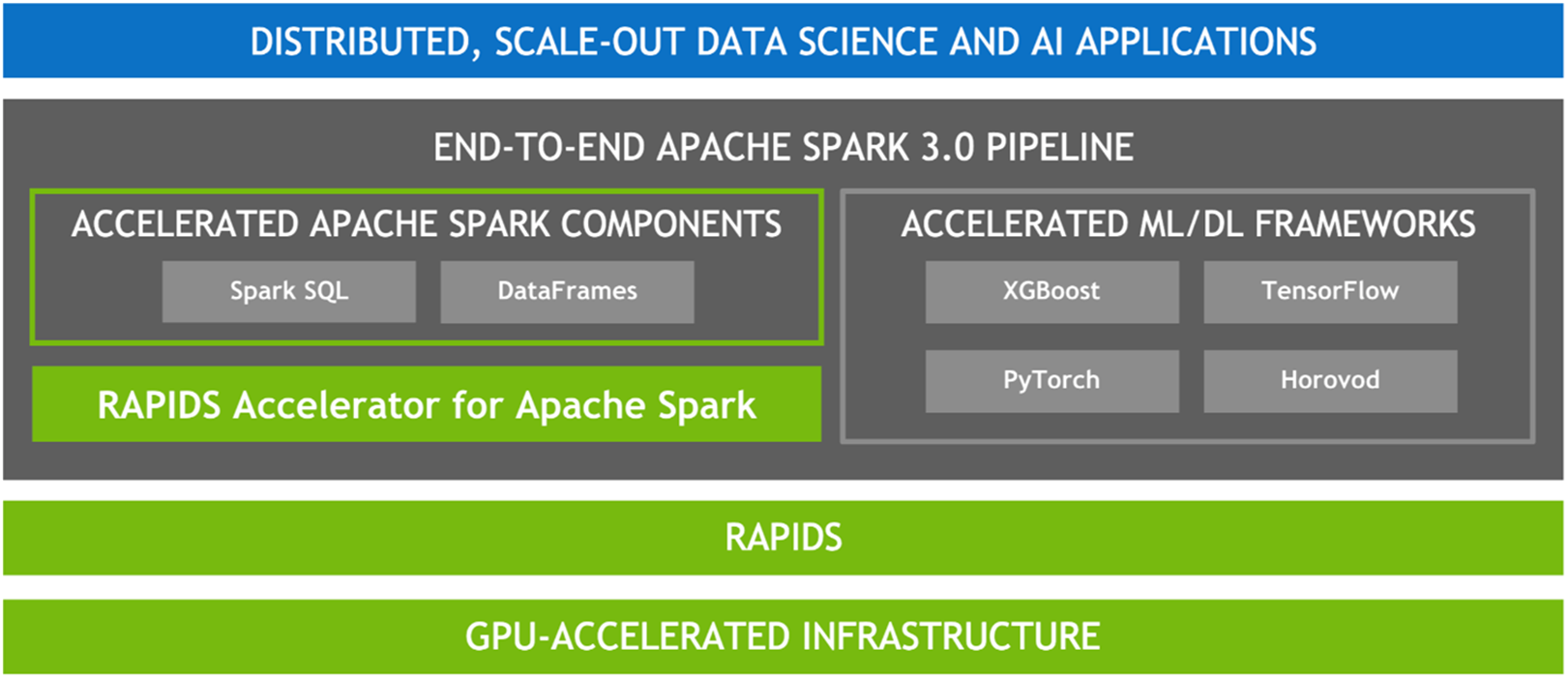
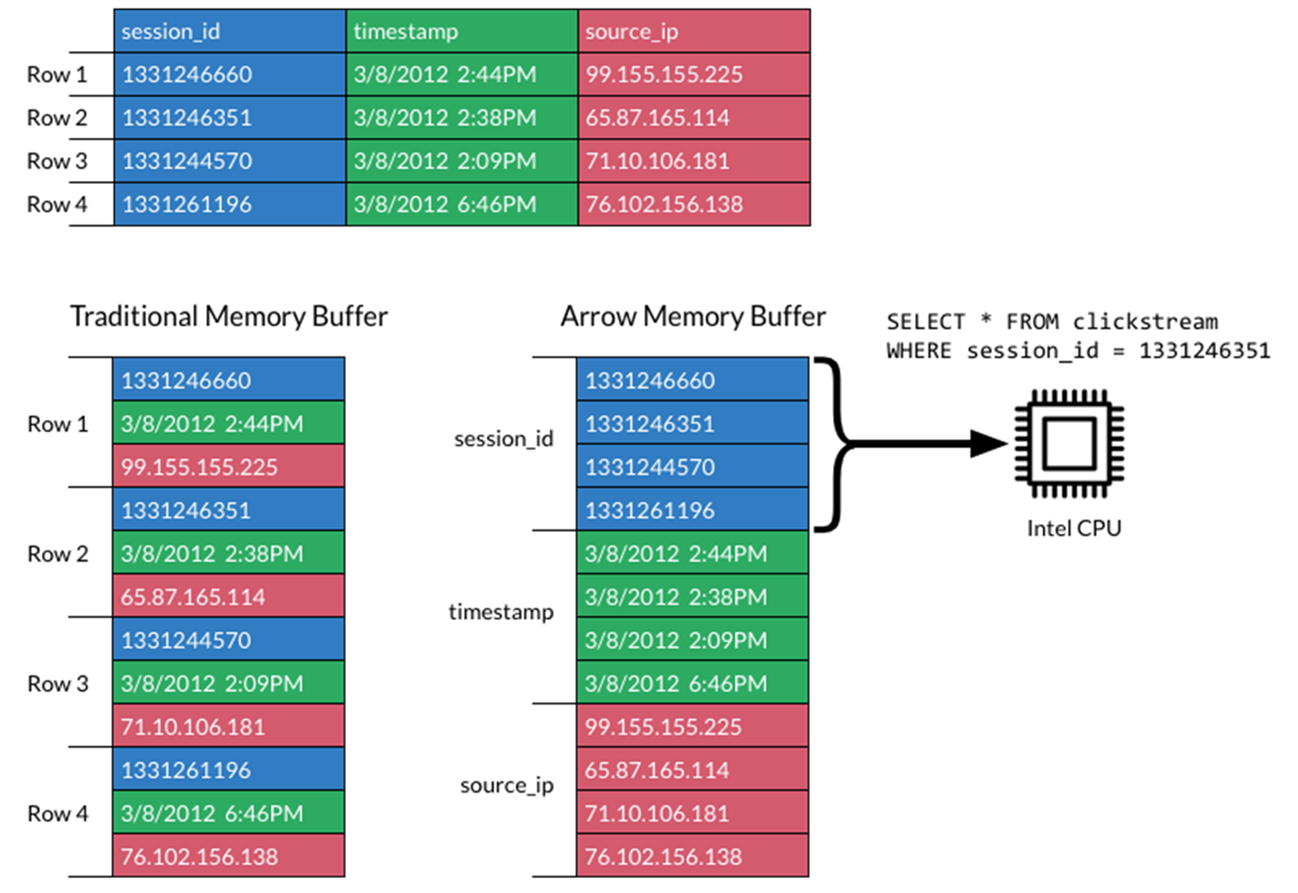
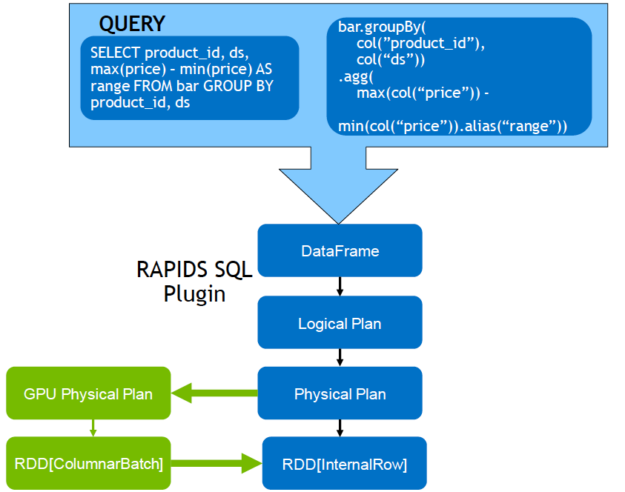
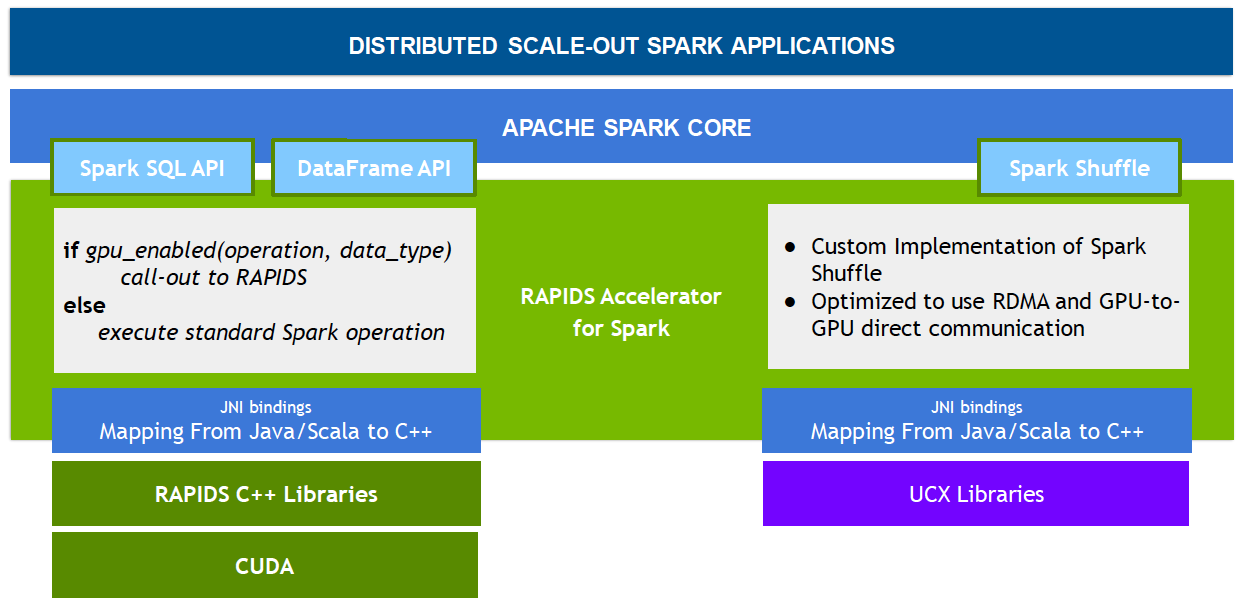
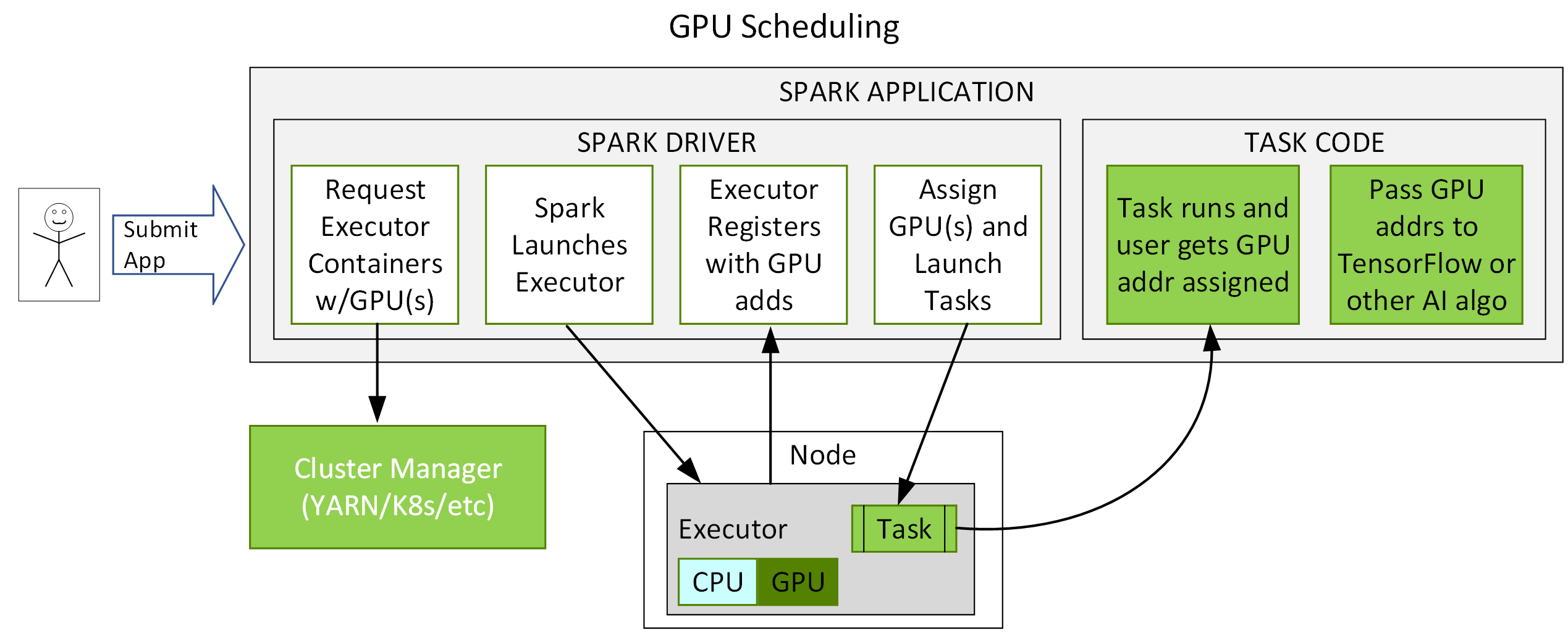
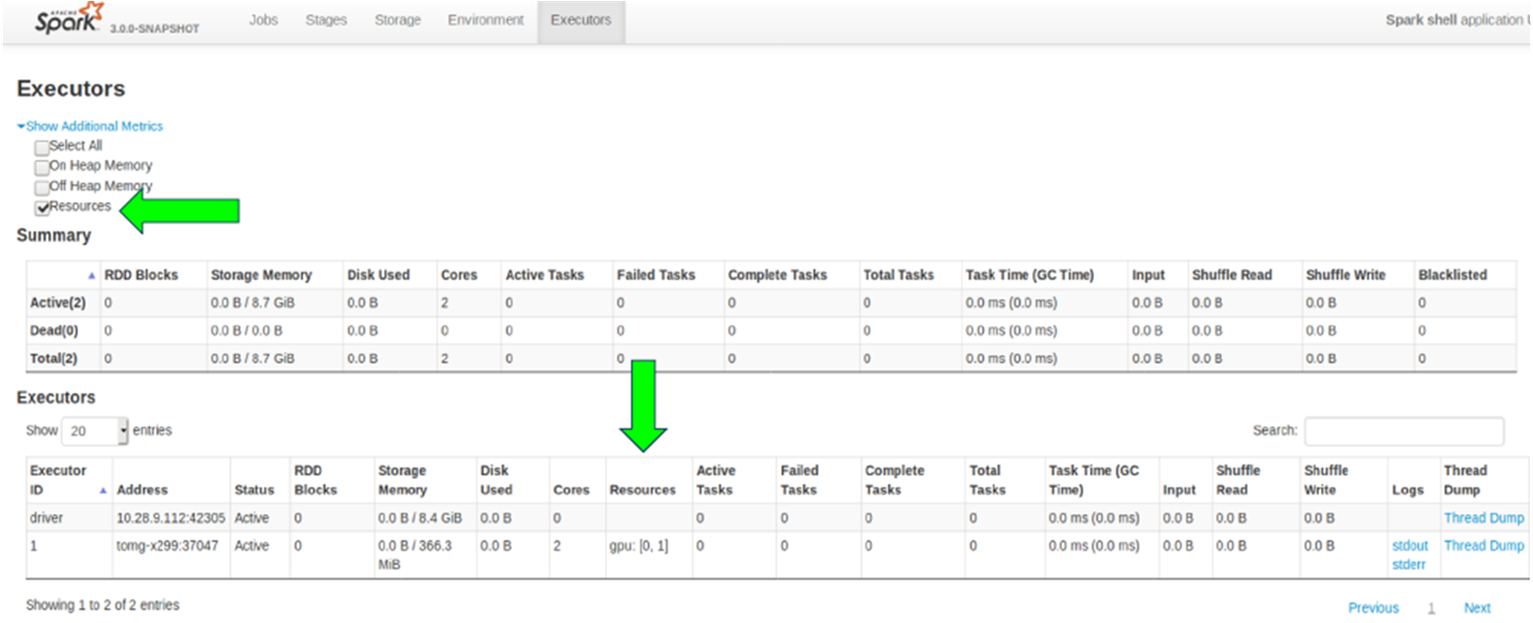
