개요
에이전틱 AI란 무엇인가요?
에이전틱 AI는 정교한 추론과 계획을 사용하여 복잡한 다단계 문제를 해결합니다. 에이전틱 AI 시스템은 여러 데이터 소스에서 방대한 양의 데이터를 수집하여 문제를 분석하고, 전략을 개발하며, 독립적으로 작업을 완료합니다.
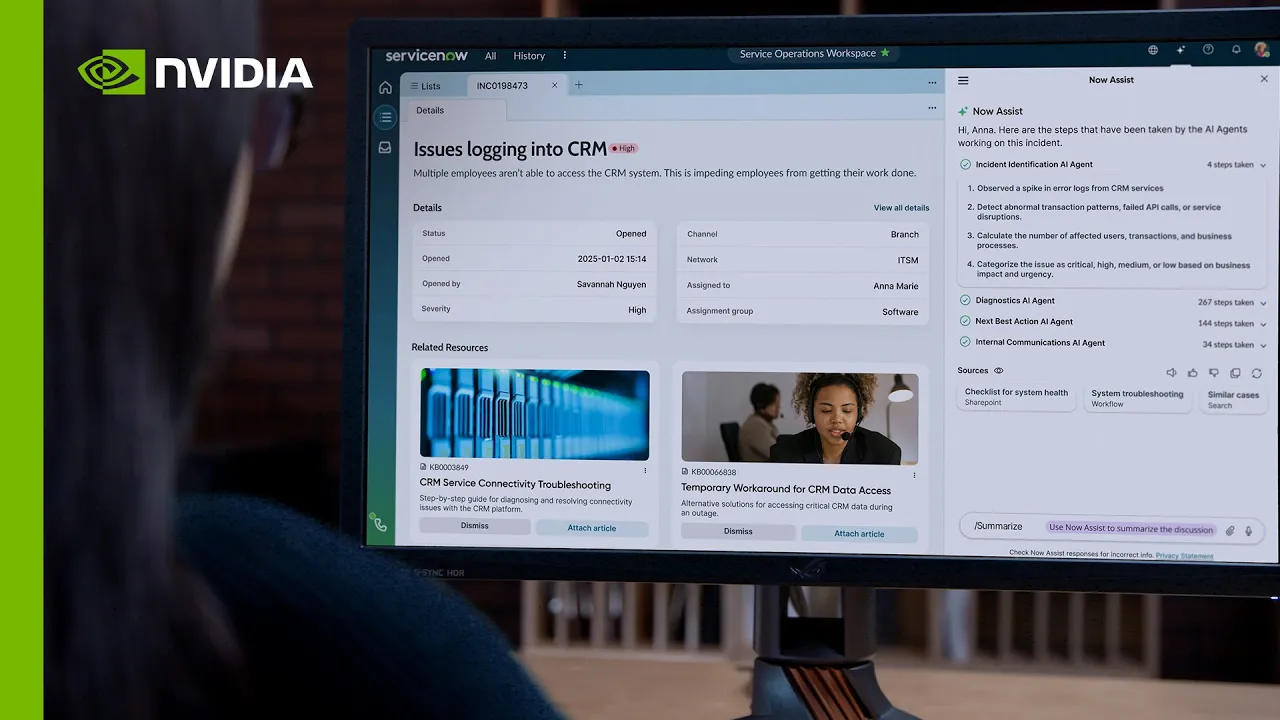
AI 에이전트는 엔터프라이즈 데이터를 실행 가능한 지식으로 변환합니다.
시간이 지남에 따라 AI 에이전트는 데이터 플라이휠을 생성하여 학습하고 개선하며, 이 경우 인간과 AI 피드백을 사용하여 모델을 개선하고 결과를 향상합니다.
에이전틱 AI 활용 사례 보기

