넘파이는 n차원 배열(텐서라고도 함) 처리 및 수치 컴퓨팅을 위한 무료 오픈 소스 파이썬(Python) 라이브러리입니다.
넘파이(NumPy)
넘파이란?
넘파이는 파이썬 프로그래밍 언어를 위한 강력하고 최적화된 무료 오픈 소스 라이브러리로, 대규모 다차원 배열(행렬 또는 텐서라고도 함)을 지원합니다. 넘파이는 이러한 배열과 함께 사용할 수 있는 고수준 수학 함수 모음 또한 갖추고 있습니다. 여기에는 기본적인 선형대수, 랜덤 시뮬레이션, 푸리에 변환, 삼각함수 연산, 통계 연산이 포함됩니다.
넘파이는 ‘Numerical Python’의 줄임말로, 파이썬에 빠른 수치 연산을 제공하는 것을 목표로 Numeric 및 Numarray 라이브러리의 초기 작업을 기반으로 구축되었습니다. 오늘날 넘파이에는 수많은 기여자가 있으며 NumFOCUS가 후원합니다.
과학 컴퓨팅의 핵심 라이브러리인 넘파이는 Pandas, Scikit-learn, SciPy와 같은 라이브러리의 기반입니다. 대규모 배열에서 최적화된 수학 연산을 수행하는 데 널리 사용됩니다.
넘파이를 사용하는 이유와 작동 방식
다차원 배열은 넘파이 라이브러리의 핵심 데이터 구조로, 일반적으로 값 그리드를 나타냅니다. 넘파이의 ndarray는 동종의 n차원 배열 객체로, 비슷한 데이터 타입의 요소 또는 항목 모음을 설명합니다. 이러한 ndarray에서 각 항목은 동일한 크기의 메모리 블록을 구성하며 각 블록은 동일한 방식으로 식별됩니다. 이를 통해 과학 컴퓨팅을 위한 데이터를 효율적이고 빠르고 쉽게 조작할 수 있습니다.
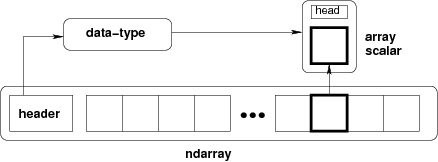
넘파이 배열은 비슷한 데이터 타입의 모음이고 메모리에 밀집되어 배치되기 때문에 넘파이 배열 연산은 파이썬 리스트보다 빠르게 수행됩니다. 반면, 파이썬 리스트는 다양한 데이터 타입을 가질 수 있으므로 연산을 수행하는 동안 시스템에 추가적인 제약을 줍니다.
넘파이의 이점
넘파이의 중요한 이점과 특성은 다음과 같습니다:
- 넘파이의 ndarray 컴퓨팅 개념은 Scientific Python 및 PyData 에코시스템의 핵심입니다.
- 넘파이는 고도로 최적화된 C 함수를 위한 파이썬 프론트엔드를 제공하여 컴파일된 코드의 속도로 간단한 파이썬 인터페이스를 사용할 수 있도록 합니다.
- 넘파이의 강력한 N차원 배열 객체는 다양한 라이브러리와 통합됩니다.
- 넘파이 배열은 파이썬의 내장 리스트를 사용할 때보다 더 효율적으로 그리고 더 적은 코드로 대규모 데이터 세트에 고급 수학 연산을 실행할 수 있습니다. 이는 크기와 속도가 필수적인 과학 컴퓨팅 시퀀스에 매우 중요합니다.
넘파이가 중요한 이유
넘파이는 탐색적 데이터 분석(Exploratory Data Analysis)을 위한 효율적인 코드를 빠르게 구현하고 모델을 구축하는 데 필요한 파이썬 사용성과 C 수준 최적화를 결합하여 데이터 사이언티스트에게 제공합니다. 이러한 조합은 오늘날 과학 컴퓨팅에서 성공하기 위해필요한 알고리즘의 빠른 프로토타이핑을 위해 필수적입니다. 이로 인해 넘파이는 파이썬에서 다차원 데이터를 다루는 사실상의 표준 방식이 되었습니다.
