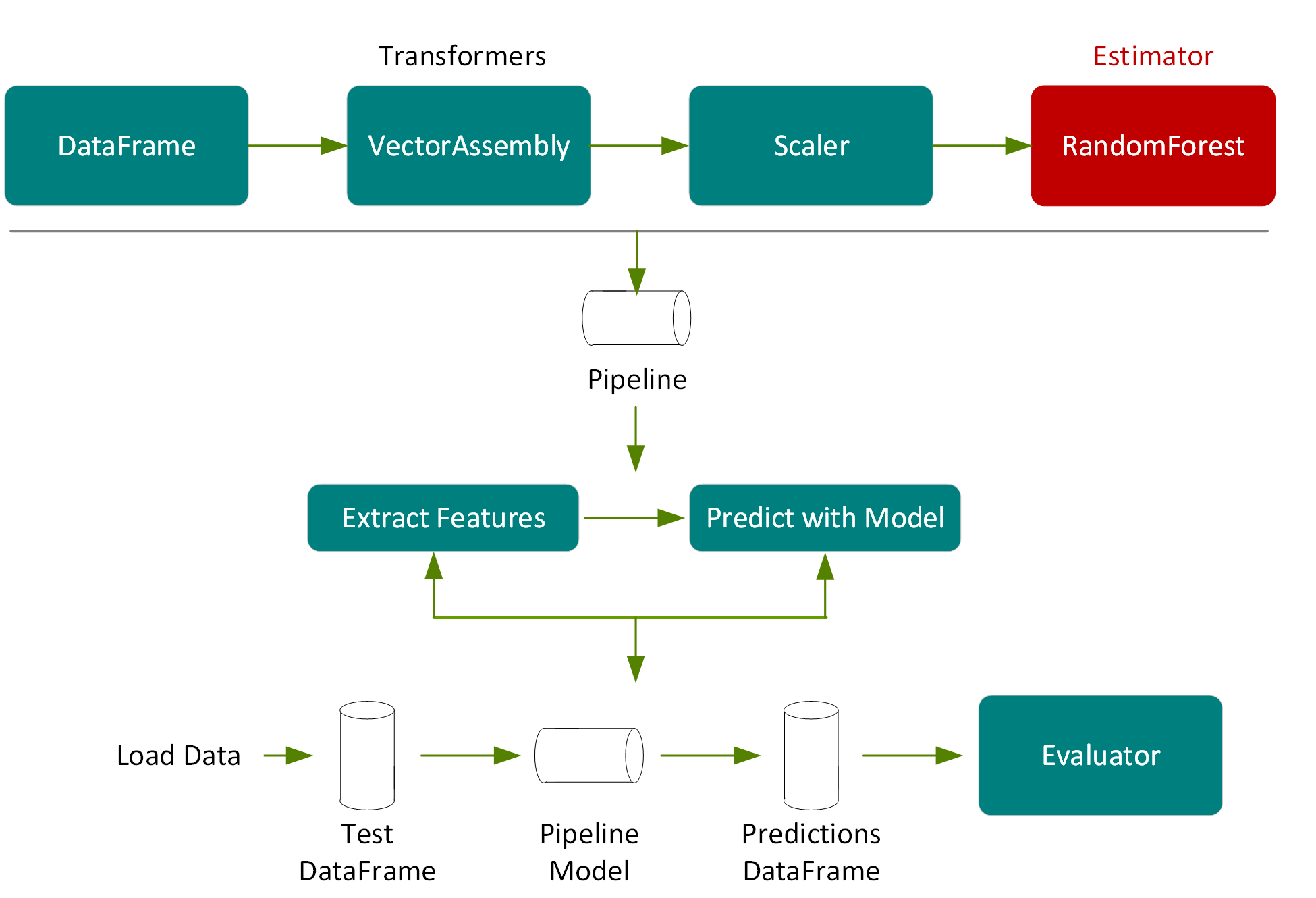
For the features to be used by an ML algorithm, they are transformed and put into feature vectors, which are vectors of numbers representing the value for each feature. Below, a VectorAssembler transformer is used to return a new DataFrame with a label and a vector features column.

