
Procesamiento Inteligente de Documentos
Convierta documentos, informes, presentaciones, archivos PDF, páginas web y hojas de cálculo complejos en inteligencia con capacidad de búsqueda.
Descripción General: Por Qué el Procesamiento Inteligente de Documentos
Lea, Comprenda y Extraiga Información de Documentos para Automatizar la Toma de Decisiones
El procesamiento inteligente de documentos ayuda a las instituciones a convertir contenido multimodal diverso (como informes, contratos, presentaciones, políticas y documentos de investigación) en información estructurada y que se pueda buscar, al identificar la información más importante.
El procesamiento de documentos con modelos y bibliotecas abiertos NVIDIA Nemotron combina extracción de alta fidelidad, recuperación multimodal y generación fundamentada. Los equipos pueden desarrollar agentes de IA que lean documentos como expertos, preservando la trazabilidad hasta la fuente original.
Beneficios
Estos abarcan varias áreas que ayudan a los equipos de analistas, investigadores y usuarios finales a lograr mejores resultados.
- Descubrimiento de Información más Rápido: Automatice la revisión de informes, contratos y políticas extensos para que los equipos obtengan respuestas en segundos en lugar de horas.
- Cargas de Trabajo de Documentos Escalables: Procese millones de archivos PDF, páginas web y hojas de cálculo en paralelo a medida que llegan los nuevos datos, sin agregar linealmente una cantidad de personal.
- Mayor Calidad de Decisiones: Preserve tablas, gráficos y figuras para que los agentes de IA razonen sobre la misma evidencia en la que los expertos confían en la actualidad.
- Auditabilidad y Cumplimiento: Base cada respuesta en las páginas y tablas citadas para cumplir con estrictos requisitos regulatorios y de auditoría interna.
- Impacto en Toda la Industria: Admita diversos flujos de trabajo en los dominios financiero, legal y científico, con un pipeline inteligente que se adapta a diferentes tipos de documentos y dominios.
Enlaces Rápidos
Edison Scientific: Científico de IA de Kosmos Sintetiza Decenas de Miles de Documentos de investigación
Edison Scientific, un spinout de FutureHouse, está desarrollando Kosmos, un científico de IA capaz de hacer un descubrimiento autónomo. Kosmos es un sistema de múltiples agentes con un agente de Literatura especializado diseñado para responder preguntas sobre literatura científica, ensayos clínicos y patentes. El agente de Literatura, que funciona con Nemotron Parse, busca de forma autónoma en más de 175 millones de documentos para responder a las preguntas de los investigadores, lo que ayuda a más de 50,000 científicos en su trabajo de descubrimiento.
Para cada página, Nemotron Parse devuelve texto semántico para la incrustación y la búsqueda, y luego segmenta las regiones de imágenes visuales para el razonamiento de LLM multimodal.
Los artículos científicos no se escriben con un estándar común y, a menudo, incluyen figuras complejas que se pueden interpretar mal. Nemotron Parse es crítico para identificar tablas, figuras y texto relevantes en un PDF sobre los que un LLM pueda razonar y generar respuestas a las consultas de los usuarios.
El agente de Literatura de Edison ayuda a:
- Reducir el trabajo manual al comprender grandes volúmenes de datos
- Acelerar el análisis mediante la extracción de información clave
- Mejorar la calidad de las decisiones que toman las herramientas y los humanos
La comprensión de la literatura científica de forma rápida y precisa es un componente crítico que permitió a Kosmos completar 6 meses de investigación en un día, con una reproducibilidad del 80 %.
Enlaces Rápidos
Implementación Técnica
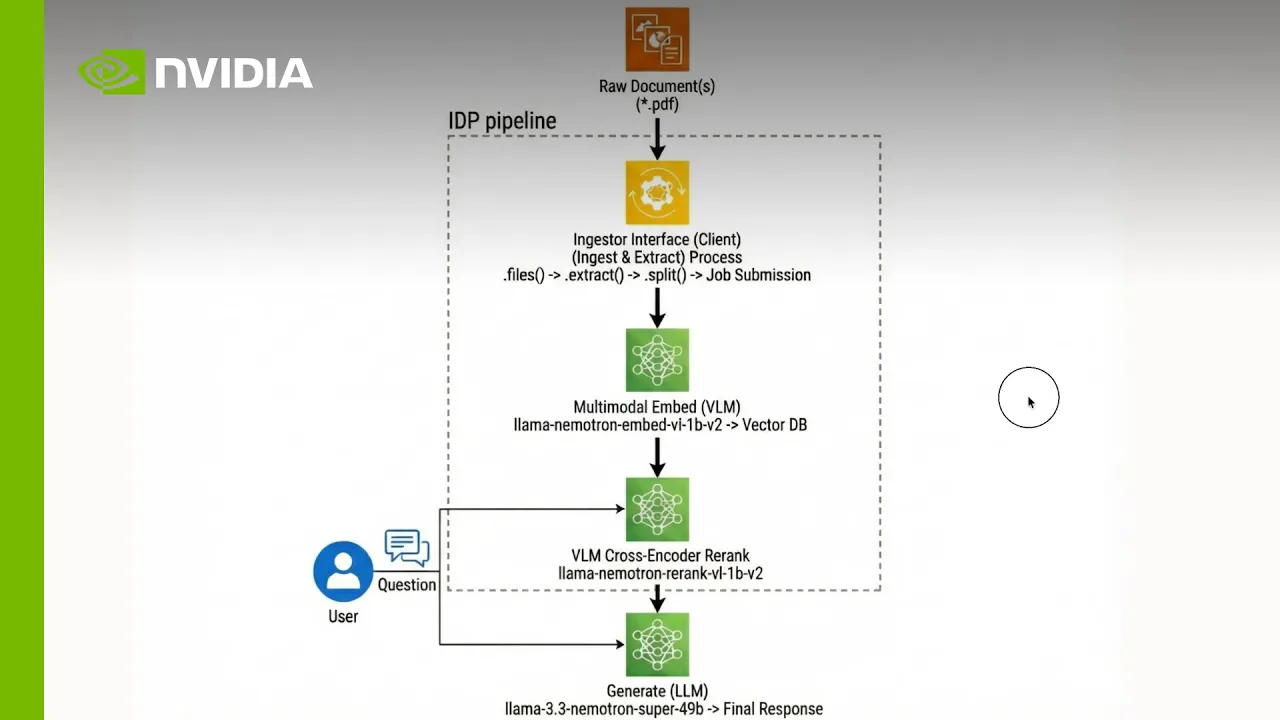
Diagrama de Arquitectura

Un pipeline inteligente de procesamiento de documentos se desarrolla en torno a tres componentes centrales: extracción, embedding e indexación, y reclasificación para la generación de respuestas.
