Text-to-speech is a form of speech synthesis that converts any string of text characters into spoken output.
Text-to-speech
What is Text-to-Speech?
Generating high-quality, natural-sounding speech from text with low latency—also known as text-to-speech (TTS)—has been a challenging task for decades. It was originally developed as a way to enable people with visual impairments or reading disabilities to listen to written words. Today, text-to-speech has evolved to a diverse range of use cases that formerly required human operators or in which reading isn’t practical. These include providing driving directions, conversing with customers in a call center, and powering virtual assistants.
The most common systems used pre-recorded speech elements that are pieced together in real-time. More recently, neural networks have been applied to create natural-sounding speech that’s entirely machine-generated.

Why Text-to-Speech?
Text-to-speech permeates our everyday lives, ranging from talking alarm clocks to automotive assistants that translate text messages into voice to sophisticated query-and-response systems such as Apple’s Siri and Amazon’s Echo. These address the many use cases in which reading from the screen is either impractical or inconvenient.
Text-to-speech is increasingly moving into conversational AI domains that involve Automatic Speech Recognition (ASR) and Natural Language Processing (NLP), such as translating between languages. A growing area is in customer service, where speech-recognition systems can process complex queries, search a database for answers, and deliver responses using text-to-speech. Telemarketers now employ these systems to replace human callers with conversational robots that can carry on realistic conversations to the point that a human operator is no longer needed.

Research has shown that people are more comfortable conversing when the responses are delivered in a human-like voice. Neural networks enable the domain of sounds that text-to-speech systems can produce to be increased without the overhead of concatenative synthesis or the complexity of articulatory synthesis.
How Does Text-to-Speech Work?
State-of-the-art speech synthesis models are based on parametric neural networks. Text-to-speech (TTS) synthesis is typically done in two steps.
- In the first step, a synthesis network transforms the text into time-aligned features, such as a spectrogram, or fundamental frequencies, which are the frequency at which vocal cords vibrate in voiced sounds.
- In the second step, a vocoder network converts the time-aligned features into audio waveforms.

Preparing the input text for synthesis requires text analysis, such as converting text into words and sentences, identifying and expanding abbreviations, and recognizing and analyzing expressions. Expressions include dates, amounts of money, and airport codes.
The output from text analysis is passed into linguistic analysis for refining pronunciations, calculating the duration of words, deciphering the prosodic structure of utterance, and understanding grammatical information.
Output from linguistic analysis is then fed to a speech synthesis neural network model, such as Tacotron2, which converts the text to mel spectrograms and then to a neural vocoder model like Wave Glow to generate the natural sounding speech.
Popular deep learning models for TTS include Wavenet, Tacotron 2, and WaveGlow.
In 2006, Google WaveNet introduced deep learning techniques with a new approach that directly modeled the raw waveform of the audio signal one sample at a time. Its model is probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones. WaveNet is a fully convolutional neural network with the convolutional layers having various dilation factors that allow its receptive field to grow exponentially with depth. Input sequences are waveforms recorded from human speakers.
 deepmind)
deepmind)
Tacotron 2 is a neural network architecture for speech synthesis directly from text using a recurrent sequence-to-sequence model with attention. The encoder (blue blocks in the figure below) transforms the whole text into a fixed-size hidden feature representation. This feature representation is then consumed by the autoregressive decoder (orange blocks) that produces one spectrogram frame at a time. In the NVIDIA Tacotron 2 and WaveGlow for PyTorch model, the autoregressive WaveNet (green block) is replaced by the flow-based generative WaveGlow.

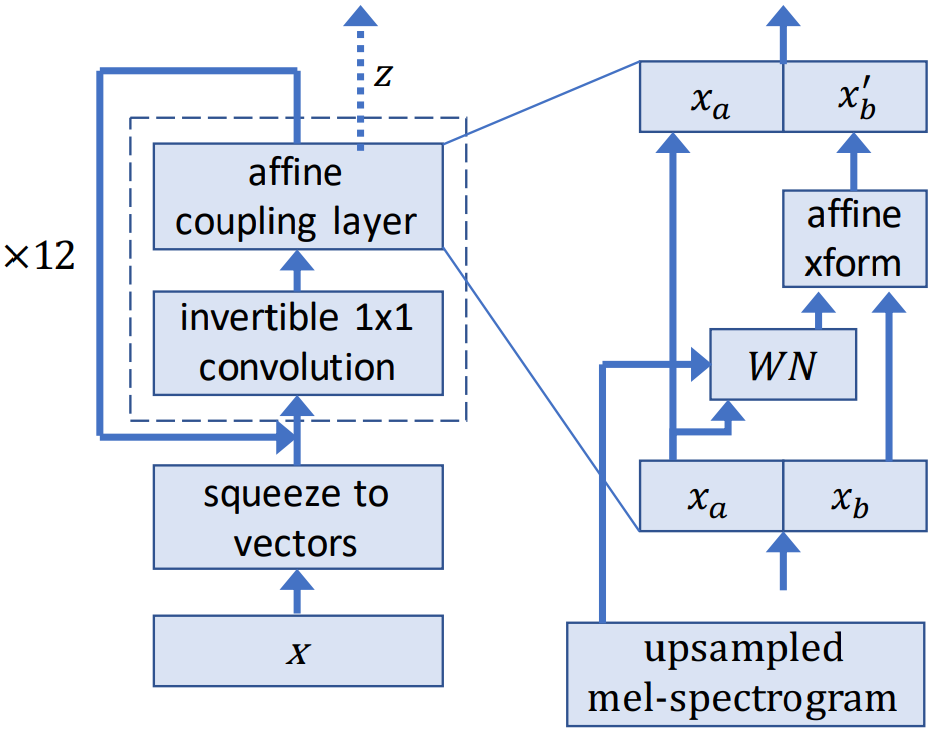
WaveGlow is a flow-based model that consumes the mel spectrograms to generate speech.
During training, the model learns to transform the dataset distribution into spherical Gaussian distribution through a series of flows. One step of a flow consists of an invertible convolution, followed by a modified WaveNet architecture that serves as an affine coupling layer. During inference, the network is inverted and audio samples are generated from the Gaussian distribution.
Industry Applications
Healthcare
One of the difficulties facing healthcare is making it easily accessible. Calling your doctor’s office and waiting on hold is a common occurrence, and connecting with a claims representative can be equally difficult. The implementation of natural language processing (NLP) to train chatbots is an emerging technology within healthcare to address the shortage of healthcare professionals and open the lines of communication with patients.
In this blog—Empowering Smart Hospitals with NVIDIA Clara Guardian from NGC and NVIDIA Fleet Command—you can read about how you can build a Virtual Patient Assistant client application that takes input queries from the patient, interprets the query by extracting intent and relevant slots, and computes a response in real time, in a natural-sounding voice.
Financial Services
NLP is a critically important part of building better chatbots and AI assistants for financial service firms.
Retail
Chatbot technology is also commonly used for retail applications to accurately analyze customer queries and generate responses or recommendations. This streamlines the customer journey and improves efficiencies in store operations.
GPUs: Accelerating Deep Learning
Recent innovations like Tacotron 2 have brought text-to-speech squarely into the domain of deep learning. State-of-the-art deep learning neural networks can have from millions to well over one billion parameters to adjust via back-propagation. They also require a large amount of training data to achieve high accuracy, meaning hundreds of thousands to millions of input samples will have to be run through both a forward and backward pass. Because neural nets are created from large numbers of identical neurons they are highly parallel by nature. This parallelism maps naturally to GPUs, providing a significant computation speed-up over CPU-only training. GPUs have become the platform of choice for training large, complex neural network-based systems for this reason, and the parallel nature of inference operations also lend themselves well for execution on GPUs.

