텍스트 음성 변환은 텍스트 문자의 문자열을 음성 출력으로 변환하는 음성 합성의 한 형태입니다.
텍스트 음성
텍스트 음성 변환이란?
저지연으로 텍스트에서 고품질의 자연스러운 음성을 생성하는 기술(텍스트 음성 변환(TTS)이라고도 함)은 수십 년 동안 구현하기 어려운 과제로 여겨졌습니다. 원래 이 기술은 시각 장애나 읽기 장애가 있는 사람에게 글로 작성된 내용을 들려주기 위한 방법으로 개발되었습니다. 과거에는 사람이 직접 읽어야 했거나 실용적이지 못했지만 오늘날 텍스트 음성 변환은 다양하게 활용될 수 있도록 발전했습니다. 사용 사례에는 운전 방향을 제시하고, 콜센터에서 고객과 대화하고, 가상 비서를 구동하는 것 등이 포함됩니다.
가장 일반적인 시스템은 사전 녹음된 음성 세그먼트를 실시간으로 함께 조합하는 방식을 사용했습니다. 최근에는 완전히 머신으로만 자연스러운 음성을 생성하기 위해 신경망이 적용되었습니다.

텍스트 음성 변환을 사용하는 이유는?
텍스트 음성 변환은 말하는 알람 시계부터 문자 메시지를 음성으로 변환하는 차량용 비서 그리고 Apple의 Siri, Amazon의 Echo와 같은 정교한 질의응답 시스템에 이르기까지 우리의 일상생활에 스며들었습니다. 이 기술은 화면을 읽는 것이 불가능하거나 불편한 여러 상황에 해결책을 제시합니다.
텍스트 음성 변환은 자동 음성 인식(ASR) 그리고 언어 번역과 같은 자연어 처리(NLP)를 수반하는 대화형 AI 영역으로 점점 더 이동하고 있습니다. 특히, 고객 서비스 분야에서 적용 사례가 증가하고 있습니다. 이제는 음성 인식 시스템이 복잡한 질의를 처리하고 데이터베이스를 검색하여 답변을 찾고 텍스트 음성 변환을 사용하여 응답을 제공합니다. 요즘 텔레마케터들은 이러한 시스템을 사용하여 인간 상담원을 대화형 로봇으로 대체합니다. 이 로봇은 인간 조작자가 더 이상 필요하지 않을 만큼 현실적인 대화를 이어갈 수 있습니다.

연구에 따르면 사람들은 응답이 사람 같은 목소리로 전달될 때 더 편하게 대화할 수 있습니다. 신경망을 사용하면 연결 합성(concatenative synthesis)의 오버헤드나 조음 합성(articulatory synthesis)의 복잡성 없이 텍스트 음성 변환 시스템이 생성 가능한 음역을 늘릴 수 있습니다.
텍스트 음성 변환의 작동 방식은?
최첨단 음성 합성 모델은 파라메트릭 신경망을 기반으로 합니다. 텍스트 음성 변환(TTS)의 합성은 일반적으로 두 단계로 수행됩니다.
- 첫 번째 단계에서는 합성 네트워크가 텍스트를 스펙트로그램, 기본 주파수와 같은 시간 정렬된(time-aligned) 특징으로 변환합니다. 기본 주파수는 유성음을 낼 때 성대가 진동하는 횟수를 나타냅니다.
- 두 번째 단계에서는 보코더 네트워크가 시간 정렬된 특징을 오디오 파형으로 변환합니다.

