A Spark DataFrame is a distributed Dataset of org.apache.spark.sql.Row objects, that are partitioned across multiple nodes in a cluster and can be operated on in parallel. A DataFrame represents a table of data with rows and columns, similar to a DataFrame in R or Python, but with Spark optimizations. A DataFrame consists of partitions, each of which is a range of rows in cache on a data node.
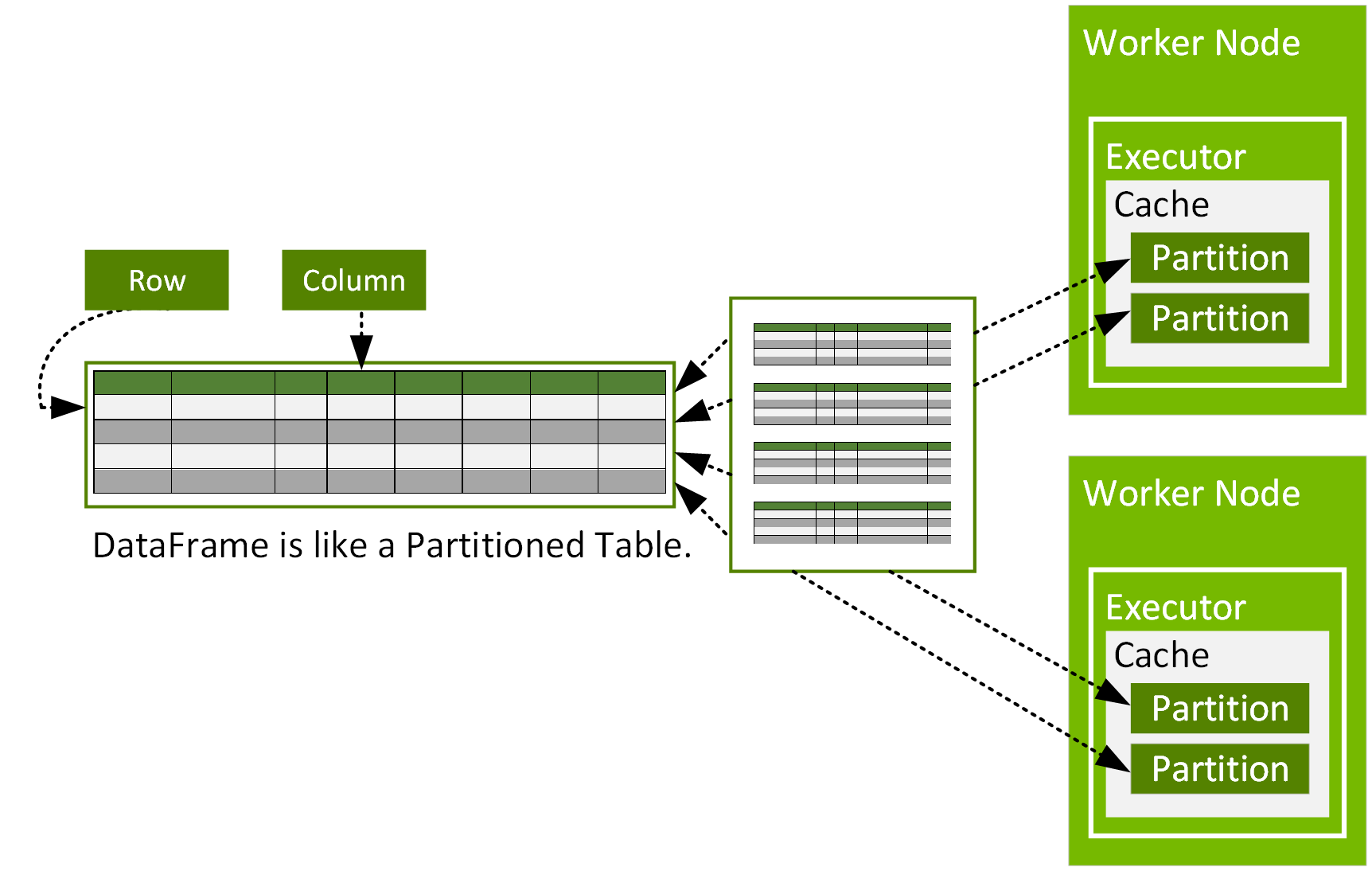
DataFrames can be constructed from data sources, such as csv, parquet, JSON files, Hive tables, or external databases. A DataFrame can be operated on using relational transformations and Spark SQL queries.
The Spark shell or Spark notebooks provide a simple way to use Spark interactively. You can start the shell in local mode with the following command:
$ /[installation path]/bin/spark-shell --master local[2]
You can then enter the code from the rest of this chapter into the shell to see the results interactively. In the code examples, the outputs from the shell are prefaced with the result.