// feature column names
val featureNames = Array("passenger_count","trip_distance", "pickup_longitude","pickup_latitude","rate_code","dropoff_longitude", "dropoff_latitude", "hour", "day_of_week","is_weekend")
// create transformer
object Vectorize {
def apply(df: DataFrame, featureNames: Seq[String], labelName: String): DataFrame = {
val toFloat = df.schema.map(f => col(f.name).cast(FloatType))
new VectorAssembler()
.setInputCols(featureNames.toArray)
.setOutputCol("features")
.transform(df.select(toFloat:_*))
.select(col("features"), col(labelName))
}
}
// transform method adds features column
var trainSet = Vectorize(tdf, featureNames, labelName)
var evalSet = Vectorize(edf, featureNames, labelName)
trainSet.take(1)
result:
res8: Array[org.apache.spark.sql.Row] =
Array([[5.0,2.7200000286102295,-73.94813537597656,40.82982635498047,-6.77418944E8,-73.96965026855469,40.79747009277344,10.0,6.0,1.0],11.5])
When using the XGBoost GPU version, the VectorAssembler is not needed.
For the CPU version the num_workers should be set to the number of CPU cores, the tree_method to “hist,” and the features column to the output features column in the Vector Assembler.

lazy val paramMap = Map(
"learning_rate" -> 0.05,
"max_depth" -> 8,
"subsample" -> 0.8,
"gamma" -> 1,
"num_round" -> 500
)
// set up xgboost parameters
val xgbParamFinal = paramMap ++ Map("tree_method" -> "hist", "num_workers" -> 12)
// create the xgboostregressor estimator
val xgbRegressor = new XGBoostRegressor(xgbParamFinal)
.setLabelCol(labelName)
.setFeaturesCol("features")
For the GPU version the num_workers should be set to the number of machines with GPU in the Spark cluster, the tree_method to “gpu_hist,” and the features column to an array of strings containing the feature names.
val xgbParamFinal = paramMap ++ Map("tree_method" -> "gpu_hist",
"num_workers" -> 1)
// create the estimator
val xgbRegressor = new XGBoostRegressor(xgbParamFinal)
.setLabelCol(labelName)
.setFeaturesCols(featureNames)
The following code uses the XGBoostRegressor estimator fit method on the training dataset to train and return an XGBoostRegressor model. We also use a time method to return the time to train the model and we use this to compare the time training with CPU vs. GPU.

object Benchmark {
def time[R](phase: String)(block: => R): (R, Float) = {
val t0 = System.currentTimeMillis
val result = block // call-by-name
val t1 = System.currentTimeMillis
println("Elapsed time [" + phase + "]: " +
((t1 - t0).toFloat / 1000) + "s")
(result, (t1 - t0).toFloat / 1000)
}
}
// use the estimator to fit (train) a model
val (model, _) = Benchmark.time("train") {
xgbRegressor.fit(trainSet)
}
The performance of the model can be evaluated using the eval dataset which has not been used for training. We get predictions on the test data using the model transform method.
The model will estimate with the trained XGBoost model, and then return the fare amount predictions in a new predictions column of the returned DataFrame. Here again, we use the Benchmark time method in order to compare prediction times.

val (prediction, _) = Benchmark.time("transform") {
val ret = model.transform(evalSet).cache()
ret.foreachPartition(_ => ())
ret
}
prediction.select( labelName, "prediction").show(10)
Result:
+-----------+------------------+
|fare_amount| prediction|
+-----------+------------------+
| 5.0| 4.749197959899902|
| 34.0|38.651187896728516|
| 10.0|11.101678848266602|
| 16.5| 17.23284912109375|
| 7.0| 8.149757385253906|
| 7.5|7.5153608322143555|
| 5.5| 7.248467922210693|
| 2.5|12.289423942565918|
| 9.5|10.893491744995117|
| 12.0| 12.06682014465332|
+-----------+------------------+
The RegressionEvaluator evaluate method calculates the root mean square error, which is the square root of the mean squared error, from the prediction and label columns.

val evaluator = new RegressionEvaluator().setLabelCol(labelName)
val (rmse, _) = Benchmark.time("evaluation") {
evaluator.evaluate(prediction)
}
println(s"RMSE == $rmse")
Result:
Elapsed time [evaluation]: 0.356s
RMSE == 2.6105287283128353