NVIDIA NeMo
Um pacote aberto e focado em agentes com habilidades para acelerar a especialização, a otimização e a governança de agentes de IA.
Visão Geral
O Que É o NVIDIA NeMo?
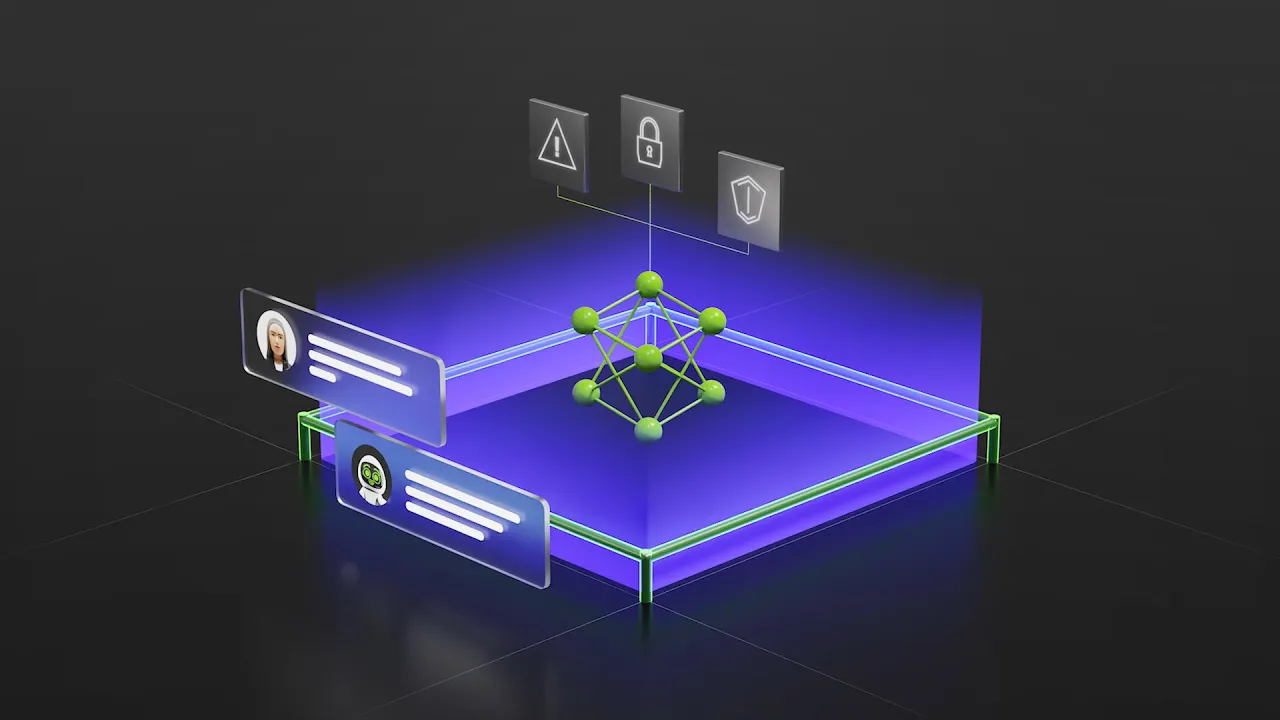
O NVIDIA NeMo™ é um pacote aberto de bibliotecas com foco em agentes, com habilidades para acelerar a especialização, a otimização e a governança de agentes de AI.
O NeMo se integra a ferramentas de AI e Frameworks de agentes existentes para otimizar agentes especializados em qualquer ambiente de Cloud, local ou híbrido.
Recursos
Ferramentas e habilidades para acelerar a otimização de agentes de IA especializados
O ciclo de vida dos agentes de IA é um processo de ponta a ponta para desenvolver e melhorar continuamente agentes de IA em aplicações de produção. O NeMo se integra a ferramentas de IA e frameworks de agentes existentes para otimizar agentes especializados durante todo o ciclo de vida deles.