합성을 위해 입력 텍스트를 준비하는 과정에는 텍스트 분석이 필요합니다. 예를 들면, 텍스트를 단어와 문장으로 변환하고, 약어를 식별 및 확장하고, 표현을 인식하고 분석해야 합니다. 표현에는 날짜, 금액, 공항 코드 등이 포함됩니다.
텍스트 분석의 출력이 언어 분석으로 전달되면 발음을 다듬고, 단어의 발성 시간을 계산하고, 발화의 운율 구조를 해독하고, 문법 정보를 이해합니다.
언어 분석의 출력은 Tacotron2와 같은 음성 합성 신경망 모델에 공급됩니다. 이 모델은 텍스트를 멜 스펙트로그램으로 변환한 다음, 자연스러운 음성을 생성하는 Wave Glow와 같은 뉴럴 보코더 모델에 전달합니다.
TTS에 널리 사용되는 딥 러닝 모델로는 Wavenet, Tacotron 2, WaveGlow 등이 있습니다.
2006년에 Google WaveNet은 오디오 신호의 원시 파형을 한 번에 한 샘플씩 직접 모델링하는 새로운 접근 방식의 딥 러닝 기법을 도입했습니다. 이 모델은 확률론적 특성과 자기회귀 특성을 가지며, 각 오디오 샘플에 대한 예측 분포를 이전의 모든 샘플에 맞춰 조정합니다. WaveNet은 완전 합성곱 신경망으로, 합성곱층에 다양한 확장 계수가 있어 층이 깊어질수록 수용 영역이 기하급수적으로 커집니다. 입력 시퀀스는 인간 화자로부터 녹음한 파형입니다.

Tacotron 2는 신경망 아키텍처로, 어텐션을 적용한 순환 시퀀스-투-시퀀스 모델을 사용하여 텍스트에서 직접 음성 합성을 수행합니다. 인코더(아래 그림의 파란색 블록)는 전체 텍스트를 고정 크기의 숨겨진 특징 표현으로 변환합니다. 그런 다음 이 특징 표현은 한 번에 하나의 스펙트로그램 프레임을 생성하는 자기회귀 디코더(주황색 블록)에 사용됩니다. 파이토치 모델을 위한 NVIDIA Tacotron 2와 WaveGlow에서 이 자기회귀 WaveNet(녹색 블록)은 흐름 기반 생성 WaveGlow로 대체됩니다.