NVIDIA GPU-Accelerated Text-to-Speech
Deploying a service with conversation AI can seem daunting, but NVIDIA now has tools to make this process easier, including Neural Modules (NeMo for short), NVIDIA®TensorRT™, and a new technology called NVIDIA Riva. Several pretrained models in NGC are available for ASR, NLP, and TTS, such as BERT, Tacotron2, and WaveGlow. These models are trained on thousands of hours of open-source and proprietary data to get high accuracy, and are trained over 100K hours on NVIDIA DGX™ systems. GPU-accelerated Tacotron2 and Waveglow can perform inference 9X faster with an NVIDIA T4 GPU than CPU-only solutions.
NVIDIA NeMo is an open-source toolkit with a PyTorch backend that makes it possible for developers to quickly compose and train complex, state-of-the-art, neural network architectures with three lines of code. NeMo also comes with an extendable collection of models for ASR, NLP, and TTS. These collections provide methods to easily build state-of-the-art network architectures such as QuartzNet, BERT, Tacotron 2, and WaveGlow. With NeMo, you can also fine-tune these models on a custom dataset by automatically downloading and instantiating them from NVIDIA NGC with a readily available API.

NVIDIA Riva is an application framework that provides several pipelines for accomplishing conversational AI tasks. Generating high-quality, natural-sounding speech from text with low latency can be one of the most computationally challenging of those tasks. The Riva text-to-speech (TTS) pipeline enables conversational AIs to respond with natural sounding speech in as little time as possible, making for an engaging user experience.

NVIDIA GPU-Accelerated, End-to-End Data Science
The NVIDIA RAPIDS™suite of software libraries, built on CUDA-X AI™, gives you the freedom to execute end-to-end data science and analytics pipelines entirely on GPUs. It relies on NVIDIA CUDA® primitives for low-level compute optimization, but exposes that GPU parallelism and high-bandwidth memory speed through user-friendly Python interfaces.

NVIDIA GPU-Accelerated Deep Learning Frameworks
GPU-accelerated deep learning frameworks offer the flexibility to design and train custom deep neural networks and provide interfaces to commonly used programming languages like Python and C/C++. Widely used deep learning frameworks such as MXNet, PyTorch, TensorFlow, and others rely on NVIDIA GPU-accelerated libraries to deliver high-performance, multi-GPU accelerated training.

Next Steps
To learn more, refer to the blogs, code samples and Jupyter notebooks listed below:
- The NVIDIA Conversational AI and Conversational AI SDK web page
- Introducing Riva: Framework for GPU-Accelerated Conversational AI Applications
- Speeding Up Development of Speech and Language Models with NVIDIA NeMo
- Getting a Real-Time Factor Over 60 for Text-To-Speech Services Using NVIDIA Riva
- General Natural Sounding Speech from Text in Real-Time (Blog)
- How to Deploy Real-Time Text-to-Speech Applications on GPUs Using TensorRT (Blog)
- TTS NeMo Code Samples
- NVIDIA Tacotron2 Code Samples
- Creating Robust Neural Speech Synthesis with ForwardTacotron
- Empowering Smart Hospitals with NVIDIA Clara Guardian from NGC and NVIDIA Fleet Command
Find out more:
- GPU-accelerated data centers can deliver unprecedented performance with fewer servers, less floor space, and reduced power consumption. The NVIDIA GPU Cloud provides extensive software libraries at no cost, as well as tools for building high-performance computing environments that take full advantage of GPUs.
- The NVIDIA Deep Learning Institute offers instructor-led, hands-on training on the fundamental tools and techniques for building Transformer-based natural language processing models for text classification tasks like categorizing documents.