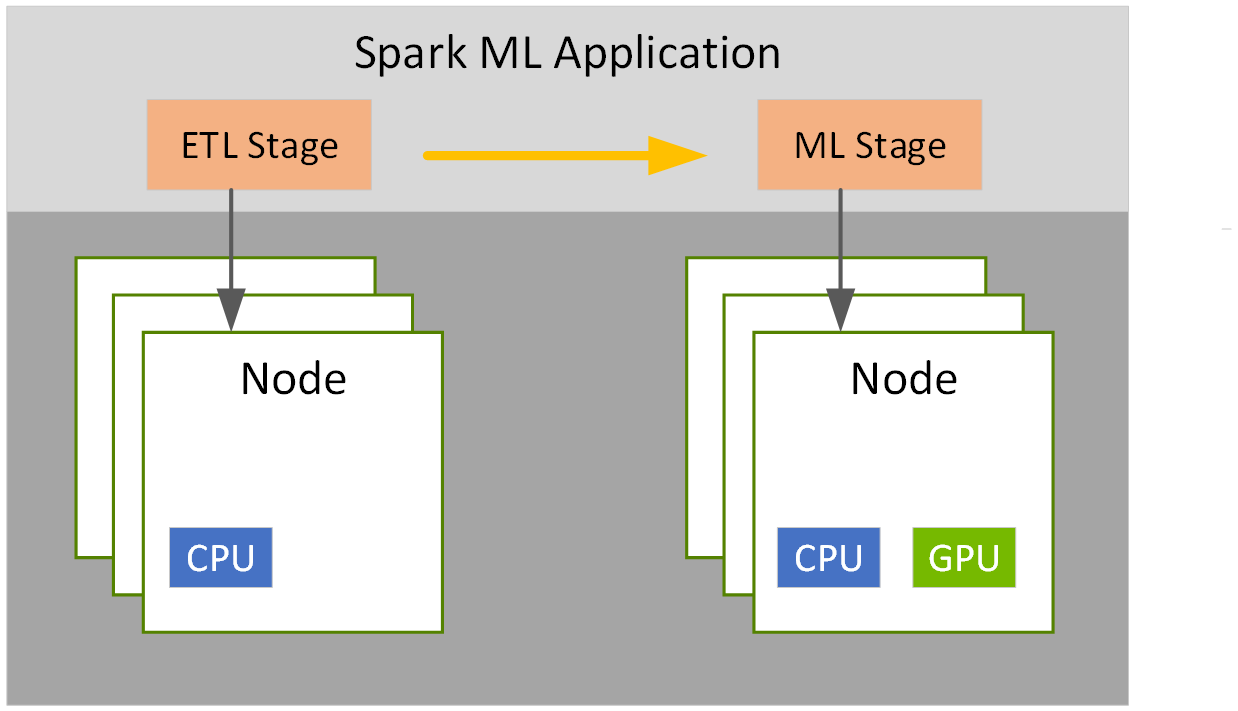
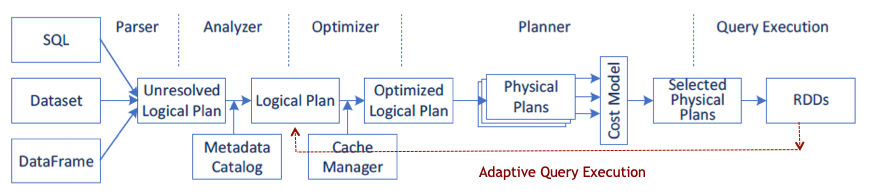
Given the parallel nature of many data processing tasks, it’s only natural that the massively parallel architecture of a GPU should be able to parallelize and accelerate Spark data processing queries, in the same way that a GPU accelerates deep learning (DL) in artificial intelligence (AI). Therefore, NVIDIA® has worked with the Spark community to implement GPU acceleration as part of Spark 3.x.
While Spark distributes computation across nodes in the form of partitions, within a partition, computation has historically been performed on CPU cores. However, the benefits of GPU acceleration in Spark are many. For one, fewer servers are required, reducing infrastructure cost. And, because queries are completed faster, you expect a reduction in time to results. Also, since GPU acceleration is transparent, applications built to run on Spark require no changes in order to reap the benefits of GPU acceleration.