
Traitement intelligent des documents
Transformez des documents, des rapports, des présentations, des PDF, des pages Web et des feuilles de calcul complexes en informations exploitables et consultables.
Aperçu : De l'utilité du traitement intelligent des documents
Lire, comprendre et extraire des informations sur des documents pour automatiser la prise de décision
Le traitement intelligent des documents aide les institutions à transformer divers contenus multimodaux (tels que des rapports, des contrats, des documents, des politiques et des documents de recherche) en informations structurées et consultables en identifiant les informations les plus importantes.
Le traitement de documents avec les modèles et les bibliothèques ouverts NVIDIA Nemotron combine fonctionnalités d'extraction haute fidélité, de récupération multimodale et de génération fondée sur les sources. Les équipes sont en capacité de créer des agents d'IA qui lisent des documents comme des experts tout en préservant la traçabilité jusqu'à la source d'origine.
Avantages
Ces solutions couvrent une multitude de domaines afin d'aider les équipes d'analystes, de chercheurs et d'utilisateurs finaux à obtenir de meilleurs résultats.
- Découverte plus rapide d'informations : automatisez l'examen de rapports, de contrats et de politiques denses afin que les équipes obtiennent des réponses en quelques secondes au lieu de quelques heures.
- Charges de travail de documents évolutives : traitez des millions de PDF, de pages Web et de feuilles de calcul en parallèle à l'arrivée de nouvelles données, sans avoir à recruter du personnel en conséquence.
- Qualité de décision supérieure : préservez les tableaux, les graphiques et les figures pour permettre aux agents d'IA de raisonner sur des preuves identiques à celles en lesquelles les experts ont confiance aujourd'hui.
- Auditabilité et conformité : ancrez chaque réponse dans des pages et des tableaux cités pour répondre à des exigences réglementaires et d'audit interne strictes.
- Impact intersectoriel : prenez en charge divers workflows dans les domaines de la finance, du droit et de la science, avec un pipeline intelligent qui s'adapte à différents types de documents et domaines.
Liens rapides
Edison Scientific : Kosmos AI Scientist synthétise des dizaines de milliers de documents de recherche
Edison Scientific, une filiale de FutureHouse, développe Kosmos, un chercheur en IA capable de réaliser des découvertes autonomes. Kosmos est un système multi-agents avec un agent conçu spécialement pour répondre aux questions sur la littérature scientifique, les essais cliniques et les brevets. Basé sur Nemotron Parse, l'agent spécialisé dans la littérature parcourt de manière autonome plus de 175 millions de documents pour répondre aux questions des chercheurs, aidant ainsi plus de 50 000 scientifiques dans leur travail de découverte.
Pour chaque page, Nemotron Parse renvoie du texte sémantique pour l'indexation et la recherche, puis segmente les régions d'image visuelle pour le raisonnement LLM multimodal.
Les articles scientifiques ne sont pas rédigés selon une norme commune et incluent souvent des figures complexes susceptibles d'être mal interprétées. Nemotron Parse est essentiel car il identifie et analyse des tableaux, des figures et du texte pertinents dans un PDF, qu'un LLM pour ensuite générer des réponses pertinentes aux requêtes des utilisateurs.
L'agent de littérature d'Edison contribue à :
- Réduire le travail manuel en analysant de grands volumes de données
- Accélérer l'analyse en extrayant des informations clés
- Améliorer la qualité des décisions prises par les outils et les humains
Comprendre rapidement et précisément la littérature scientifique est un composant essentiel qui a permis à Kosmos de mener à bien 6 mois de recherche en une journée, avec une reproductibilité de 80 %.
Liens rapides
Implémentation technique
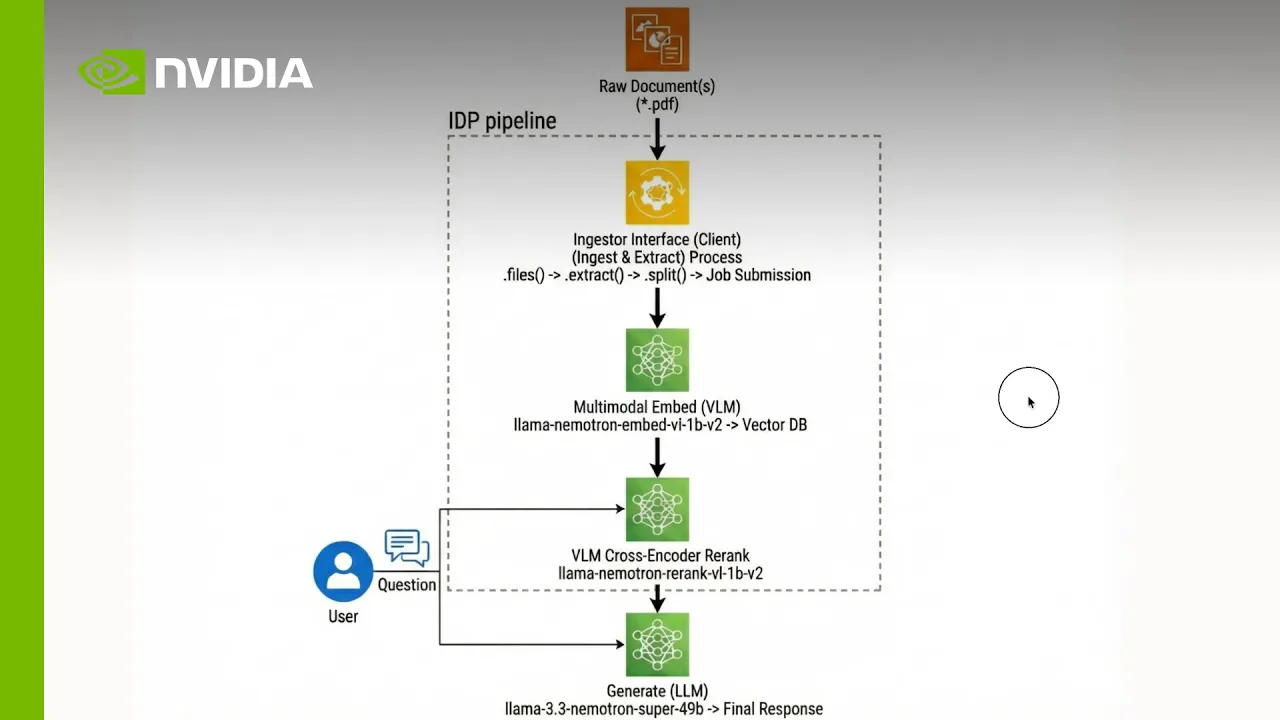
Diagramme d'architecture

Un pipeline de traitement intelligent de documents s'articule autour de trois composants principaux : l'extraction, l'intégration et l'indexation, ainsi que le reclassement pour la génération de réponses.
