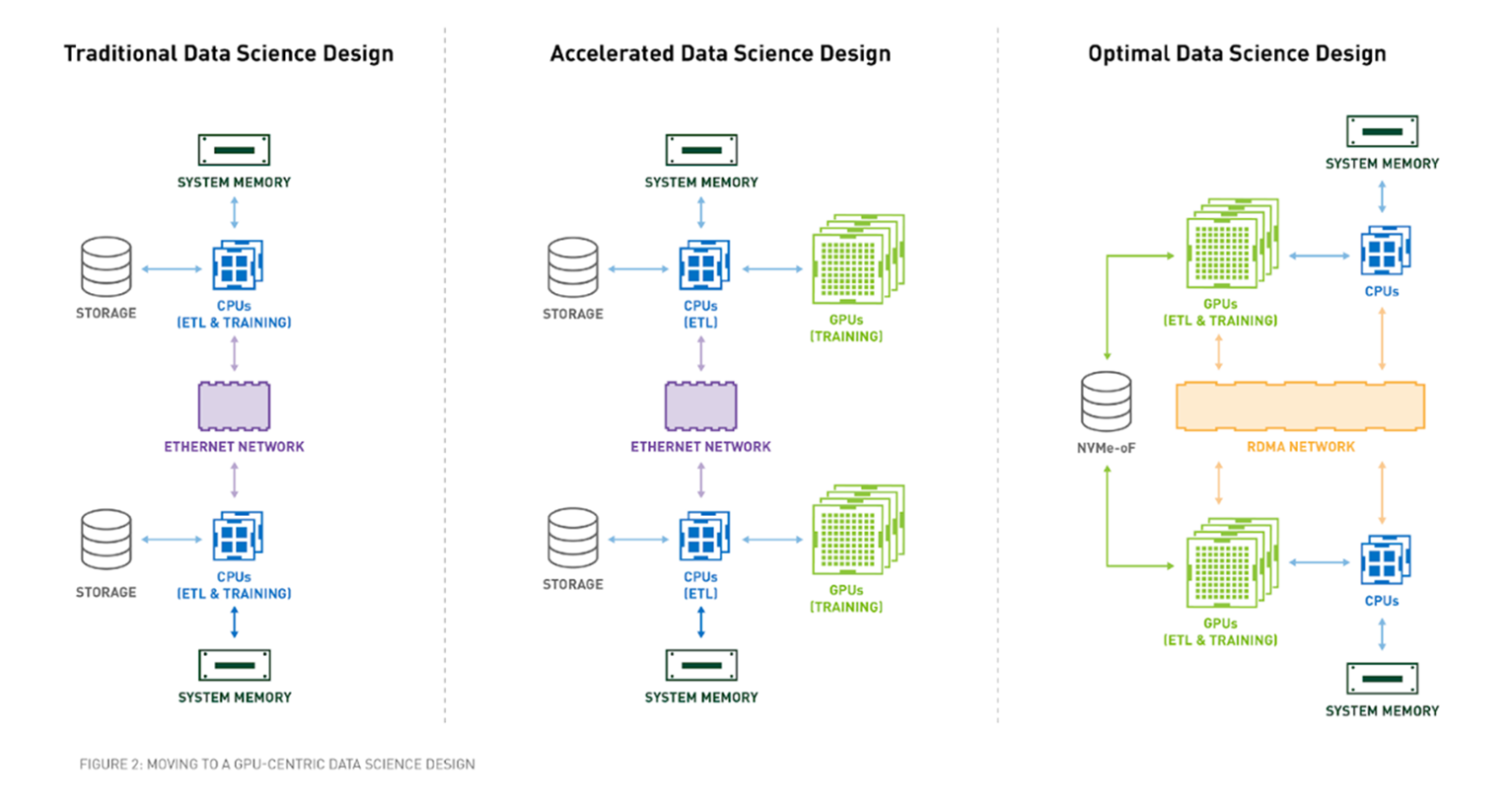
GPU-Accelerated Data Science Powered by RAPIDS
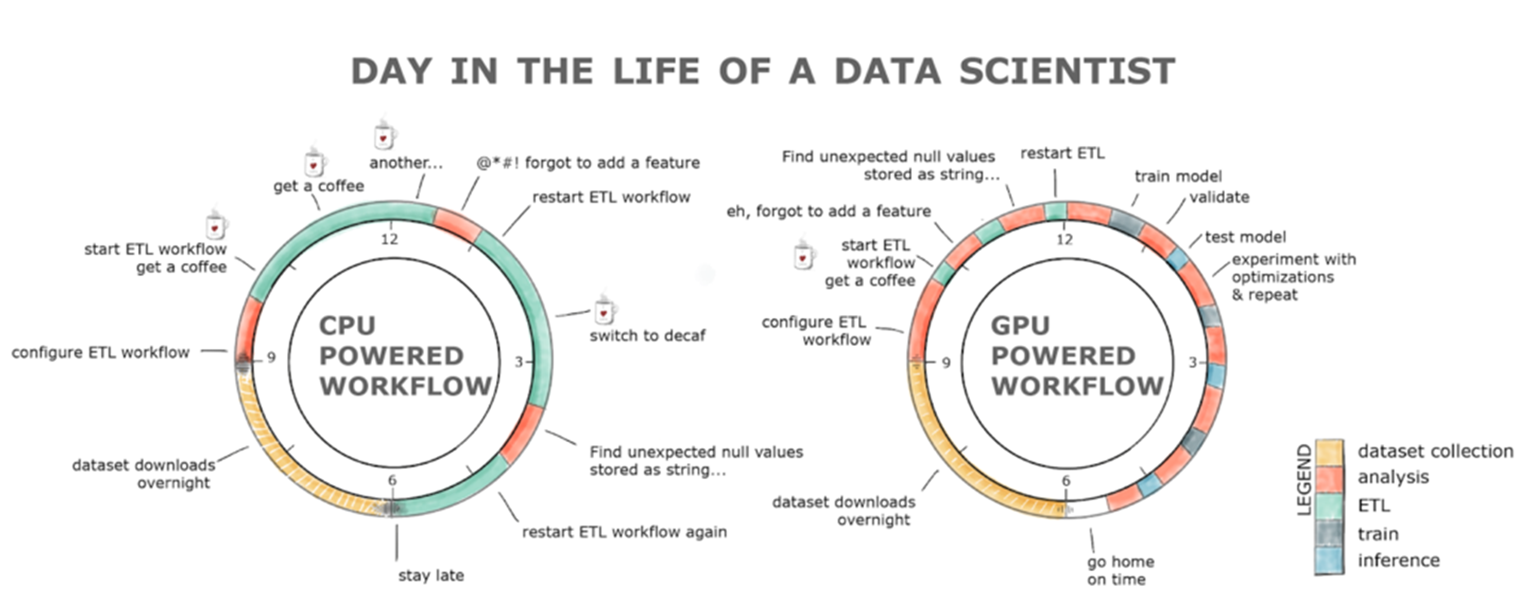
A key component of data science is data exploration. Preparing a data set for ML requires understanding the data set, cleaning and manipulating data types and formats, and extracting features for the learning algorithm. These tasks are grouped under the term ETL. ETL is often an iterative, exploratory process. As data sets grow, the interactivity of this process suffers when running on CPUs.
GPUs have been responsible for the advancement of deep learning (DL) in the past several years, while ETL and traditional ML workloads continued to be written in Python, often with single-threaded tools like Scikit-Learn or large, multi-CPU distributed solutions like Spark.
RAPIDS is a suite of open-source software libraries and APIs for executing end-to-end data science and analytics pipelines entirely on GPUs, achieving speedup factors of 50X or more on typical end-to-end data science workflows. RAPIDS accelerates the entire data science pipeline, including data loading, enabling more productive, interactive, and exploratory workflows.
Built on top of NVIDIA® CUDA®, an architecture and software platform for GPU computing, RAPIDS exposes GPU parallelism and high-bandwidth memory speed through user-friendly APIs. RAPIDS focuses on common data preparation tasks for analytics and data science, offering a powerful GPU DataFrame that is compatible with ApacheArrow data structures with a familiar DataFrame API.
Apache Arrow specifies a standardized language-independent columnar memory format, optimized for data locality, to accelerate analytical processing performance on modern CPUs or GPUs, and provides zero-copy streaming messaging and interprocess communication without serialization overhead.