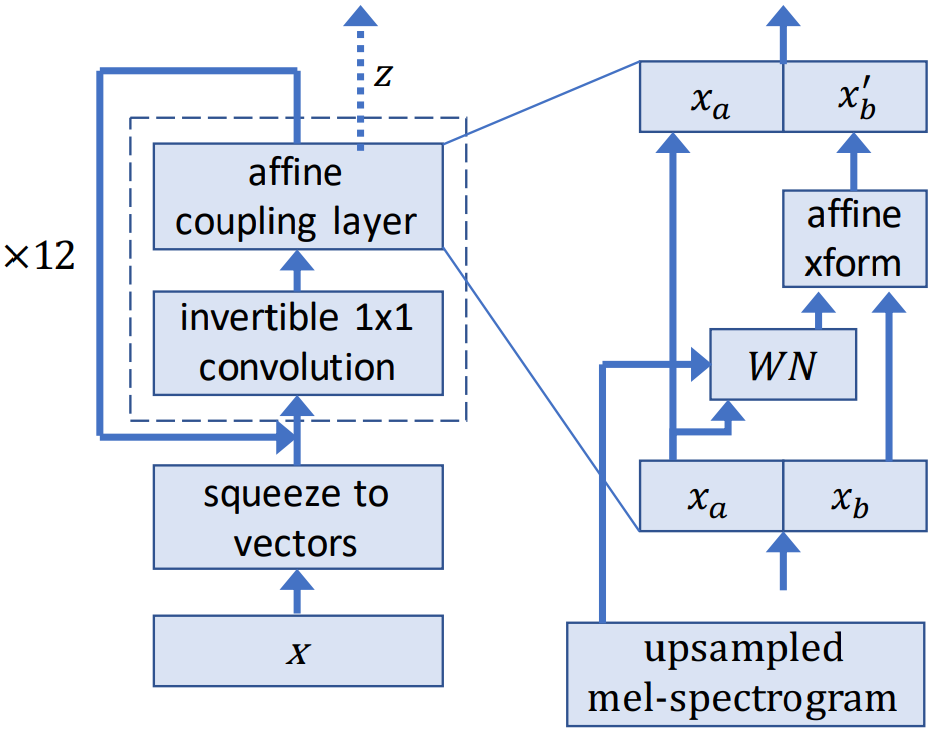
WaveGlow는 멜 스펙트로그램을 사용하여 음성을 생성하는 흐름 기반 모델입니다.
훈련 과정에서 이 모델은 일련의 흐름을 통해 데이터 세트 분포를 구형 가우시안 분포로 변환하는 방법을 학습합니다. 흐름의 한 단계는 역합성곱으로 구성되고, 이어 아핀 커플링층 역할을 하는 수정된 WaveNet 아키텍처가 뒤따릅니다. 추론하는 동안에는 망이 반전되고 가우시안 분포에서 오디오 샘플이 생성됩니다.
업계 응용 사례
헬스케어
의료 부문의 난제 중 하나는 의료 서비스를 쉽게 이용할 수 있도록 만드는 것입니다. 병원에 전화하여 대기하는 것은 흔한 일이며, 담당자와 연결되는 것도 마찬가지로 어려울 수 있습니다. 챗봇 훈련을 위한 자연어 처리(NLP) 구현은 의료 분야에서 부상 중인 기술로, 의료 전문가의 부족을 해결하고 환자에게 소통의 장을 열어줄 수 있습니다.
NGC의 NVIDIA Clara Guardian과 NVIDIA Fleet Command로 스마트 병원 강화하기라는 블로그에서는 환자로부터 입력 쿼리를 수신하고, 의도와 관련 슬롯을 추출하여 쿼리를 해석하고, 자연스러운 음성으로 응답을 실시간 산출하는 가상 환자 도우미 클라이언트 애플리케이션을 구축하는 방법을 알아볼 수 있습니다.
Financial Services
NLP는 금융 서비스 회사를 위한 더 나은 챗봇과 AI 비서를 구축하는 데 있어 매우 중요한 부분입니다.
소매
챗봇 기술은 고객 문의를 정확하게 분석하고 응답이나 추천을 생성하기 위해 소매 애플리케이션에 일반적으로 사용됩니다. 이를 통해 고객 여정을 간소화하고 매장 운영의 효율성을 개선할 수 있습니다.
GPU: 딥 러닝 가속화
최근 Tacotron 2와 같은 혁신이 일어나며 텍스트 음성 변환에 딥 러닝이 전면 도입되기 시작했습니다. 최첨단 딥 러닝 신경망의 경우 역전파를 통해 조정해야 하는 매개변수가 수백만 개에서 10억 개 이상에 이를 수 있습니다. 또한 높은 정확도를 얻기 위해 많은 양의 학습 데이터가 필요합니다. 즉, 수십만에서 수백만 개에 이르는 입력 샘플을 순방향 패스 및 역방향 패스 양쪽으로 실행해야 합니다. 신경망은 수많은 동일 뉴런에서 생성되므로 본질적으로 병렬성이 매우 높습니다. 이러한 병렬성은 자연스럽게 GPU로 매핑됩니다. GPU는 CPU만 사용하는 훈련에 비해 월등히 높은 연산 속도를 제공합니다. 이러한 이유로 GPU는 복잡한 대규모 신경망 기반 시스템을 훈련시키기 위한 플랫폼으로 선택되어 왔으며, 병렬성이 특징인 추론 작업 또한 GPU에서 실행하기에 매우 알맞습니다.

NVIDIA GPU 가속 텍스트 음성 변환
대화형 AI로 서비스를 제공하는 것은 힘든 일처럼 보일 수 있지만, NVIDIA는 이런 프로세스를 더 쉽게 구현할 수 있도록 Neural Modules(줄여서 NeMo), NVIDIA® TensorRT™ 그리고 NVIDIA Riva라는 신기술을 비롯하여 여러 도구를 제공하고 있습니다. NGC의 여러 사전 훈련된 모델은 Bert, Tacotron2, WaveGlow와 같은 ASR, NLP 및 TTS에 사용될 수 있습니다. 이 모델들은 높은 정확도를 달성하기 위해 수천 시간 분량의 오픈 소스 및 사유 데이터를 학습하고, NVIDIA DGX™ 시스템에서 10만 시간 이상 훈련됩니다. GPU 가속 Tacotron2와 Waveglow는 NVIDIA T4 GPU에서 CPU만 사용하는 솔루션보다 9배 더 빠르게 추론을 수행할 수 있습니다.
NVIDIA NeMo는 파이토치 백엔드가 포함된 오픈 소스 툴킷으로, 개발자가 세 줄의 코드로 복잡한 최첨단 신경망 아키텍처를 빠르게 구성하고 훈련할 수 있도록 지원합니다. 또한 NeMo에는 ASR, NLP, TTS에 사용할 수 있는 확장 가능한 모델 컬렉션도 함께 제공됩니다. 이 컬렉션들은 QuartzNet, Bert, Tacotron 2, WaveGlow와 같은 최첨단 네트워크 아키텍처를 쉽게 구축할 수 있는 방법을 제공합니다. NeMo를 사용하면 손쉽게 구할 수 있는 API로 NVIDIA NGC에서 자동으로 모델을 다운로드하고 인스턴스화한 다음, 맞춤형 데이터 세트로 모델을 파인 튜닝할 수도 있습니다.

