
Elaborazione intelligente dei documenti
Trasforma documenti, report, presentazioni, PDF, pagine web e fogli di calcolo complessi in informazioni ricercabili.
Panoramica: perché l'elaborazione intelligente dei documenti
Leggi, comprendi ed estrai informazioni dettagliate sui documenti per automatizzare il processo decisionale
L'elaborazione intelligente dei documenti aiuta le istituzioni a trasformare contenuti multimodali diversificati, come report, contratti, documenti, polizze e documenti di ricerca, in insight strutturati e ricercabili identificando le informazioni più importanti.
L'elaborazione dei documenti con modelli e librerie aperti NVIDIA Nemotron combina l'estrazione ad alta fedeltà, il recupero multimodale e la generazione ancorata. I team possono creare agenti IA in grado di leggere documenti come esperti, preservando la tracciabilità fino alla fonte originale.
Vantaggi
Questi coprono diverse aree che aiutano i team di analisti, ricercatori e utenti finali a ottenere risultati migliori.
- Insight Discovery più veloce: automatizza la revisione di report, contratti e polizze complessi in modo che i team ottengano risposte in pochi secondi anziché ore.
- Carichi di lavoro documentali scalabili: elabora milioni di PDF, pagine web e fogli di calcolo in parallelo man mano che arrivano nuovi dati, senza aggiungere il numero di dipendenti in modo lineare.
- Qualità decisionale superiore: conserva tabelle, grafici e figure in modo che gli agenti IA ragionino sulle stesse prove a cui gli esperti si affidano oggi.
- Auditabilità e conformità: basa ogni risposta su pagine e tabelle citate per soddisfare i rigorosi requisiti normativi e di audit interno.
- Impatto intersettoriale: supporta flussi di lavoro diversi nei domini finanziari, legali e scientifici, con una pipeline intelligente che si adatta a diversi tipi di documenti e domini.
Collegamenti rapidi
Edison Scientific: Kosmos AI Scientist sintetizza decine di migliaia di documenti di ricerca
Edison Scientific, uno spinout di FutureHouse, sta creando Kosmos, uno scienziato IA in grado di effettuare scoperte autonome. Kosmos è un sistema multi-agente con un agente Literature specializzato progettato per rispondere a domande su letteratura scientifica, studi clinici e brevetti. Basato su Nemotron Parse, l'agente Literature ricerca in modo autonomo oltre 175 milioni di documenti per rispondere alle domande dei ricercatori, aiutando più di 50.000 scienziati con il loro lavoro di ricerca.
Per ogni pagina, Nemotron Parse restituisce testo semantico per l'embedding e la ricerca, quindi segmenta le aree dell'immagine visiva per il ragionamento LLM multimodale.
I documenti scientifici non sono scritti secondo uno standard comune e spesso includono figure complesse che possono essere erroneamente interpretate. Nemotron Parse è fondamentale per identificare tabelle, figure e testi rilevanti in un PDF su cui un LLM può quindi ragionare e generare risposte alle query degli utenti.
L'agente Literature di Edison aiuta a:
- Ridurre il lavoro manuale comprendendo grandi volumi di dati
- Velocizzare l'analisi estraendo i dettagli chiave
- Migliorare la qualità delle decisioni prese da strumenti ed esseri umani
Comprendere la letteratura scientifica in modo rapido e accurato è un componente critico che ha permesso a Kosmos di completare 6 mesi di ricerca in un giorno, con una riproducibilità dell'80%.
Collegamenti rapidi
Implementazione tecnica
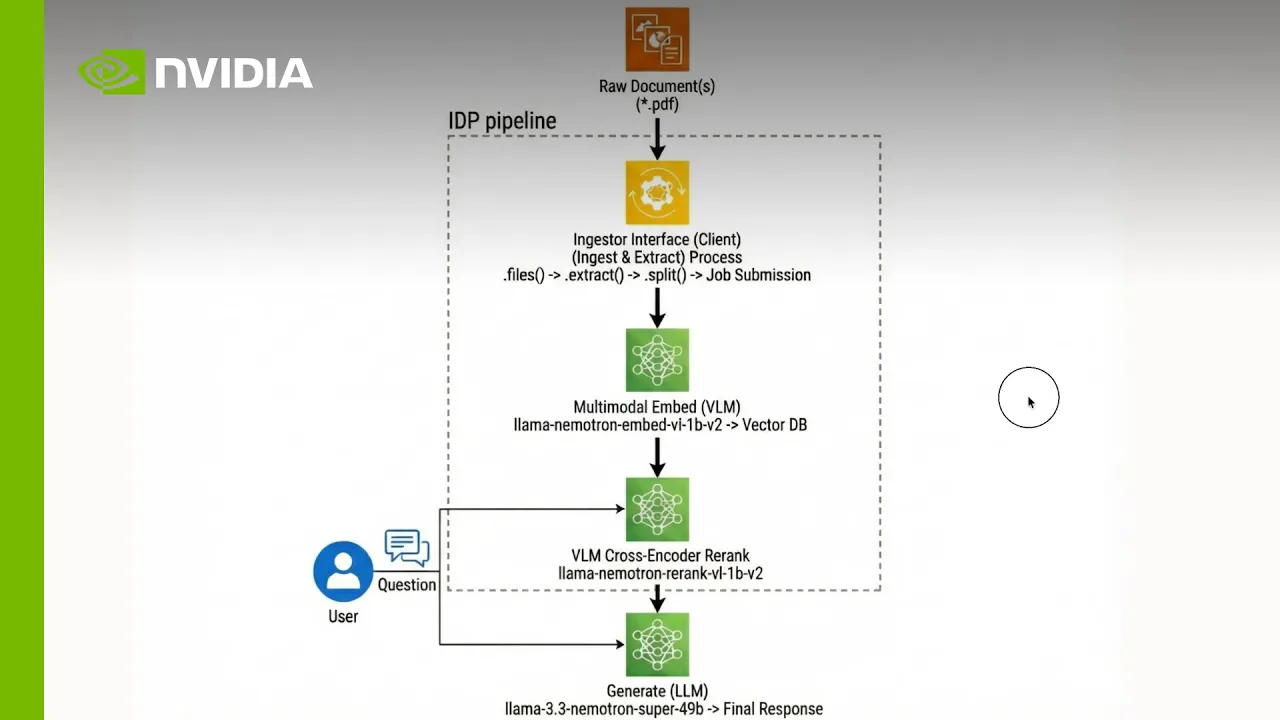
Diagramma dell'architettura

Una pipeline intelligente di elaborazione dei documenti è basata su tre componenti fondamentali: estrazione, embedding e indicizzazione e reranking per la generazione di risposte.