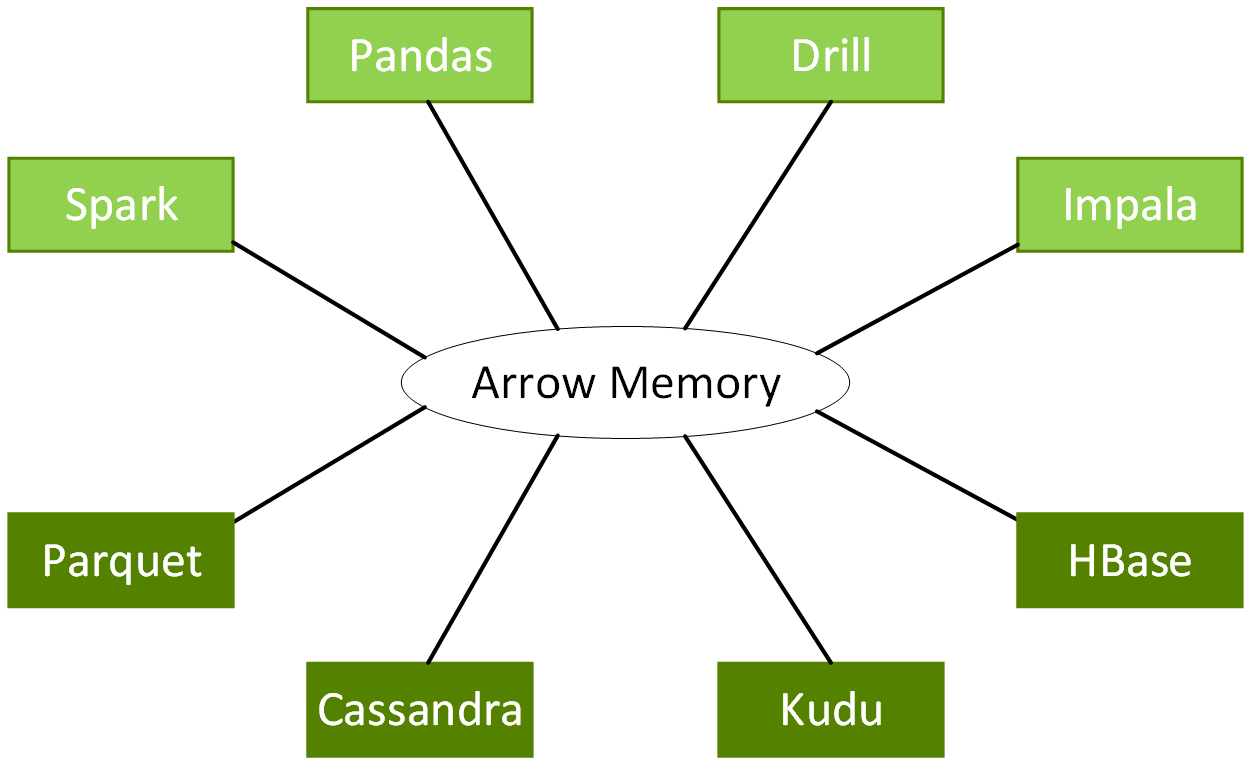
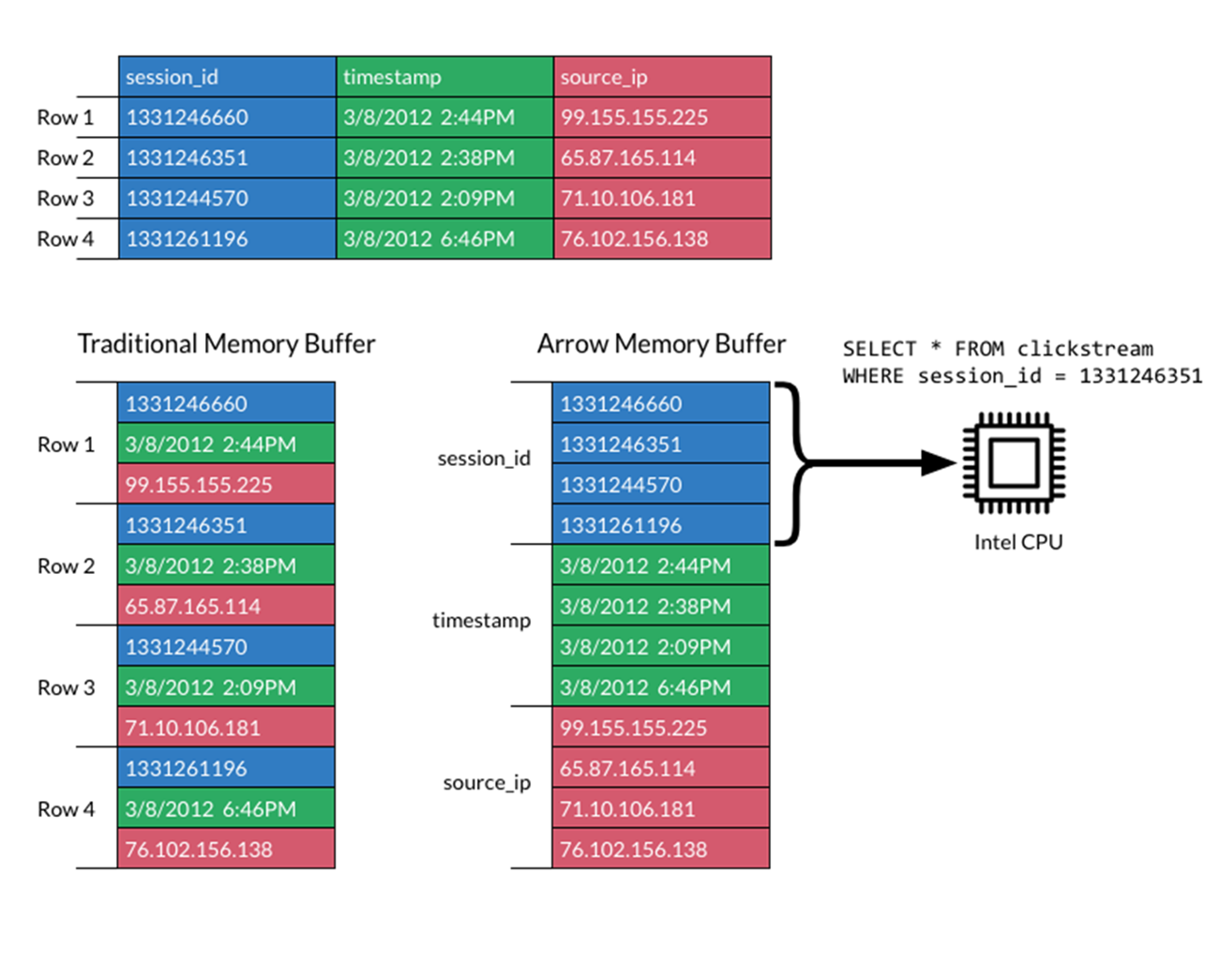
The DataFrame API integrates with a variety of ML algorithms without incurring typical serialization and deserialization costs, enabling end-to-end pipeline accelerations.
By hiding the complexities of low-level CUDA programming, RAPIDS creates a simple way to execute data science tasks. As more data scientists use Python and other high-level languages, providing acceleration with minimal to no code change is essential to rapidly improving development time.
Boosting Data Science Frameworks with GPUs and the RAPIDS Library
Another way RAPIDS accelerates development is with integration to leading data science frameworks, such as PyTorch, Chainer, and ApacheMxNet for DL and distributed computing frameworks like Apache Spark and Dask for seamless scaling from GPU workstations to multi-GPU servers and multi-node clusters. Also, products such as BlazingSQL, an open source SQL engine, are being built on top of RAPIDS, adding even more accelerated capabilities for users.
Apache Spark 3.x empowers GPU applications by providing user APIs and configurations to easily request and utilize GPUs and is now extensible to allow columnar processing on the GPU; all of which wasn’t supported prior to Spark 3.x. Internally, Spark added GPU scheduling, further integration with the cluster managers (YARN, Kubernetes, etc.) to request GPUs, and plugin points to allow it to be extended to run operations on the GPU. This makes GPUs easier to request and use for Spark application developers, allows for closer integration with DL and AI frameworks, such as Horovod and TensorFlow on Spark, and allows for better utilization of GPUs. This extensibility also allows columnar processing, which opens up the possibility for users to add plugins that accelerate queries using the GPU.