| Desenvolver | |
|---|---|
| Prepare dados prontos para IA Processe conjuntos de dados multimodais existentes em formatos de alta qualidade e prontos para IA para pipelines de desenvolvimento e gere dados sintéticos para fechar lacunas críticas de dados. |
|
| Selecione o modelo certo Escolha ou desenvolva modelos adequados ao caso de uso: selecione o Nemotron™ ou outros modelos abertos, outras opções abertas ou proprietárias ou treine do zero. Valide com execuções de avaliação e faça ajustes conforme necessário. |
|
| Implantar | |
| Implante seu agente com o máximo desempenho Otimize seu agente para produção com inferência de alto rendimento e baixa latência, garantindo sua escalabilidade para atender às demandas empresariais e oferecer respostas rápidas e confiáveis. |
|
| Mantenha a fundamentação em dados e aplique guardrails Use a geração aumentada por recuperação (RAG) para ancorar as respostas dos agentes em conhecimento confiável enquanto aplica guardrails de segurança, conformidade e moderação de conteúdo. |
|
| Valide a segurança de agentes e modelos antes do lançamento Identifique e corrija vulnerabilidades de segurança em modelos e agentes antes que eles cheguem à produção. |
|
| Otimizar | |
| Crie o perfil e otimize seu agente Acompanhe as interações reais de agentes com usuários e outros sistemas. Avalie sistematicamente o desempenho e a precisão, encontrando oportunidades para melhorar continuamente. |
|
| Melhore continuamente com ciclos de dados Use o feedback e os dados coletados no monitoramento para criar um ciclo orientado por dados, retreinando iterativamente o agente em busca de otimização e efetividade contínuas ao longo do tempo. |
|
Casos de Uso
Como o NeMo Está Sendo Usado
Veja como o NVIDIA NeMo oferece suporte a casos de uso do setor e acelera o desenvolvimento de IA da sua empresa.
-
Agentes de IA
-
SDG para IA Baseada em Agentes
-
Assistente de IA
-
Recuperação de Informações
-
Geração de Conteúdo
-
Robô Humanoide
Agentes de IA
Os agentes de IA estão transformando o atendimento ao cliente em todos os setores, possibilitando às empresas melhorar as conversas com os clientes, alcançar altas taxas de resolução e melhorar a produtividade dos representantes humanos. Os agentes de IA conseguem lidar com tarefas preditivas, raciocinar e resolver problemas, ser treinados para entender termos específicos do setor e extrair informações relevantes das bases de conhecimento de uma empresa, independentemente de onde os dados residam.

Geração de Dados Sintéticos para IA Baseada em Agentes
Os sistemas especializados baseados em agentes exigem grandes volumes de dados de alta qualidade, cuja coleta a partir de fontes do mundo real é lenta e custosa. Os dados sintéticos criados por meio de simulações ou modelos de IA generativa podem eliminar esse gargalo criando cenários de treinamento ilimitados sem restrições de privacidade ou problemas de qualidade. Isso viabiliza o desenvolvimento mais rápido de LLMs com capacidade de raciocínio, tomadores de decisões de várias etapas e assistentes de IA multimodais.

Assistente de IA
As empresas estão implantando assistentes de IA para sanar as dúvidas de milhões de clientes e funcionários de forma eficiente e ininterrupta. Com tecnologia de microsserviços NVIDIA NIM para LLMs, RAG e IA para fala e tradução, esses membros da equipe de IA entregam respostas faladas imediatas e precisas, mesmo na presença de ruído de fundo, baixa qualidade de som e dialetos e sotaques variados.

Recuperação de Informações
Trilhões de arquivos PDF são gerados todos os anos, e cada arquivo provavelmente é composto por várias páginas preenchidas com tipos de conteúdo variados, incluindo texto, imagens, gráficos e tabelas. Essa mina de ouro de dados só pode ser aproveitada na mesma velocidade em que humanos conseguem lê-la e compreendê-la. Mas com a IA generativa e RAG, esses dados inexplorados podem ser usados para revelar percepções de negócios que ajudam colaboradores a trabalhar com mais eficiência e a reduzir custos.

