Inferenza
NVIDIA Triton Inference Server
Distribuisci, esegui e scala l'IA per qualsiasi applicazione su qualsiasi piattaforma.
Inferenza per ogni carico di lavoro IA
Esegui l'inferenza su modelli di machine learning o di deep learning addestrati partendo da qualsiasi framework su qualsiasi processore, GPU, CPU o altro, con NVIDIA Triton™ Inference Server. Incluso nella piattaforma NVIDIA AI e disponibile con NVIDIA AI Enterprise, Triton Inference Server è un software open source che standardizza la distribuzione e l'esecuzione dei modelli IA su ogni carico di lavoro.
Vantaggi di Triton Inference Server

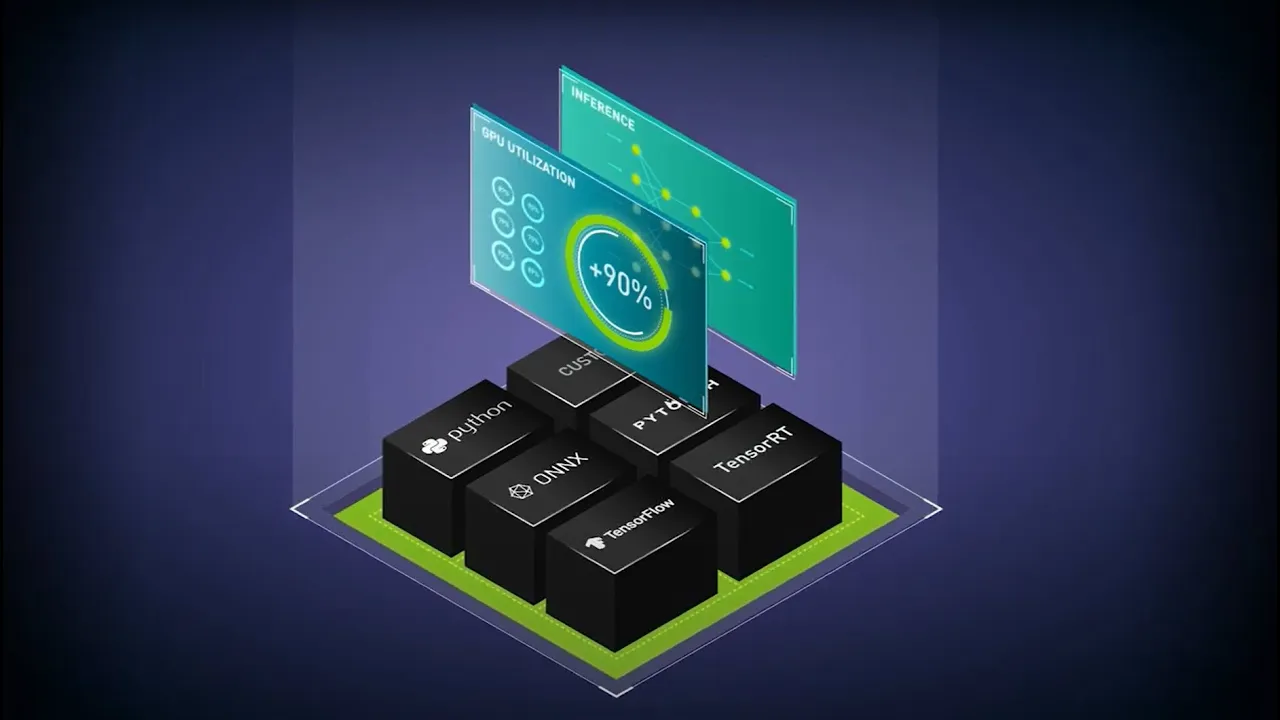
Supporta tutti i framework di training e inferenza
Distribuisci modelli IA su uno dei principali framework con Triton Inference Server, inclusi TensorFlow, PyTorch, Python, ONNX, NVIDIA® TensorRT™, RAPIDS™ cuML, XGBoost, scikit-learn RandomForest, OpenVINO, custom C++ e non solo.

Inferenza ad alte prestazioni su qualsiasi piattaforma
Massimizza il throughput e l'utilizzo con batch dinamici, esecuzione simultanea, configurazione ottimizzata e streaming di audio e video. Triton Inference Server supporta tutte le GPU NVIDIA, le CPU x86 e Arm e AWS Inferentia.

Open source e progettato per DevOps e MLOps
Integra Triton Inference Server nelle soluzioni DevOps e MLOps come Kubernetes per la scalabilità e Prometheus per il monitoraggio. È possibile utilizzarlo anche in tutte le principali piattaforme IA e MLOps su cloud e in locale.

Sicurezza di livello enterprise, gestibilità e stabilità delle API
NVIDIA AI Enterprise, con NVIDIA Triton Inference Server, è una piattaforma software IA sicura e pronta per la produzione, progettata per accelerare il time-to-value con supporto, sicurezza e stabilità delle API.
Esplora le funzionalità e gli strumenti di NVIDIA Triton Inference Server

Modelli linguistici di grandi dimensioni
Triton offre bassa latenza ed elevata produttività per l'inferenza di modelli linguistici di grandi dimensioni (LLM). Supporta TensorRT-LLM, una libreria open source per la definizione, l'ottimizzazione e l'esecuzione di LLM per l'inferenza in produzione.

Insiemi di modelli
Triton Model Ensembles consente di eseguire carichi di lavoro IA con più modelli, pipeline e fasi di pre e post-elaborazione. Consente di eseguire diverse parti dell'insieme su CPU o GPU e supporta l'uso di più framework all'interno dell'insieme.

NVIDIA PyTriton
PyTriton consente agli sviluppatori Python di introdurre Triton con una singola riga di codice e di utilizzarlo per elaborare modelli, semplici funzioni di elaborazione o interi flussi di inferenza, per accelerare la creazione di prototipi e il test.

NVIDIA Triton Model Analyzer
Model Analyzer riduce i tempi necessari per trovare la configurazione ottimale di distribuzione del modello, ad esempio dimensioni batch, precisione e istanze di esecuzione simultanee. Aiuta a selezionare la configurazione ottimale per soddisfare i requisiti di latenza, produttività e memoria delle applicazioni.
Principali clienti in tutti i settori
-
Cliente
-
Integrazioni dell'ecosistema
Inizia con NVIDIA Triton
Usa gli strumenti giusti per distribuire, eseguire e scalare l'IA per qualsiasi applicazione su qualsiasi piattaforma.
Inizia a sviluppare con codice o container
Per gli interessati all'accesso al codice open-source di Triton e ai container per lo sviluppo, sono disponibili due opzioni per iniziare a costo zero:
Try Before You Buy
For enterprises looking to try Triton before purchasing NVIDIA AI Enterprise for production, there are two options to get started for free:
Risorse
-
Videos
-
Formazione
-
Blogs
-
Sessioni
-
Testimonianze dei clienti
-
Community


















Fasi successive
Pronto per iniziare?
Usa gli strumenti giusti per distribuire, eseguire e scalare l'IA per qualsiasi applicazione su qualsiasi piattaforma o esplora altre risorse per sviluppatori.
Contattaci
Parla con un esperto di prodotti NVIDIA per passare dal progetto pilota alla produzione con sicurezza, stabilità API e supporto con NVIDIA AI Enterprise.
Ricevi le novità su NVIDIA Triton Inference Server
Iscriviti per ricevere le ultime notizie, gli aggiornamenti e altro da NVIDIA.