
Intelligent Document Processing
Turn complex documents, reports, presentations, PDFs, web pages and spreadsheets into searchable intelligence.
Overview: Why Intelligent Document Processing
Read, Understand, and Extract Document Insights to Automate Decision Making
Intelligent document processing helps institutions turn diverse multimodal content—like reports, contracts, filings, policies, and research papers—into structured, searchable insights by identifying the most important information.
Document processing with NVIDIA Nemotron open models and libraries combines high-fidelity extraction, multimodal retrieval, and grounded generation. Teams can build AI agents that read documents like experts while preserving traceability back to the original source.
Benefits
These span several areas that help teams of analysts, researchers, and end users achieve better results.
- Faster Insight Discovery: Automate the review of dense reports, contracts, and policies so teams get answers in seconds rather than hours.
- Scalable Document Workloads: Process millions of PDFs, web pages, and spreadsheets in parallel as new data arrives, without linearly adding headcount.
- Higher Decision Quality: Preserve tables, charts, and figures so AI agents reason over the same evidence experts trust today.
- Auditability and Compliance: Ground every answer in cited pages and tables to meet stringent regulatory and internal audit requirements.
- Cross-Industry Impact: Support diverse workflows across finance, legal and scientific domains, with an intelligent pipeline that adapts to different document types and domains.
Quick Links
Edison Scientific: Kosmos AI Scientist Synthesizes Tens of Thousands of Research Papers
Edison Scientific, a spinout of FutureHouse, is building Kosmos, an AI scientist capable of autonomous discovery. Kosmos is a multi-agent system with a specialized Literature agent designed to answer questions about scientific literature, clinical trials, and patents. Powered by Nemotron Parse, the Literature agent autonomously searches over 175 million documents to answer questions from researchers—helping more than 50,000 scientists with their discovery work.
For each page, Nemotron Parse returns semantic text for embedding and search, then segments the visual image regions for multimodal LLM reasoning.
Scientific papers are not written to a common standard and often include complex figures that can be misinterpreted. Nemotron Parse is critical to identifying relevant tables, figures, and text in a PDF that an LLM can then reason over and generate responses to user queries.
Edison’s Literature agent helps:
- Reduce manual work by understanding large volumes of data
- Speed analysis by extracting key details
- Improve the quality of decisions both tools and humans make
Understanding scientific literature quickly and accurately is a critical component that enabled Kosmos to complete 6 months of research in a day, with 80% reproducibility.
Quick Links
Technical Implementation
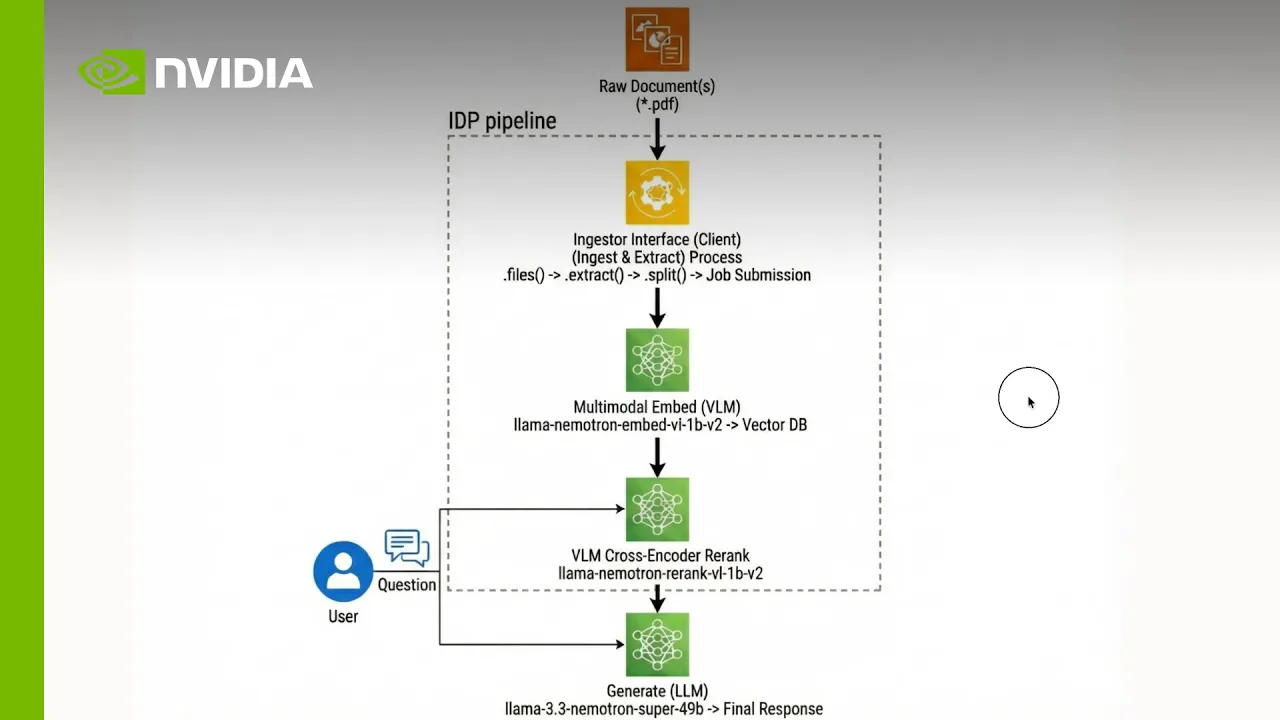
Architecture Diagram

An intelligent document processing pipeline is built around three core components: extraction, embedding and indexing, and reranking for answer generation.
Developers can configure, extend, and deploy with open models, NeMo Retriever, and NIM microservices.
1. Extraction: Turn complex documents into structured data