Geração de Conteúdo
A IA generativa possibilita gerar conteúdo altamente relevante, personalizado e preciso, baseado na experiência de domínio e propriedade intelectual proprietária da sua empresa.

Robô Humanoide
Os robôs humanoides são criados para se adaptar rapidamente aos espaços de trabalho urbanos e industriais projetados para humanos, enfrentando tarefas tediosas, repetitivas ou fisicamente exigentes. Sua versatilidade os leva a trabalhar em locais tão variados quanto linhas de produção e instalações de saúde, onde auxiliam humanos e contribuem para mitigar a escassez de mão de obra por meio de automação.
Apptronik
Benefícios
Explore os Benefícios do NVIDIA NeMo para IA Baseada em Agentes

Desenvolvimento com habilidades e focado em agentes
Gerencie o ciclo de vida completo dos agentes, desde a curadoria de dados e o pós-treinamento até a avaliação, guardrails, observabilidade e otimização contínua usando uma suíte de habilidades otimizada para agentes.

Implantação e Escalabilidade Sem Interrupções
Desenvolva com facilidade ciclos de dados que usam dados empresariais para melhorar os agentes de IA, impulsionando todo o ciclo com uma implantação simples via Helm chart ou chamadas de API para várias partes do fluxo de trabalho.

Aumento do ROI
Treine, personalize e implante rapidamente grandes modelos de linguagem (LLMs), modelos multimodais de linguagem e visão (VLMs), IA para vídeo e IA para fala em escala, reduzindo o tempo até a solução e aumentando o ROI.

Desempenho Acelerado
Maximize o desempenho e o rendimento dos agentes de IA com otimização acelerada por GPU, escalabilidade de vários nós e ajustes para treinamento, implantação e melhoria contínua com eficiência de custos.

IA Baseada em Agentes Mais Segura
Desenvolva sistemas de IA baseada em agentes mais seguros, examinando modelos, aplicando proteções a prompts e realizando varreduras contínuas em busca de vulnerabilidades.

Pronto para Produção
Implante na produção com uma solução segura, otimizada e de stack completo que oferece suporte, segurança e estabilidade de APIs como parte do NVIDIA AI Enterprise.
Desenvolva, monitore e otimize agentes de IA em qualquer lugar — da nuvem e do data center até a borda.
Opções de Início
Maneiras de Começar a Usar o NVIDIA NeMo
Gerencie o ciclo de vida dos agentes de IA com ferramentas e tecnologias para desenvolvimento, monitoramento e otimização de agentes de IA na produção.
Histórias de Clientes
Como os Líderes do Setor Estão Impulsionando a Inovação com o NeMo
Usuários
Principais Usuários em Todos os Setores
-
Clientes
-
Parceiros
Recursos
Os Últimos Recursos do NVIDIA NeMo
-
Blogs
-
Sessões
-
Treinamento
-
Vídeos






