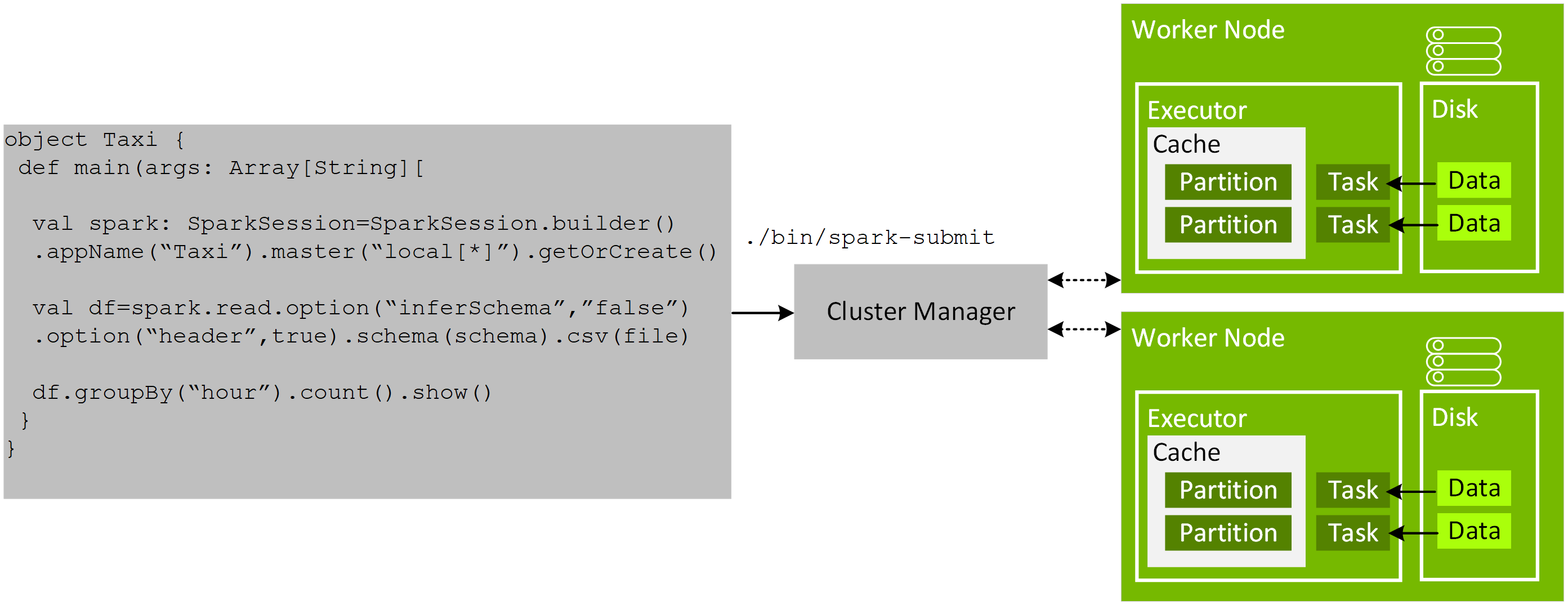
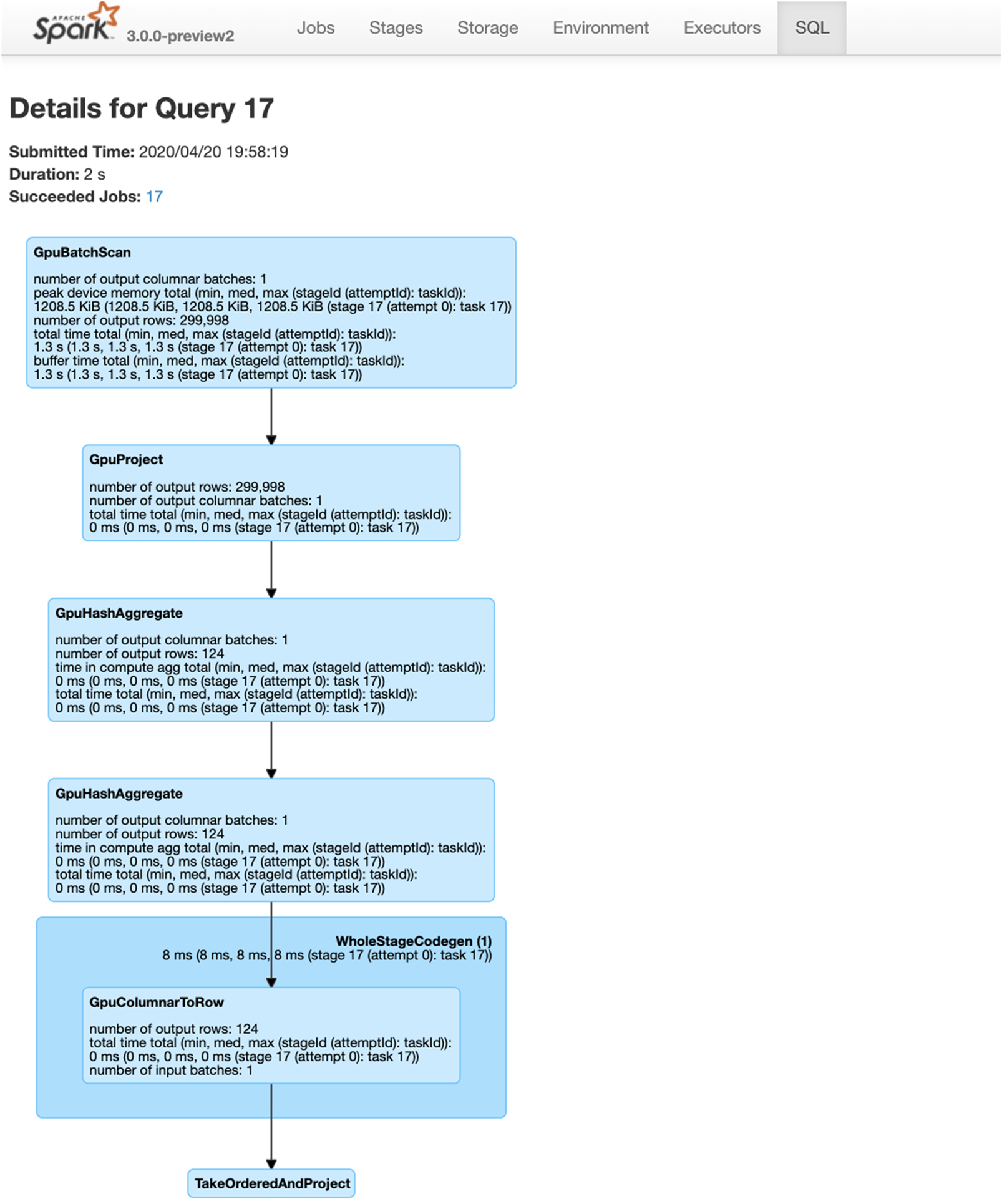
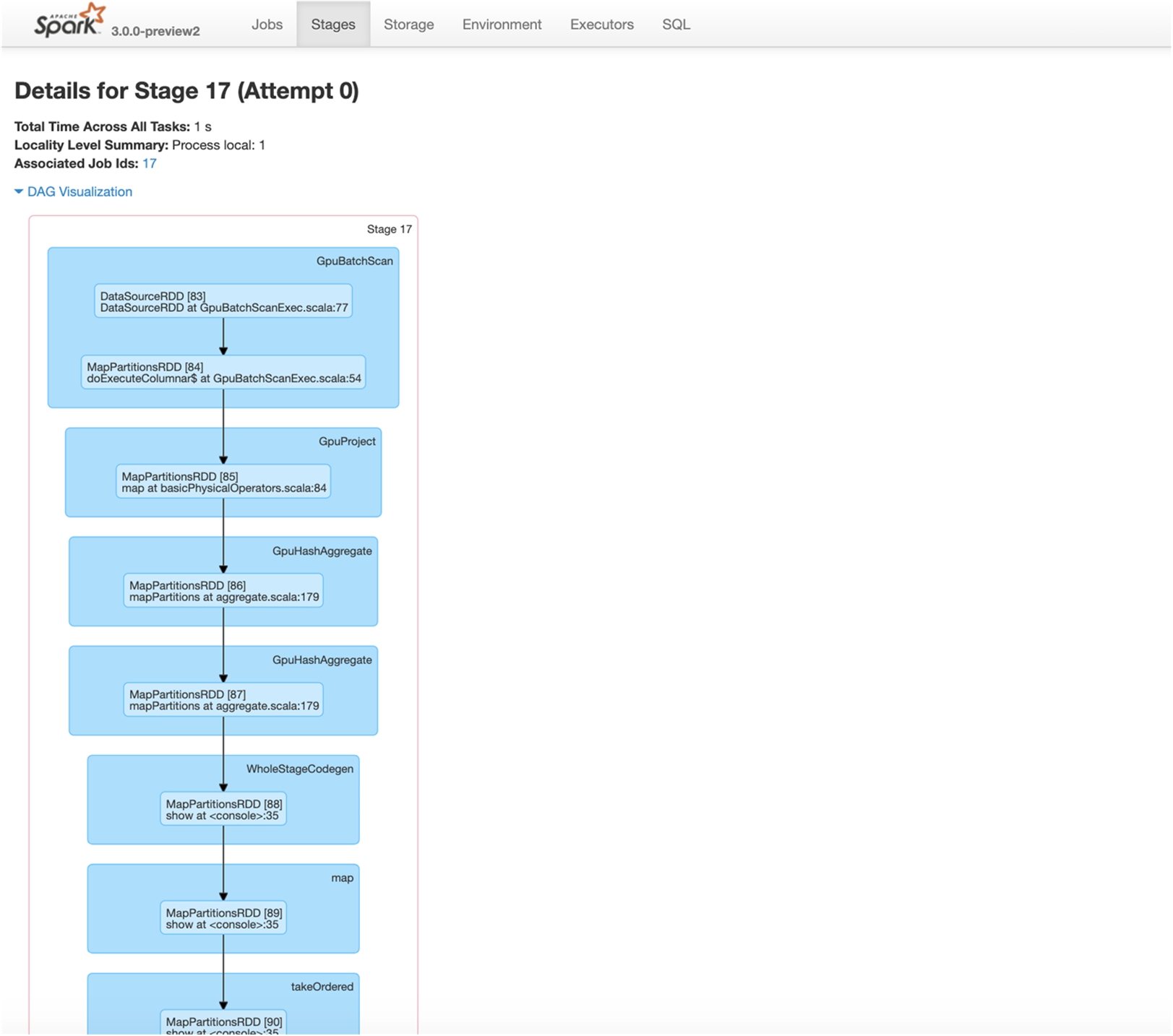
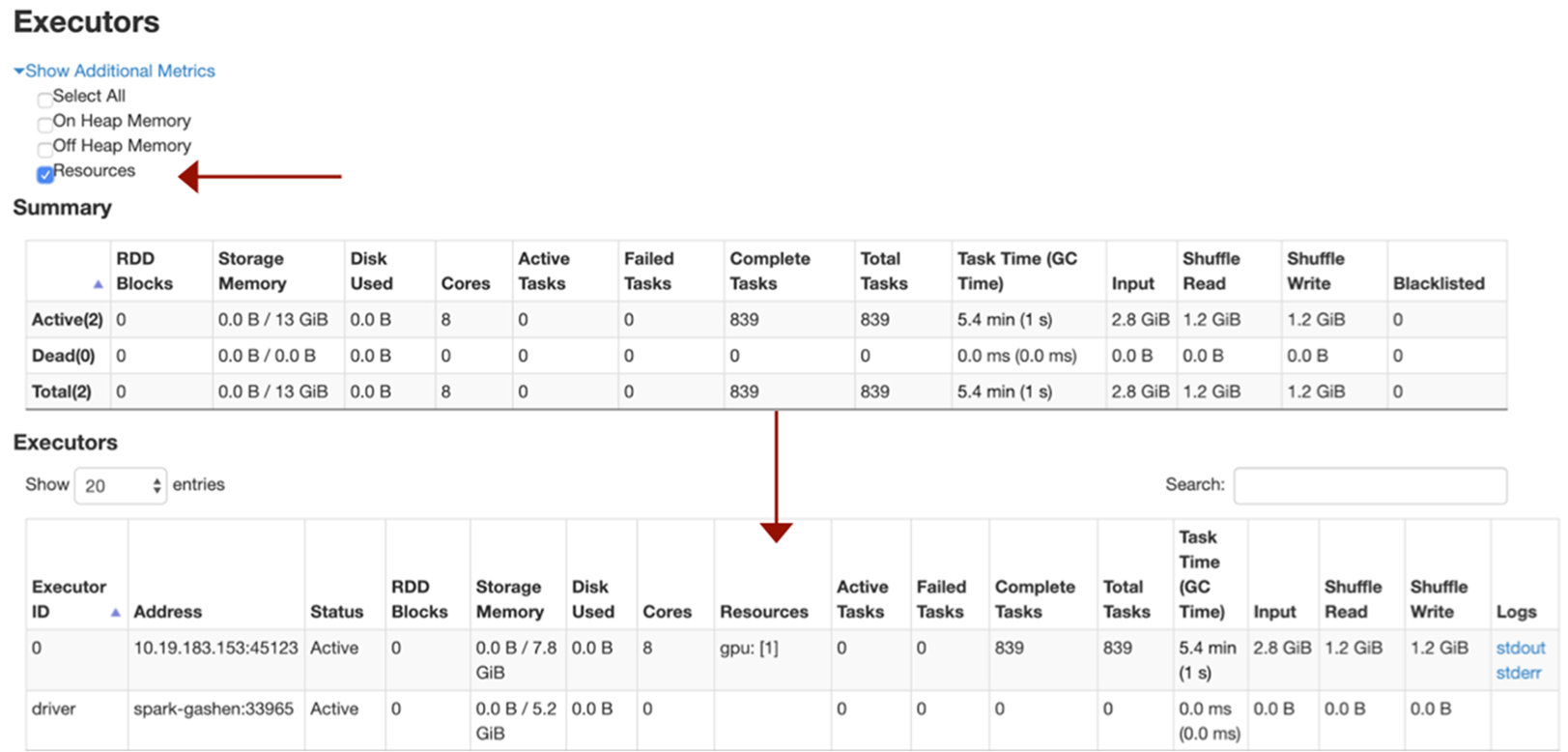
In Chapter 3, we discussed the features of GPU-Acceleration in Spark 3.x. In this chapter, we go over the basics of getting started using the new RAPIDS Accelerator for Apache Spark 3.x that leverages GPUs to accelerate processing via the RAPIDS libraries (For details refer to the Getting Started with the RAPIDS Accelerator for Apache Spark).
The RAPIDS Accelerator for Apache Spark has the following features and limitations:
- Allows running Spark SQL on a GPU with Columnar processing
- Requires no API changes from the user
- Handles transitioning from Row to Columnar and back
- Uses Rapids cuDF library
- Runs supported SQL operations on the GPU, If an operation is not implemented or not compatible with GPU, it will fall back to using the Spark CPU version.
- The plugin cannot accelerate operations that manipulate RDDs directly.
- The accelerator library also provides an implementation of Spark’s shuffle that can leverage UCX to optimize GPU data transfers keeping as much data on the GPU as possible and bypassing the CPU to do GPU to GPU transfers.
To enable this GPU acceleration, you will need:
- Apache Spark 3.0+
- A spark cluster configured with GPUs that comply with the requirements for the version of RAPIDS Dataframe library cuDF.
- One GPU per executor.
- Add the following jars:
- A cudf jar that corresponds to the version of CUDA available on your cluster.
- RAPIDS Spark accelerator plugin jar.
- Set the config spark.plugins to com.nvidia.spark.SQLPlugin