파이썬을 통한 GPU 가속 컴퓨팅
구조적으로 볼 때, CPU는 단 몇 개의 코어와 많은 캐시 메모리로 구성되어 있어 한 번에 처리할 수 있는 소프트웨어 스레드가 적습니다. 반대로 GPU는 수백 개의 코어로 구성되어 있어 수천 개의 스레드를 동시에 처리할 수 있습니다.

넘파이는 파이썬에서 다차원 데이터를 다루는 사실상의 표준방식이 되었습니다. 그러나 이 구현은 멀티 코어 GPU에 최적이지 않습니다. 이러한 이유로 GPU에 최적화된 최신 라이브러리들이 넘파이 배열을 구현하거나 상호 운용됩니다.
NVIDIA® CUDA®는 GPU 기반 일반 컴퓨팅을 위해 NVIDIA가 개발한 병렬 컴퓨팅 플랫폼 및 프로그래밍 모델입니다. CUDA 배열 인터페이스는 데이터를 복사하거나 변환할 필요 없이 서로 다른 라이브러리 간에 GPU 배열을 공유할 수 있도록 GPU 배열(텐서)을 설명하는 표준 형식입니다. CUDA 배열은 Numba, CuPy, MXNet 및 파이토치에서 지원됩니다.
- CuPy는 CUDA GPU 라이브러리를 활용하여 NVIDIA GPU에 넘파이 배열을 구현하는 라이브러리입니다.
- Numba는 CUDA 지원 GPU에서 실행하기 위해 파이썬 코드를 컴파일할 수 있는 파이썬 컴파일러입니다. 넘파이 배열은 Numba에서 바로 지원됩니다.
- Apache MXNet은 유연하고 효율적인 딥 러닝용 라이브러리입니다. NDArray는 모델의 입력과 출력을 다차원 배열로 표현하고 조작하는 데 사용됩니다. NDArray는 넘파이의 ndarray와 유사하지만, GPU에서 실행하여 컴퓨팅을 가속화할 수 있습니다.
- 파이토치는 유연성과 사용 편의성으로 유명한 오픈 소스 딥 러닝 프레임워크입니다. 파이토치 텐서는 넘파이의 ndarray와 유사하지만, GPU에서 실행하여 컴퓨팅을 가속화할 수 있다는 점이 다릅니다.
NVIDIA GPU 가속 엔드투엔드 데이터 사이언스
CUDA 기반 오픈 소스 소프트웨어 라이브러리인 NVIDIA RAPIDS™ 제품군은 엔드투엔드 데이터 사이언스 및 분석 파이프라인을 전적으로 GPU에서 실행할 수 있는 기능을 제공합니다. NVIDIA CUDA 프리미티브를 사용하여 저수준의 컴퓨팅 최적화를 수행하지만, 사용자에게 친숙한 파이썬 인터페이스를 통해 GPU 병렬 처리와 고대역폭 메모리 속도를 활용할 수 있도록 합니다.
RAPIDS GPU DataFrame을 사용하면 Pandas와 같은 인터페이스를 사용하여 데이터를 GPU에 로드한 다음, GPU를 벗어나지 않고도 데이터를 연결된 다양한 머신 러닝 및 그래프 분석 알고리즘에 사용할 수 있습니다. Apache Arrow와 같은 라이브러리를 통해 이러한 수준의 상호 운용이 가능합니다. 넘파이 배열, Pandas 데이터프레임, PyArrow 테이블에서 코드 한 줄만으로 GPU 데이터프레임을 생성할 수 있습니다. 다른 프로젝트들은 CUDA 배열 인터페이스를 사용하여 데이터를 교환할 수 있습니다. 이를 통해 데이터 준비부터 머신 러닝과 딥 러닝에 이르는 엔드투엔드 파이프라인을 가속화가 가능해집니다..

RAPIDS는 많이 사용되는 여러 데이터 사이언스 라이브러리 간에 디바이스 메모리를 공유할 수 있도록 지원합니다. GPU에 데이터가 유지되므로, 호스트 메모리에 반복적으로 데이터를 복사하느라 높은 비용이 들지 않게 해줍니다..