Los desarrolladores pueden configurar, extender e implementar con modelos abiertos, NeMo Retriever y microservicios NIM.
1. Extracción: Convierta documentos complejos en datos estructurados
Use la biblioteca NeMo Retriever con servicios de análisis y OCR alojados por usted mismo o por NVIDIA para ingerir archivos PDF, páginas web y otros documentos multimodales, y convierta los archivos en unidades estructuradas, como fragmentos de texto, tablas de markdown y recortes de gráficos, a la vez que se preserva el diseño y la semántica. Esta etapa "desbloquea" contenido enriquecido manteniendo las tablas como tablas y las figuras como imágenes, lo que produce resultados en formato JSON que los modelos posteriores de recuperación y generación pueden consumir de forma confiable.
2. Incrustación e indexación: Hacer que el contenido se pueda buscar a escala
Incorpore elementos extraídos a modelos de incrustación multimodal Nemotron para codificar texto, tablas y gráficos en vectores densos adaptados para la recuperación de documentos. Almacene estos vectores y metadatos asociados en una base de datos vectorial como Milvus, lo que permite la búsqueda semántica en milisegundos en millones de elementos de documentos y mantiene su base de conocimiento continuamente actualizada a medida que llega nuevo contenido.
3. Reclasificación y generación de respuestas fundamentadas: Ofrecer respuestas citadas y de alta fidelidad
Recupere los candidatos top-k del índice vectorial y aplique la reclasificación de codificadores cruzados Nemotron para priorizar los pasajes, las tablas y figuras que mejor respondan a la pregunta de un usuario. Pase este contexto reclasificado a un modelo de generación Nemotron, que produce respuestas fundamentadas con citas explícitas a las páginas y gráficos originales para que los equipos empresariales, financieros y científicos puedan confiar en cada decisión que admite el sistema y auditar dicha decisión.
Recorrido de código para el desarrollo de un pipeline inteligente de procesamiento de documentos mediante tecnologías Nemotron abiertas
Enlaces Rápidos
Ecosistema de Socios
Enlaces Rápidos
Preguntas Frecuentes
Un pipeline de NVIDIA RAG de nivel de producción incluye una base de datos vectorial y microservicios NIM en contenedores o una implementación basada en Kubernetes para escalar la extracción, la incrustación y la recuperación en grandes volúmenes de documentos. Para implementaciones autoalojadas, elija las GPU de NVIDIA con suficiente VRAM; como alternativa, los puntos finales alojados pueden reducir los requisitos de infraestructura local. También es recomendable que ajuste la configuración de extracción (como el formato de salida de la tabla y la división a nivel de página), elegir modelos apropiados de extracción, incrustación y reclasificación de Nemotron, e instrumentar el sistema para medir el rendimiento, la latencia y la calidad de las citas a fin de cumplir con los acuerdos de nivel de servicio (SLA) empresariales.
Nemotron Parse usa una arquitectura de lenguaje de visión con anclaje espacial para detectar y extraer texto, tablas, gráficos y elementos de diseño, lo que produce resultados estructurados y legibles por máquina, en lugar de texto plano. Preserva la estructura de la tabla, el orden de lectura y las clases semánticas, lo que mejora significativamente la precisión en puntos de referencia desafiantes y hace que la recuperación posterior y el razonamiento sobre archivos PDF, escaneos e informes complejos sean mucho más confiables. Estos resultados estructurados también pueden admitir una división más semántica, lo que ayuda a los sistemas de recuperación a dividir documentos a lo largo de límites de contenido significativos, en lugar de ventanas de texto arbitrarias.
Respuesta: En un pipeline de RAG, la etapa de extracción da forma a la calidad y la estructura de la evidencia disponible para la recuperación. Use PDFium para archivos PDF creados digitalmente cuando el rendimiento sea la prioridad, OCR cuando desee la extracción visual con un buen equilibrio entre velocidad y precisión, y Nemotron Parse cuando un diseño más rico y la estructura de documentos mejoren la división y la calidad de la recuperación. En NeMo Retriever, la elección de la ruta de extracción de OCR enruta la extracción de documentos a través del servicio de OCR NeMo Retriever.
En resumen: PDFium es mejor para archivos PDF creados digitalmente, el OCR equilibra la velocidad y la extracción visual, y Nemotron Parse prioriza la fidelidad del diseño y la estructura semántica.
Enlaces Rápidos