NVIDIA Riva는 대화형 AI 작업을 수행하기 위한 여러 파이프라인을 제공하는 애플리케이션 프레임워크입니다. 이러한 작업 중에서도 저지연으로 텍스트에서 고품질의 자연스러운 음성을 생성하는 것은 가장 까다로운 연산 작업에 속할 수 있습니다. Riva 텍스트 음성 변환(TTS) 파이프라인을 사용하면 최대한 짧은 시간 내에 자연스러운 음성으로 응답하는 대화형 AI를 구현하여 매력적인 사용자 경험을 제공할 수 있습니다.

NVIDIA GPU 가속 엔드투엔드 데이터 사이언스
CUDA-X AI™를 기반으로 구축된 소프트웨어 라이브러리인 NVIDIA RAPIDS™ 제품군은 엔드투엔드 데이터 사이언스 및 분석 파이프라인을 전적으로 GPU에서 실행할 수 있게 해줍니다. 이 제품군은 NVIDIA CUDA® 프리미티브를 사용하여 저수준 컴퓨팅 최적화를 수행하지만, 사용자 친화적인 Python 인터페이스를 통해 GPU 병렬 처리와 고대역폭 메모리 속도를 제공합니다.

NVIDIA GPU 가속 딥 러닝 프레임워크
GPU 가속 딥 러닝 프레임워크는 맞춤형 심층 신경망을 유연하게 설계하고 훈련할 수 있는 기능과 파이썬, C/C++와 같이 일반적으로 사용되는 프로그래밍 언어를 위한 인터페이스를 제공합니다. MXNet, PyTorch, TensorFlow 등 널리 사용되는 딥 러닝 프레임워크는 고성능 멀티 GPU 가속화 학습을 제공하기 위해 NVIDIA GPU 가속화 라이브러리를 사용합니다.

다음 단계
더 자세한 내용은 아래 나열된 블로그, 코드 샘플 및 Jupyter Notebook을 참조하세요.
- NVIDIA 대화형 AI 및 대화형 AI SDK 웹페이지
- Riva 소개: GPU 가속 대화형 AI 애플리케이션을 위한 프레임워크
- NVIDIA NeMo를 통한 음성 및 언어 모델 개발 가속화
- NVIDIA Riva를 사용하여 텍스트 음성 변환 서비스에서 60 이상의 RTF(Real-time Factor) 달성하기
- 텍스트에서 실시간으로 일반적이고 자연스러운 음성 생성하기(블로그)
- TensorRT를 사용하여 GPU에 실시간 텍스트 음성 변환 애플리케이션을 배포하는 방법(블로그)
- TTS NeMo 코드 샘플
- NVIDIA Tacotron2 코드 샘플
- ForwardTacotron으로 강력한 뉴럴 음성 합성 생성하기
- NGC의 NVIDIA Clara Guardian과 NVIDIA Fleet Command로 스마트 병원 지원
더 알아보기:
- GPU로 가속화한 데이터센터는 더 적은 서버를 사용하고, 더 작은 공간을 차지하며, 전력 소비를 줄이면서 역대 최고 수준의 성능을 제공할 수 있습니다. NVIDIA GPU Cloud는 방대한 소프트웨어 라이브러리를 무료로 제공할 뿐만 아니라, GPU를 최대한 활용하는 고성능 컴퓨팅 환경을 구축하는 데 유용한 여러 도구를 제공합니다.
- NVIDIA Deep Learning Institute는 강사 주도형 실습 교육을 통해 문서 분류와 같은 텍스트 분류 작업을 위한 트랜스포머 기반 자연어 처리 모델을 구축하는 데 필요한 기본적인 도구와 기법을 소개하고 있습니다.