Próximos Passos
Que Tal Começar Agora?
Use as ferramentas e tecnologias certas para levar modelos de IA baseada em agentes do desenvolvimento à produção.
Para Desenvolvedores
Explore tudo o que você precisa para começar a desenvolver com o NVIDIA NeMo, incluindo a documentação mais recente, tutoriais, blogs técnicos e muito mais.
Fale Conosco
Converse com um especialista em produtos da NVIDIA sobre a mudança da fase de teste para a produção com a garantia de segurança, estabilidade da API e suporte oferecidos pelo NVIDIA AI Enterprise.
Shell
Shell Treina Chatbot de IA Personalizado com o NVIDIA NeMo para Melhorar as Operações
A Shell, líder global no setor de energia, utilizou o NVIDIA NeMo™ para impulsionar sua jornada no desenvolvimento de um chatbot de IA personalizado com especialização no domínio químico. Essa solução inovadora tem o potencial de aumentar significativamente a produtividade dos funcionários ao otimizar os processos de pesquisa, melhorar a tomada de decisões e apoiar a pesquisa e o desenvolvimento em ambientes de produção.
AI Sweden
Acelere Aplicações do Setor com LLMs
A AI Sweden viabilizou aplicações de modelos de linguagem regional, fornecendo fácil acesso a um potente modelo de 100 bilhões de parâmetros. A empresa digitalizou registros históricos para desenvolver modelos de linguagem para uso comercial.
Amazon
Como a Amazon e a NVIDIA Capacitam os Vendedores a Criar Melhores Listagens de Produtos com IA
A Amazon dobra as velocidades de inferência para novos recursos de IA usando NVIDIA TensorRT-LLM e GPUs para capacitar os vendedores a otimizar listagens de produtos mais rapidamente.
Amdocs
NVIDIA e Amdocs Levam a IA Generativa Personalizada ao Setor Global de Telecomunicações
A Amdocs planeja criar LLMs personalizados para o setor global de telecomunicações de US$ 1,7 trilhão usando o serviço NVIDIA AI Foundry no Microsoft Azure.
AT&T
AT&T Impulsiona a Precisão, a Eficiência e o Desempenho dos Agentes de IA no Atendimento ao Cliente com o NVIDIA NeMo
A AT&T, uma das maiores empresas de telecomunicações do mundo, está reinventando o atendimento ao cliente por meio do poder da IA. Enfrentando desafios como deriva de modelos, crescentes demandas computacionais e a necessidade de acesso a dados em tempo real, a AT&T recorreu aos microsserviços NVIDIA NeMo™ para criar uma plataforma de IA orientada por feedback que melhora continuamente o desempenho, otimizando o custo, a velocidade e a conformidade.
AWS
NVIDIA Impulsiona o Treinamento para Alguns dos Maiores Modelos da Amazon Titan Foundation
A Amazon utilizou o framework NVIDIA NeMo, GPUs e AWS EFAs para treinar seu LLM de última geração, oferecendo aos clientes de alguns dos maiores modelos fundacionais Amazon Titan uma solução mais rápida e acessível para IA generativa.
Accenture
Acelere a Adoção de IA Generativa para Empresas
A ServiceNow, a NVIDIA e a Accenture anunciaram o lançamento do AI Lighthouse, um dos primeiros programas do gênero, projetado para acelerar o desenvolvimento e a adoção de recursos de IA generativa empresarial.
Azure
Como Usar o Poder do NVIDIA AI Enterprise no Azure Machine Learning
Obtenha acesso a um ecossistema completo de ferramentas, bibliotecas, frameworks e serviços de suporte adaptados para ambientes empresariais no Microsoft Azure.
Bria
Bria Cria IA Generativa Responsável para Empresas Usando NVIDIA NeMo e Picasso
Bria, uma startup com sede em Tel Aviv, está capacitando empresas que estão buscando maneiras responsáveis de integrar a tecnologia de IA generativa visual em seus produtos empresariais, por meio de um serviço de IA generativa que enfatiza a transparência de modelos, juntamente com atribuição justa e proteções autorais.
Cohesity
Utilize Seus Superpoderes de Dados: Microsserviços NVIDIA Viabilizam IA Generativa Segura de Nível Empresarial Para a Cohesity