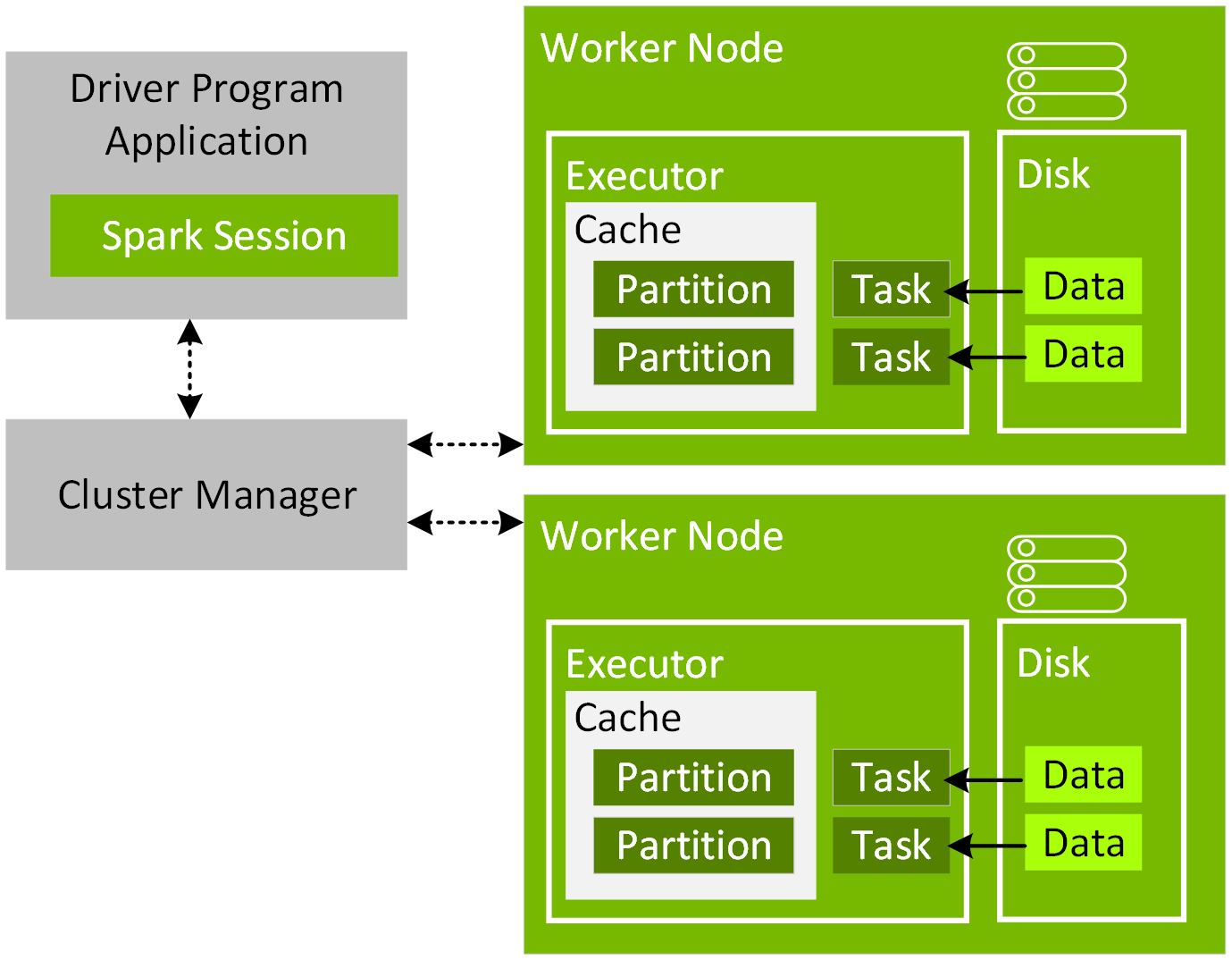
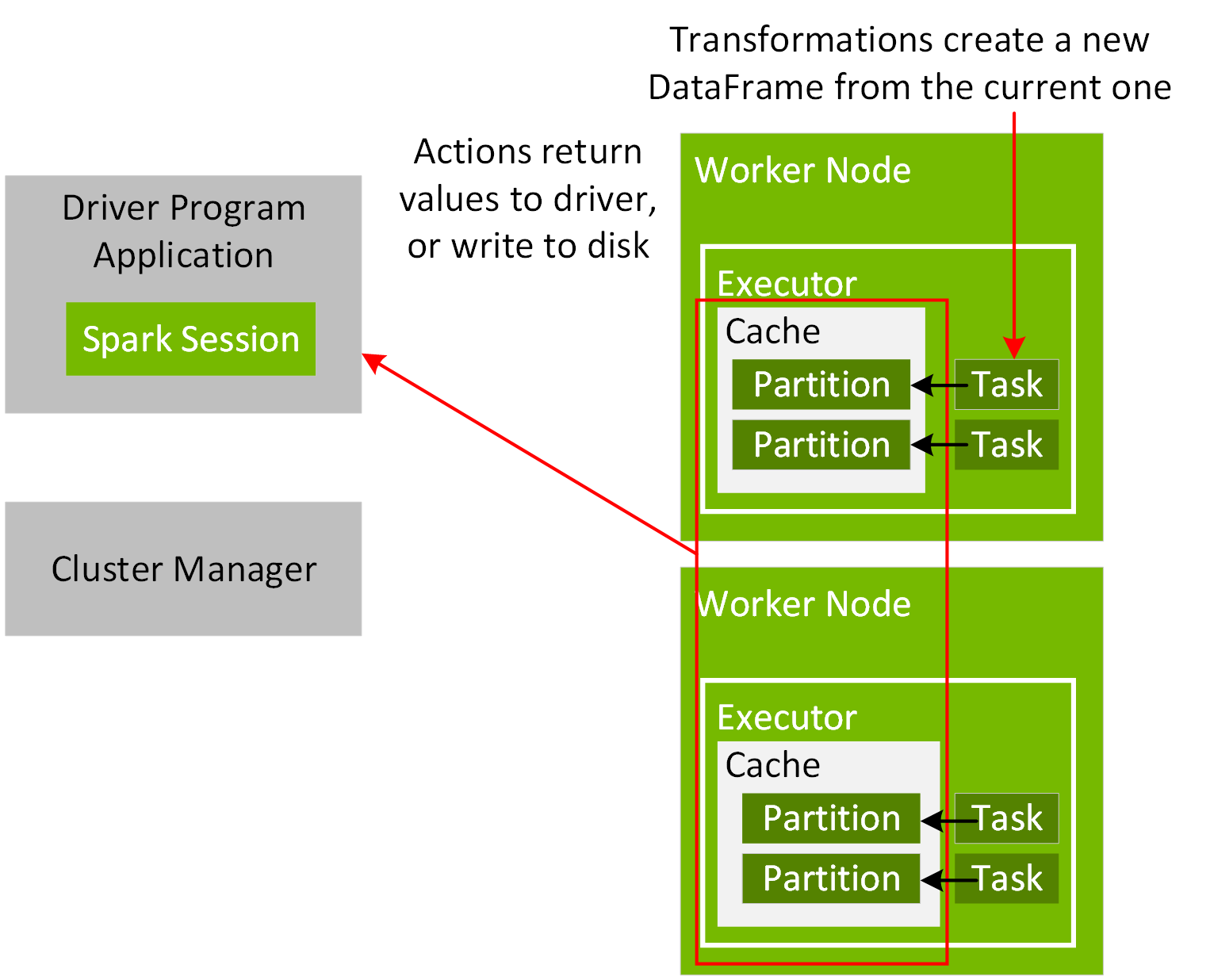
For execution coordination between your application driver and the Cluster manager, you create a SparkSession object in your program, as shown in the following code example:
val spark = SparkSession.builder.appName("Simple Application").master("local[2]").getOrCreate()
When a Spark application starts, it connects to the cluster manager via the master URL. The master URL can be set to the cluster manager or local[N] to run locally with N threads, when creating the SparkSession object or when submitting the Spark application. When using the spark-shell or notebook, the SparkSession object is already created and available as the variable spark. Once connected, the cluster manager allocates resources and launches executor processes, as configured for the nodes in your cluster. When a Spark application executes, the SparkSession sends tasks to the executors to run.
With the SparkSession read method, you can read data from a file into a DataFrame, specifying the file type, file path, and input options for the schema.
import org.apache.spark.sql.types._
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
val schema =
StructType(Array(
StructField("vendor_id", DoubleType),
StructField("passenger_count", DoubleType),
StructField("trip_distance", DoubleType),
StructField("pickup_longitude", DoubleType),
StructField("pickup_latitude", DoubleType),
StructField("rate_code", DoubleType),
StructField("store_and_fwd", DoubleType),
StructField("dropoff_longitude", DoubleType),
StructField("dropoff_latitude", DoubleType),
StructField("fare_amount", DoubleType),
StructField("hour", DoubleType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", DoubleType),
StructField("day_of_week", DoubleType),
StructField("is_weekend", DoubleType)
))
val file = "/data/taxi_small.csv"
val df = spark.read.option("inferSchema", "false")
.option("header", true).schema(schema).csv(file)
result:
df: org.apache.spark.sql.DataFrame = [vendor_id: double, passenger_count:
double ... 14 more fields]
The take method returns an array with objects from this DataFrame, which we see is of the org.apache.spark.sql.Row type.
df.take(1)
result:
Array[org.apache.spark.sql.Row] =
Array([4.52563162E8,5.0,2.72,-73.948132,40.829826999999995,-6.77418915E8,-1.0,-73.969648,40.797472000000006,11.5,10.0,2012,11,13.0,6.0,1.0])