
Processamento Inteligente de Documentos
Transforme documentos complexos, relatórios, apresentações, PDFs, páginas da web e planilhas em inteligência pesquisável.
Visão geral: por que escolher o processamento Inteligente de Documentos?
Leia, entenda e extraia insights de documentos para automatizar a tomada de decisões.
O processamento inteligente de documentos ajuda as instituições a transformar conteúdo multimodal diverso — como relatórios, contratos, registros, políticas e artigos de pesquisa — em insights estruturados e pesquisáveis, identificando as informações mais importantes.
O processamento de documentos com modelos abertos e bibliotecas NVIDIA Nemotron combina extração de alta fidelidade, recuperação multimodal e geração fundamentada. As equipes podem criar agentes de IA que leem documentos como especialistas, preservando a rastreabilidade à fonte original.
Benefícios
Abrangem várias áreas que ajudam equipes de analistas, pesquisadores e usuários finais a alcançar melhores resultados.
- Insights mais rápidos: automatize a revisão de relatórios, contratos e políticas densos para que as equipes obtenham respostas em segundos, em vez de horas.
- Cargas de trabalho escaláveis para documentos: processe milhões de PDFs, páginas da web e planilhas em paralelo, à medida que novos dados chegam, sem aumentar o número de funcionários.
- Maior qualidade de decisão: preserve tabelas, gráficos e figuras para que os agentes de IA raciocinem com as mesmas evidências em que os especialistas confiam hoje.
- Auditabilidade e conformidade: fundamente todas as respostas em páginas e tabelas citadas para atender a requisitos regulatórios e de auditoria interna rigorosos.
- Impacto em vários setores: ofereça suporte a diversos workflows em domínios financeiros, legais e científicos, com um pipeline inteligente que se adapta a diferentes tipos de documentos e domínios.
Links rápidos
Edison Scientific: cientista IA Kosmos sintetiza dezenas de milhares de artigos de pesquisa
A Edison Scientific, um spinout da FutureHouse, está construindo o Kosmos, um cientista de IA capaz de descoberta autônoma. O Kosmos é um sistema de vários agentes com um agente de literatura especializado, projetado para responder a perguntas sobre literatura científica, ensaios clínicos e patentes. Com tecnologia do Nemotron Parse, o agente de literatura pesquisa de forma autônoma mais de 175 milhões de documentos para responder a perguntas de pesquisadores, ajudando mais de 50 mil cientistas em seu trabalho de descoberta.
Para cada página, o Nemotron Parse retorna texto semântico para incorporação e pesquisa e, em seguida, segmenta as regiões de imagem visual para raciocínio multimodal de LLM.
Os artigos científicos não são escritos para um padrão comum e geralmente incluem figuras complexas que podem ser mal interpretadas. O Nemotron Parse é essencial para identificar tabelas, figuras e texto relevantes em um PDF, sobre os quais um LLM pode raciocinar e gerar respostas às consultas dos usuários.
O agente de literatura da Edison ajuda a:
- Reduza o trabalho manual, entendendo grandes volumes de dados
- Acelerar a análise, extraindo os principais detalhes
- Melhorar a qualidade das decisões tomadas por ferramentas e humanos
Compreender a literatura científica com rapidez e precisão é um componente crítico que permitiu que o Kosmos concluísse 6 meses de pesquisa em um dia, com reprodutibilidade de 80%.
Links rápidos
Implementação técnica
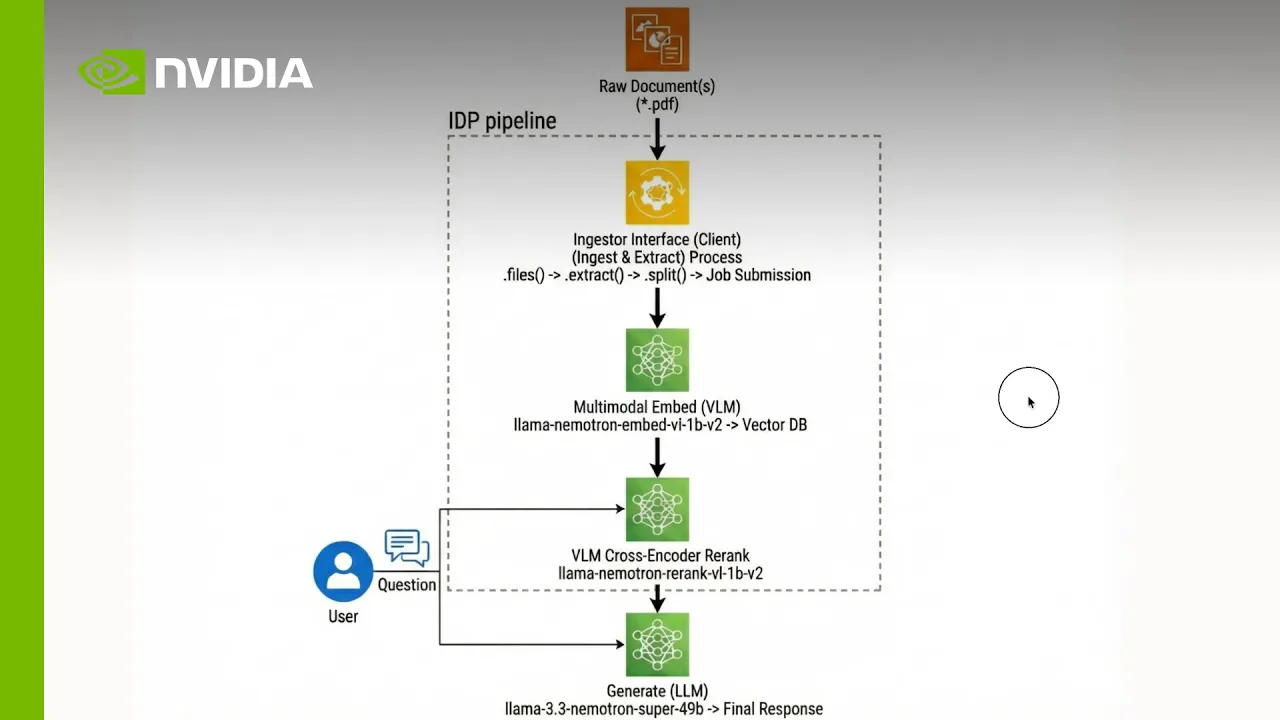
Diagrama de arquitetura

Um pipeline de processamento de documentos inteligente é criado em torno de três componentes principais: extração, incorporação e indexação e reordenamento para geração de respostas.