Com o NVIDIA NIM e modelos otimizados, os clientes do Cohesity DataProtect podem adicionar inteligência de IA generativa a backups de dados e arquivos. Isso permite que a Cohesity e a NVIDIA levem o poder da IA generativa para todos os clientes do Cohesity DataProtect. Aproveitando o poder dos modelos otimizados NIM e NVIDIA, os clientes do Cohesity DataProtect obtêm o poder de percepções orientadas por dados de seus backups e arquivos de dados, liberando novos níveis de eficiência, inovação e crescimento.
CrowdStrike
Moldando o Futuro da IA no Domínio da Cibersegurança
A CrowdStrike e a NVIDIA estão utilizando a computação acelerada e IA generativa para fornecer aos clientes uma variedade inovadora de soluções com tecnologia de IA adaptadas para abordar com eficiência as ameaças à segurança.
Dell
A Dell Validou o Design para IA Generativa com a NVIDIA
A Dell Technologies e a NVIDIA anunciaram uma iniciativa para facilitar que empresas desenvolvam e utilizem modelos de IA generativa em instalações locais de forma rápida e segura.
Deloitte
Libere o Valor da IA Generativa em Todas as Plataformas de Software Empresarial
A Deloitte usará a tecnologia e a experiência em IA da NVIDIA para criar soluções de IA generativa de alto desempenho para plataformas de software empresarial, a fim de ajudar a desbloquear valor significativo para os negócios.
Domino Data Lab
Domino Oferece IA Generativa Pronta para Produção com Tecnologia NVIDIA
Com o NVIDIA NeMo, os cientistas de dados podem ajustar LLMs na plataforma Domino's para casos de uso específicos de domínio, com base em dados e propriedade intelectual proprietários, sem a necessidade de começar do zero.
Dropbox
Dropbox e NVIDIA Anunciam IA Generativa Personalizada a Milhões de Clientes
O Dropbox planeja aproveitar o NVIDIA AI Foundry para desenvolver modelos personalizados e aprimorar o trabalho de conhecimento impulsionado por IA com a ferramenta de pesquisa universal Dropbox Dash e Dropbox AI.
Google Cloud
Titãs de IA Colaboram Para Criar Mágica com IA Generativa
Em sua conferência Next, o Google Cloud anunciou a disponibilidade de suas instâncias A3 com tecnologia de GPUs NVIDIA H100 Tensor Core. As equipes de engenharia de ambas as empresas colaboraram para trazer o NVIDIA NeMo para as instâncias A3 para treinamento e inferência mais rápidos.
HuggingFace
Liderando a Comunidade de IA para Acelerar o Pipeline de Curadoria de Dados
A Hugging Face, a principal plataforma aberta para desenvolvedores de IA, está colaborando com a NVIDIA para integrar o NeMo Curator e acelerar o DataTrove, sua biblioteca de filtragem e deduplicação de dados. “Estamos empolgados com os recursos de aceleração de GPU do NeMo Curator e mal podemos esperar para vê-los contribuindo para o DataTrove!” afirmou Jeff Boudier, Diretor de Produtos da Hugging Face.
KT
Criação de Novas Experiências para Clientes com LLMs
A principal operadora de telefonia móvel da Coreia do Sul desenvolve LLMs de bilhões de parâmetros treinados com a plataforma NVIDIA DGX SuperPOD e o framework NeMo para capacitar alto-falantes inteligentes e centrais de atendimento ao cliente.
Lenovo
Nova Arquitetura de Referência para IA Generativa Baseada em LLMs
Solução para acelerar a inovação, capacitando parceiros e clientes globais a desenvolver, treinar e implantar IA em escala em todos os setores verticais com o máximo de segurança e eficiência.
QuantiPhi
Capacitando Capacitando Empresas a Acelerar Suas Jornadas Orientadas por IA
A Quantiphi é especializada em treinamento e ajuste fino de modelos básicos usando o framework NVIDIA NeMo, além de otimizar implantações em escala com a plataforma de software NVIDIA AI Enterprise, mantendo conformidade aos princípios de IA responsável.
SAP
SAP e NVIDIA Aceleram a Adoção de IA Generativa em Aplicações Empresariais, Impulsionando Setores Globais