Use the NeMo Retriever library with self-hosted or NVIDIA-hosted parsing and OCR services to ingest PDFs, web pages, and other multimodal documents and convert them into structured units such as text chunks, markdown tables, and chart crops while preserving layout and semantics. This stage “unlocks” rich content by keeping tables as tables and figures as images, producing JSON outputs that downstream retrieval and generation models can reliably consume.
2. Embedding and indexing: Make content searchable at scale
Feed extracted items into Nemotron multimodal embedding models to encode text, tables and charts into dense vectors tailored for document retrieval. Store these vectors and associated metadata in a vector database such as Milvus, enabling millisecond semantic search over millions of document elements and keeping your knowledge base continuously up to date as new content arrives.
3. Reranking and grounded answer generation: Deliver cited, high-fidelity answers
Retrieve top‑K candidates from the vector index and apply Nemotron cross‑encoder reranking to prioritize the passages, tables, and figures that best answer a user’s question. Pass this reranked context into a Nemotron generation model, which produces grounded responses with explicit citations back to the original pages and charts so business, financial, and scientific teams can trust and audit every decision the system supports.
Code walkthrough on building an intelligent document processing pipeline using open Nemotron technologies
Quick Links
Partner Ecosystem
Quick Links
FAQs
A production-grade NVIDIA RAG pipeline includes a vector database and containerized NIM microservices or Kubernetes-based deployment to scale extraction, embedding, and retrieval across large document volumes. For self-hosted deployments, choose NVIDIA GPUs with sufficient VRAM; alternatively, hosted endpoints can reduce local infrastructure requirements. You’ll also want to tune extraction settings (such as table output format and page-level splitting), choose appropriate Nemotron extraction, embedding, and reranking models, and instrument the system to measure throughput, latency, and citation quality to meet enterprise SLAs.
Nemotron Parse uses a vision-language architecture with spatial grounding to detect and extract text, tables, charts, and layout elements, producing structured, machine-readable outputs rather than flat text. It preserves table structure, reading order, and semantic classes, significantly improving accuracy on challenging benchmarks and making downstream retrieval and reasoning over PDFs, scans, and complex reports far more reliable. These structured outputs can also support more semantic chunking, helping retrieval systems split documents along meaningful content boundaries rather than arbitrary text windows.
Answer: In a RAG pipeline, the extraction stage shapes the quality and structure of the evidence available for retrieval. Use PDFium for digitally created PDFs when throughput is the priority, OCR when you want visual extraction with a strong balance of speed and accuracy, and Nemotron Parse when richer layout and document structure improve chunking and retrieval quality. In NeMo Retriever, choosing the OCR extraction path routes document extraction through the NeMo Retriever OCR service.
In short: PDFium is best for digitally created PDFs, OCR balances speed and visual extraction, and Nemotron Parse prioritizes layout fidelity and semantic structure.
Quick Links