Gli sviluppatori possono configurare, estendere e distribuire con modelli aperti, NeMo Retriever e microservizi NIM.
1. Estrazione: trasforma documenti complessi in dati strutturati
Utilizzare la libreria NeMo Retriever con servizi di analisi e OCR auto-ospitati o ospitati da NVIDIA per ingerire PDF, pagine web e altri documenti multimodali e convertirli in unità strutturate come chunk di testo, tabelle markdown e crop di grafici, preservando il layout e la semantica. Questa fase "sblocca" contenuti ricchi mantenendo le tabelle come tabelle e figure come immagini, producendo output JSON che i modelli di recupero e generazione downstream possono utilizzare in modo affidabile.
2. Embedding e indicizzazione: rendi i contenuti ricercabili su larga scala
Alimenta gli elementi estratti in modelli di embedding multimodali Nemotron per codificare testi, tabelle e grafici in vettori densi su misura per il recupero dei documenti. Archivia questi vettori e i metadati associati in un database vettoriale come Milvus, consentendo una ricerca semantica in millisecondi su milioni di elementi documentali e mantenendo la knowledge base continuamente aggiornata con l'arrivo di nuovi contenuti.
3. Reranking e generazione di risposte fondate: offri risposte citate e ad alta fedeltà
Recupera i candidati top-K dall'indice vettoriale e applica il cross-encoder reranking Nemotron per dare priorità ai passaggi, alle tabelle e alle figure che rispondono meglio alla domanda di un utente. Trasferisci questo contesto riclassificato in un modello di generazione Nemotron, che produce risposte fondate con citazioni esplicite alle pagine e ai grafici originali, in modo che i team aziendali, finanziari e scientifici possano fidarsi di ogni decisione supportata dal sistema e verificarla.
Code Walkthrough sulla creazione di una pipeline intelligente di elaborazione dei documenti utilizzando le tecnologie aperte Nemotron
Collegamenti rapidi
Ecosistema dei partner
Collegamenti rapidi
FAQ
Una pipeline NVIDIA RAG di livello produttivo include un database vettoriale e microservizi NIM containerizzati o una distribuzione basata su Kubernetes per scalare l'estrazione, l'embedding e il recupero in grandi volumi di documenti. Per le distribuzioni auto-ospitate, scegli le GPU NVIDIA con VRAM sufficiente; in alternativa, gli endpoint ospitati possono ridurre i requisiti dell'infrastruttura locale. È inoltre consigliabile ottimizzare le impostazioni di estrazione (come il formato di output tabellare e la divisione a livello di pagina), scegliere modelli di estrazione, embedding e reranking Nemotron appropriati ed equipaggia il sistema per misurare il throughput, la latenza e la qualità delle citazioni per soddisfare gli SLA aziendali.
Nemotron Parse utilizza un'architettura linguistica visiva con grounding spaziale per rilevare ed estrarre testi, tabelle, grafici ed elementi di layout, producendo output strutturati e leggibili da una macchina anziché testi semplici. Preserva la struttura delle tabelle, l'ordine di lettura e le classi semantiche, migliorando significativamente l'accuratezza su benchmark impegnativi e rendendo il recupero e il ragionamento a valle su PDF, scansioni e report complessi molto più affidabili. Questi output strutturati possono inoltre supportare una suddivisione più semantica, aiutando i sistemi di recupero a suddividere i documenti lungo confini di contenuto significativi anziché finestre di testo arbitrarie.
Risposta: In una pipeline RAG, la fase di estrazione determina la qualità e la struttura delle prove disponibili per il recupero. Usa PDFium per i PDF creati digitalmente quando il throughput è la priorità, l'OCR quando desideri l'estrazione visiva con un forte equilibrio tra velocità e precisione e Nemotron Parse quando il layout e la struttura dei documenti più ricchi migliorano la suddivisione e la qualità del recupero. In NeMo Retriever, la scelta del percorso di estrazione OCR instrada l'estrazione dei documenti attraverso il servizio OCR NeMo Retriever.
In breve, PDFium è ideale per i PDF creati digitalmente, l'OCR bilancia velocità ed estrazione visiva e Nemotron Parse dà priorità alla fedeltà del layout e alla struttura semantica.
Collegamenti rapidi