Os clientes podem aproveitar seus dados empresariais em soluções de nuvem da SAP usando LLMs personalizados implantados com os serviços NVIDIA AI Foundry e os microsserviços NVIDIA NIM.
ServiceNow
Criação de IA Generativa em Toda a TI Empresarial
A ServiceNow desenvolve LLMs personalizados em sua plataforma ServiceNow para permitir a automação inteligente de fluxos de trabalho e aumentar a produtividade em todos os processos de TI empresarial.
Perplexity
Melhore o Desempenho de Modelos para Mecanismos de Pesquisa com Tecnologia de IA
Usando o NVIDIA NeMo, a Perplexity visa personalizar rapidamente modelos de fronteira para melhorar a precisão e a qualidade dos resultados de pesquisa e otimizá-los para menor latência e alto rendimento, proporcionando uma melhor experiência do usuário.
VMware
VMware e NVIDIA Desbloqueiam a IA Generativa para Empresas
O VMware Private AI Foundation com NVIDIA permitirá que empresas personalizem modelos e executem aplicações de IA generativa, incluindo chatbots inteligentes, assistentes, pesquisa e resumo.
Weight & Biases
Depure, Otimize e Monitore Pipelines de LLM
A Weights & Biases capacita equipes que trabalham em casos de uso de IA generativa ou com LLMs a rastrear e visualizar todos os experimentos de engenharia de prompt, capacitando os usuários a depurar e otimizar pipelines de LLM, além de fornecer recursos de monitoramento e capacidade de observação para LLMs.
Writer
Startup Escreve História de Sucesso em IA Generativa com o NVIDIA NeMo
Usando o NVIDIA NeMo, o Writer está criando LLMs que estão auxiliando centenas de empresas a criar conteúdo personalizado para casos de uso empresarial em marketing, treinamento, suporte e muito mais.
Arize
Arize Potencializa Ciclos de Dados de IA com Autoaprimoramento
A plataforma de engenharia e observabilidade de LLMs da Arize integra os microsserviços NVIDIA NeMo para potencializar os ciclos de dados de IA, permitindo o refinamento contínuo de modelos por meio de feedback real. Com o NeMo Customizer, o Evaluator e o Guardrails, a Arize garante que os sistemas baseados em agentes tenham alto desempenho, sejam seguros e estejam alinhados com a evolução das necessidades da empresa. Essa colaboração apoia o desenvolvimento de IA adaptativa que aprende e evolui ao longo do tempo.
DataRobot
Agentes de IA Confiáveis e Prontos para Empresas com NeMo no DataRobot
Com o NVIDIA NeMo incorporado ao DataRobot Enterprise AI Suite, as empresas podem garantir que os sistemas baseados em agentes sejam seguros, estejam em conformidade e estejam baseados em dados específicos da empresa. Essa integração facilita o desenvolvimento de agentes de IA que oferecem respostas precisas e conscientes do contexto, aderindo aos padrões organizacionais.
DataStax
DataStax e NVIDIA Criam Plataforma de Dados e IA
No ano passado, a DataStax fez parceria com a NVIDIA para adotar os microsserviços NVIDIA NeMo para aprimorar a IA generativa, a geração aumentada por recuperação e a pesquisa híbrida em suas ofertas de banco de dados e IA. Os resultados têm sido impressionantes: desempenho 19 vezes superior na taxa de transferência, redução significativa nos custos e melhoria na latência.
Galileo
Galileo e NVIDIA NeMo: Reduzindo os Riscos da IA Baseada em Agentes na Produção
A Galileo integra os microsserviços NVIDIA NeMo para criar ciclos de dados de IA que fortalecem o desempenho, a confiabilidade e a confiança nos agentes. O NeMo adiciona recursos complementares à plataforma Galileo, permitindo o ajuste fino contínuo específico do domínio por meio do NeMo Customizer, a avaliação avançada com o NeMo Evaluator e a proteção das interações de usuários com o NeMo Guardrails. Esses recursos capacitam as equipes de IA a criar, avaliar e monitorar sistemas de IA baseada em agentes, que aprendem e melhoram continuamente em ambientes reais.