에이전트틱 AI를 위한 핵심 구성 요소
5분 안에 간단한 AI 에이전트 구축하기
에이전틱 AI로 비즈니스를 혁신해 보세요
AI 팩토리
기술
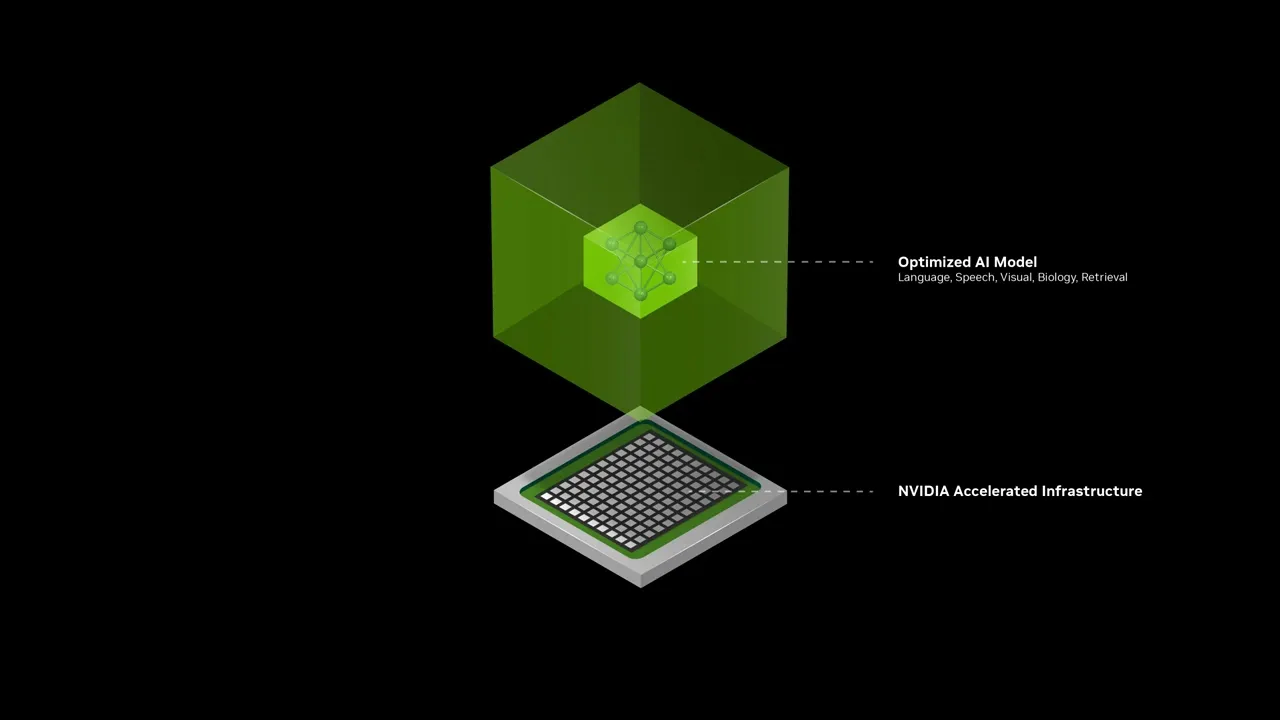
에이전틱 AI의 핵심 구성 요소
맞춤 생성형 AI를 위한 NVIDIA NeMo™, 빠른 엔터프라이즈급 배포를 위한 NVIDIA NIM™, 맞춤형 참조 워크플로우를 통해 개발을 가속화하기 위한 NVIDIA Blueprints로 지능형 AI 에이전트 구축을 시작하세요.



고성능, 확장성, 보안성을 갖춘 AI 팩토리
AI 팩토리란 데이터 수집부터 대규모 추론에 이르기까지 AI의 전체 생애주기를 최적화하는 특화된 컴퓨팅 인프라로, 실시간 인텔리전스를 제공하고 대규모 혁신을 이끕니다.

NVIDIA Enterprise AI 팩토리는 고성능, 확장성, 그리고 보안성을 갖춘 AI 플랫폼을 온프레미스 환경에서 구축하고 배포할 수 있도록 설계된 풀스택 검증 디자인입니다.
모델
선도적인 개방형 모델로 구축
최신 추론 및 생성형 AI 모델에 최적화된 추론 성능을 활용하세요. NIM은 NVIDIA® TensorRT™, TensorRT-LLM 등을 포함하여 NVIDIA와 커뮤니티에서 제공하는 가속 추론 엔진을 탑재했으며, NVIDIA 가속 인프라에서 지연 시간이 짧고 처리량이 높은 추론을 위해 사전 구축되고 최적화되었습니다.
리소스
잠금 해제, 기술 향상 및 업스케일링
에이전틱 AI 여정을 시작하는 데 도움이 될 자료들을 살펴보세요.



에코시스템
엔터프라이즈 AI, 더 빠르고 더 멀리 확장하세요.
주요 파트너와 함께 에코시스템의 모델, 툴킷, 벡터 데이터베이스, 프레임워크 및 인프라를 사용하여 AI 애플리케이션을 개발하세요.
다음 단계
시작할 준비가 되셨나요?
적절한 도구와 기술을 사용하여 개발부터 생산까지 에이전틱 AI를 적용하세요.
문의하기
NVIDIA AI Enterprise가 제공하는 보안, API 안정성, 기술 지원을 바탕으로, 파일럿 단계에서 운영 환경으로의 전환에 대해 NVIDIA 제품 전문가와 상담해보세요.
최신 NVIDIA 에이전틱 AI 뉴스 받아보기
에이전틱 AI 뉴스, 기술, 혁신 등의 최신 소식을 바로 받아보세요.