Les développeurs peuvent configurer, étendre et déployer des solutions avec des modèles ouverts, NeMo Retriever et des microservices NIM.
1. Extraction : transformez des documents complexes en données structurées
Utilisez la bibliothèque NeMo Retriever avec des services d'analyse et d'OCR auto-hébergés ou hébergés par NVIDIA pour ingérer des PDF, des pages Web et d'autres documents multimodaux et les convertir en unités structurées telles que des fragments de texte, des tableaux Markdown et des graphiques recadrés, tout en préservant la mise en page et la sémantique. Cette étape permet de débloquer du contenu riche en conservant les tableaux sous forme de tableaux et les figures sous forme d'images, produisant ainsi des sorties JSON que les modèles de récupération et de génération en aval peuvent utiliser de manière fiable.
2. Intégration et indexation : rendre le contenu consultable à grande échelle
Insérez des éléments extraits dans des modèles d'intégration multimodaux Nemotron afin d'encoder du texte, des tableaux et des graphiques dans des vecteurs denses adaptés à la récupération de documents. Stockez ces vecteurs et les métadonnées associées dans une base de données vectorielle telle que Milvus, afin de permettre une recherche sémantique en quelques millisecondes sur des millions d'éléments de document, tout en maintenant votre base de connaissances à jour en continu à mesure que de nouveaux contenus arrivent.
3. Reclassement et génération de réponses fondées sur les sources : fournissez des réponses citées et haute fidélité
Récupérez les top-K candidats à partir de l'IndeX vectoriel et appliquez le reclassement des codeurs croisés Nemotron pour donner la priorité aux passages, aux tableaux et aux figures qui répondent le mieux à la question d'un utilisateur. Transmettez ce contexte reclassé à un modèle de génération Nemotron, qui produit des réponses ancrées avec des citations explicites renvoyant aux pages et aux graphiques d'origine, afin que les équipes commerciales, financières et scientifiques puissent faire confiance à chaque décision prise en charge par le système et l'auditer.
Aperçu du code pour la création d'un pipeline de traitement de documents intelligent à l'aide de technologies Nemotron ouvertes
Liens rapides
Écosystème de partenaires
Liens rapides
FAQ
Un pipeline NVIDIA RAG de production inclut une base de données vectorielle et des microservices NIM conteneurisés ou un déploiement basé sur Kubernetes pour faire évoluer l'extraction, l'intégration et la récupération sur de grands volumes de documents. Pour les déploiements auto-hébergés, choisissez des GPU NVIDIA avec une VRAM suffisante ; sinon, les points de terminaison hébergés peuvent réduire les exigences d'infrastructure locale. Vous devrez également ajuster les paramètres d'extraction (tels que le format de sortie des tableaux et le fractionnement au niveau de la page), choisir des modèles d'extraction, d'intégration et de ré-ordonnancement Nemotron appropriés, et instrumenter le système pour mesurer le débit, la latence et la qualité des citations afin de respecter les contrats de niveau de service (SLA) d'entreprise.
Nemotron Parse utilise une architecture vision-langage avec un ancrage spatial pour détecter et extraire du texte, des tableaux, des graphiques et des éléments de mise en page, afin de produire des résultats structurés et lisibles par machine plutôt que du texte brut. Il préserve la structure des tableaux, l'ordre de lecture et les classes sémantiques, améliorant ainsi considérablement la précision sur des benchmarks exigeants et rendant la récupération et le raisonnement en aval sur des PDF, des scans et des rapports complexes beaucoup plus fiables. Ces sorties structurées peuvent également prendre en charge un découpage plus sémantique, ce qui permet aux systèmes de récupération de diviser les documents selon des limites de contenu significatives plutôt que selon des fenêtres de texte arbitraires.
Réponse : dans un pipeline RAG, l'étape d'extraction façonne la qualité et la structure des preuves disponibles pour la récupération. Utilisez PDFium pour les fichiers PDF créés numériquement lorsque le volume de traitement est prioritaire, l'OCR lorsque vous souhaitez une extraction visuelle alliant rapidité et précision, et Nemotron Parse lorsque la mise en page et la structure du document sont plus riches, ce qui améliore la qualité du découpage en segments et de la recherche. Dans NeMo Retriever, choisir le chemin d'extraction OCR permet d'acheminer l'extraction de documents via le service OCR NeMo Retriever.
En bref, PDFium est idéal pour les fichiers PDF créés numériquement, l'OCR pour allier vitesse et extraction visuelle, et Nemotron Parse pour privilégier la fidélité de mise en page et la structure sémantique.
Liens rapides