Os desenvolvedores podem configurar, estender e implantar com modelos abertos, NeMo Retriever e microsserviços NIM.
1. Extração: transforme documentos complexos em dados estruturados
Use a biblioteca NeMo Retriever com serviços de análise e OCR auto-hospedados ou hospedados pela NVIDIA para inserir PDFs, páginas da web e outros documentos multimodais e convertê-los em unidades estruturadas, como pedaços de texto, tabelas de markdown e cortes de gráficos, preservando o layout e a semântica. Esse estágio “desbloqueia” conteúdo rico, mantendo tabelas como tabelas e figuras como imagens, produzindo saídas JSON que os modelos de recuperação e geração downstream podem consumir de forma confiável.
2. Incorporação e indexação: torne o conteúdo pesquisável em escala
Alimente os itens extraídos em modelos de incorporação multimodal Nemotron para codificar texto, tabelas e gráficos em vetores densos adaptados para recuperação de documentos. Armazene esses vetores e metadados associados em um banco de dados vetorial, como o Milvus, permitindo a pesquisa semântica em milissegundos em milhões de elementos de documentos e mantendo sua base de conhecimento continuamente atualizada à medida que novo conteúdo chega.
3. Reranking e geração de respostas fundamentadas: ofereça respostas citadas e de alta fidelidade
Recupere os principais candidatos do índice vetorial e aplique a reorganização de codificadores cruzados Nemotron para priorizar as passagens, tabelas e figuras que melhor respondem à pergunta de um usuário. Transforme esse contexto reclassificado em um modelo de geração Nemotron, que produz respostas fundamentadas com citações explícitas de volta às páginas e gráficos originais, para que as equipes empresariais, financeiras e científicas possam confiar e auditar todas as decisões apoiadas pelo sistema.
Passo a passo de código sobre a criação de um pipeline inteligente de processamento de documentos usando tecnologias abertas Nemotron
Links rápidos
Ecossistema de Parceiros
Links rápidos
Perguntas Frequentes
Um pipeline NVIDIA RAG de nível de produção inclui um banco de dados vetorial e microsserviços NIM conteinerizados, ou implantação baseada em Kubernetes para escalar a extração, a incorporação e a recuperação em grandes volumes de documentos. Para implantações auto-hospedadas, escolha as GPUs NVIDIA com VRAM suficiente; alternativamente, os endpoints hospedados podem reduzir os requisitos de infraestrutura local. Também é importante ajustar as configurações de extração (como o formato de saída de tabela e a divisão em nível de página), escolher os modelos apropriados de extração, incorporação e reordenamento do Nemotron e instrumentar o sistema para medir a taxa de transferência, a latência e a qualidade de citação para atender aos SLAs empresariais.
O Nemotron Parse usa uma arquitetura de linguagem de visão com ancoragem espacial para detectar e extrair texto, tabelas, gráficos e elementos de layout, produzindo saídas estruturadas e legíveis por máquina, em vez de texto plano. Ele preserva a estrutura de tabelas, a ordem de leitura e as classes semânticas, melhorando significativamente a precisão em benchmarks desafiadores e tornando a recuperação e o raciocínio downstream em PDFs, digitalizações e relatórios complexos muito mais confiáveis. Essas saídas estruturadas também podem suportar uma fragmentação mais semântica, ajudando os sistemas de recuperação a dividir documentos ao longo de limites de conteúdo significativos, em vez de janelas de texto arbitrárias.
Resposta: em um pipeline RAG, o estágio de extração molda a qualidade e a estrutura das evidências disponíveis para recuperação. Use o PDFium para PDFs criados digitalmente quando a taxa de transferência é a prioridade, o OCR quando você quer extração visual com um forte equilíbrio de velocidade e precisão, e o Nemotron Parse quando o layout mais rico e a estrutura de documentos melhoram a qualidade de fragmentação e recuperação. No NeMo Retriever, escolher o caminho de extração de OCR roteia a extração de documentos por meio do serviço NeMo Retriever OCR.
Em suma: o PDFium é o melhor para PDFs criados digitalmente, o OCR equilibra a velocidade e a extração visual e o Nemotron Parse prioriza a fidelidade de layout e a estrutura semântica.
Links rápidos