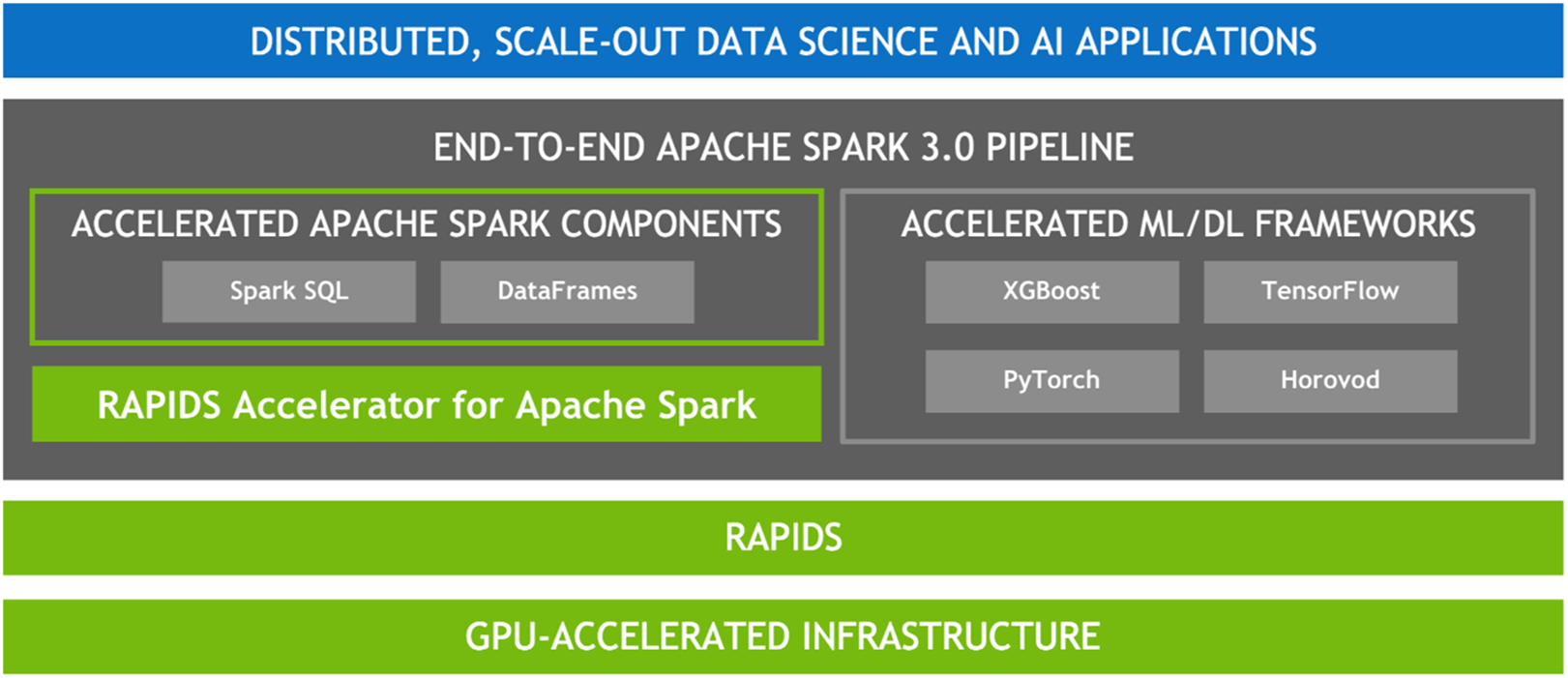
Later in this eBook, we explore how the Apache Spark 3.x stack shown below accelerates Spark 3.x applications.
APACHE SPARK 3.x GPU-ACCELERATED SOFTWARE STACK
NVIDIA GPUs in Action
Regardless of industry or use case, when putting ML into action, many data science problems break down into similar steps: iteratively preprocessing data to build features, training models with different parameters, and evaluating the model to ensure performance translates into valuable results.
RAPIDS helps accelerate all of these steps while maximizing the user’s hardware investments. Early customers have taken full data pipelines that took days, if not weeks, and ran them in minutes. They’ve simultaneously reduced costs and improved the accuracy of their models since more iterations allow data scientists to explore more models and parameter combinations, as well as train on larger datasets.
Retailers are improving their forecasting. Finance companies are getting better at assessing credit risk. And adtech firms are enhancing their ability to predict click-through rates. Data scientists often achieve improvements of 1-2 percent. This can translate to tens or hundreds of millions of dollars of revenue and profitability.