Zillow는 미국에서 부동산 정보의 가장 큰 시장 중 하나이며 영향력 있는 머신 러닝(ML)의 대표적인 예입니다. Zillow Research는 각 부동산에 대한 수백 개의 데이터 포인트를 분석하여 주택 값을 예측하고 시장 변화를 예측하는 ML 모델을 사용합니다. 이 챕터에서는 Apache Spark ML 랜덤 포레스트 회귀를 사용하여 지역의 평균 주택 판매 가격을 예측하는 방법을 다룹니다. 현재 Spark ML에서 XGBoost만 GPU 가속화되어 있으며, 이 내용은 다음 챕터에서 다룰 것입니다.
Apache Spark 머신 러닝을 사용하여 주택 가격 예측하기
분류 및 회귀
분류 및 회귀는 관리형 머신 러닝 알고리즘의 두 가지 범주입니다. 예측 분석이라고도 하는 관리형 ML은 알고리즘을 사용하여 레이블이 지정된 데이터에서 패턴을 찾은 다음 이러한 패턴을 인식하는 모델을 사용하여 새 데이터의 레이블을 예측합니다. 분류 및 회귀 알고리즘은 레이블(대상 결과라고도 함)과 특성(속성이라고도 함)이 있는 데이터세트에서 해당 데이터 특성에 따라 새 데이터에 레이블을 지정하는 방법을 학습합니다.
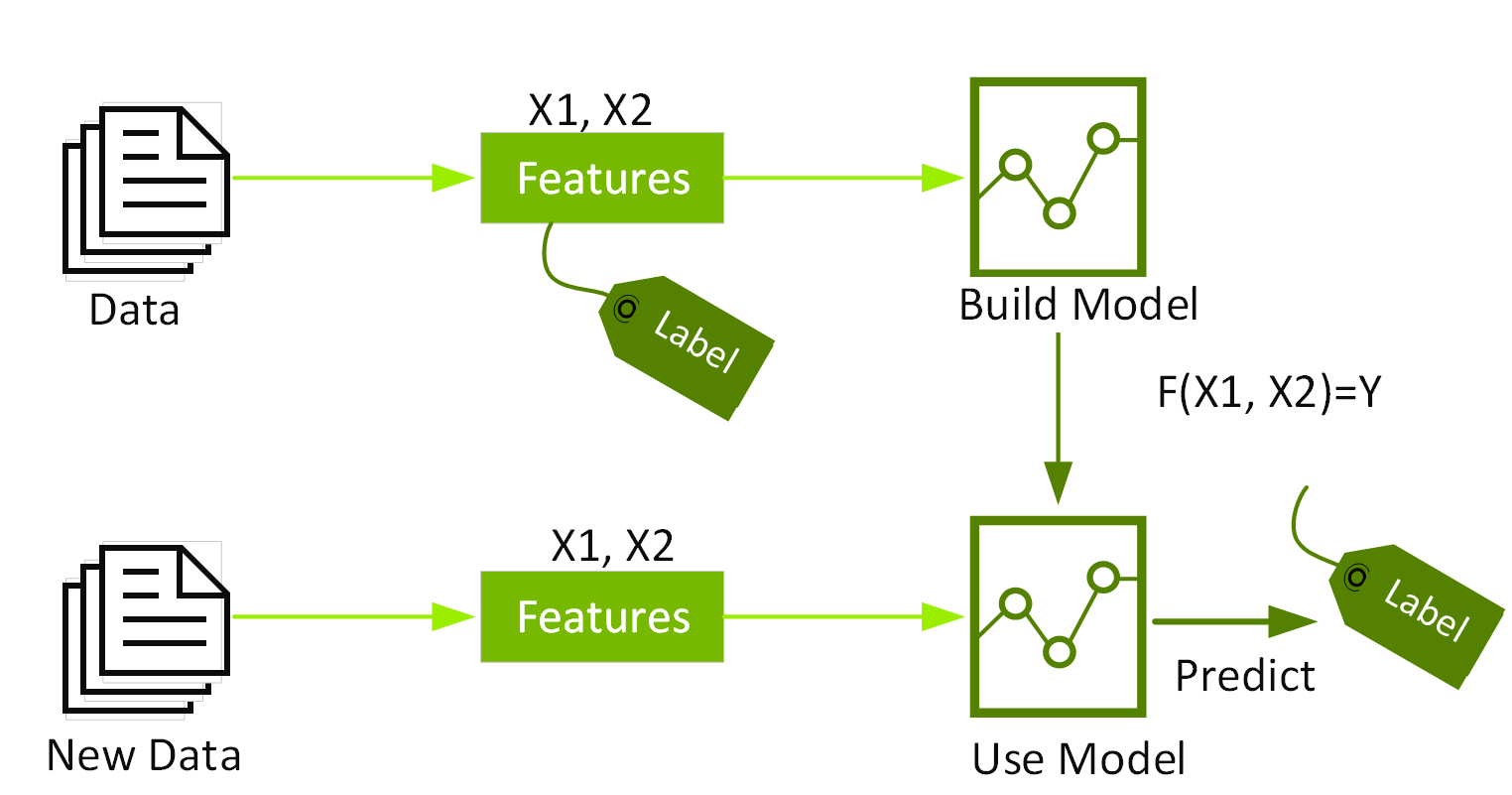
분류는 신용 카드 거래의 합법성 여부 등 항목이 속한 범주를 식별합니다. 회귀는 주택 가격과 같은 지속적인 숫자 값을 예측합니다.
회귀
회귀는 대상 결과 종속 변수(레이블)와 하나 이상의 독립적인 변수(특성) 간의 관계를 예측합니다. 회귀는 레이블과 특성 변수 간의 관계의 강도를 분석하고, 하나 이상의 특성 변수가 조정되면 레이블이 얼마나 많이 변경되는지 판단하고, 레이블과 특성 변수 간의 추세를 예측하는 데 사용할 수 있습니다.
이전 주택 가격 및 주택의 특징(평방 피트, 침실 수, 위치 등)을 감안하여 주택 가격의 선형 회귀 예시를 살펴보겠습니다.
- 예측하려는 것은 무엇인가요?
집 가격은 레이블입니다. - 예측하는 데 사용할 수 있는 데이터 속성은 무엇인가요?
회귀 모델을 구축하기 위해, 레이블과의 관계가 가장 강하며 예측에 가장 많이 기여하는 특성을 추출합니다.
다음 예에서는 집의 크기를 사용합니다.
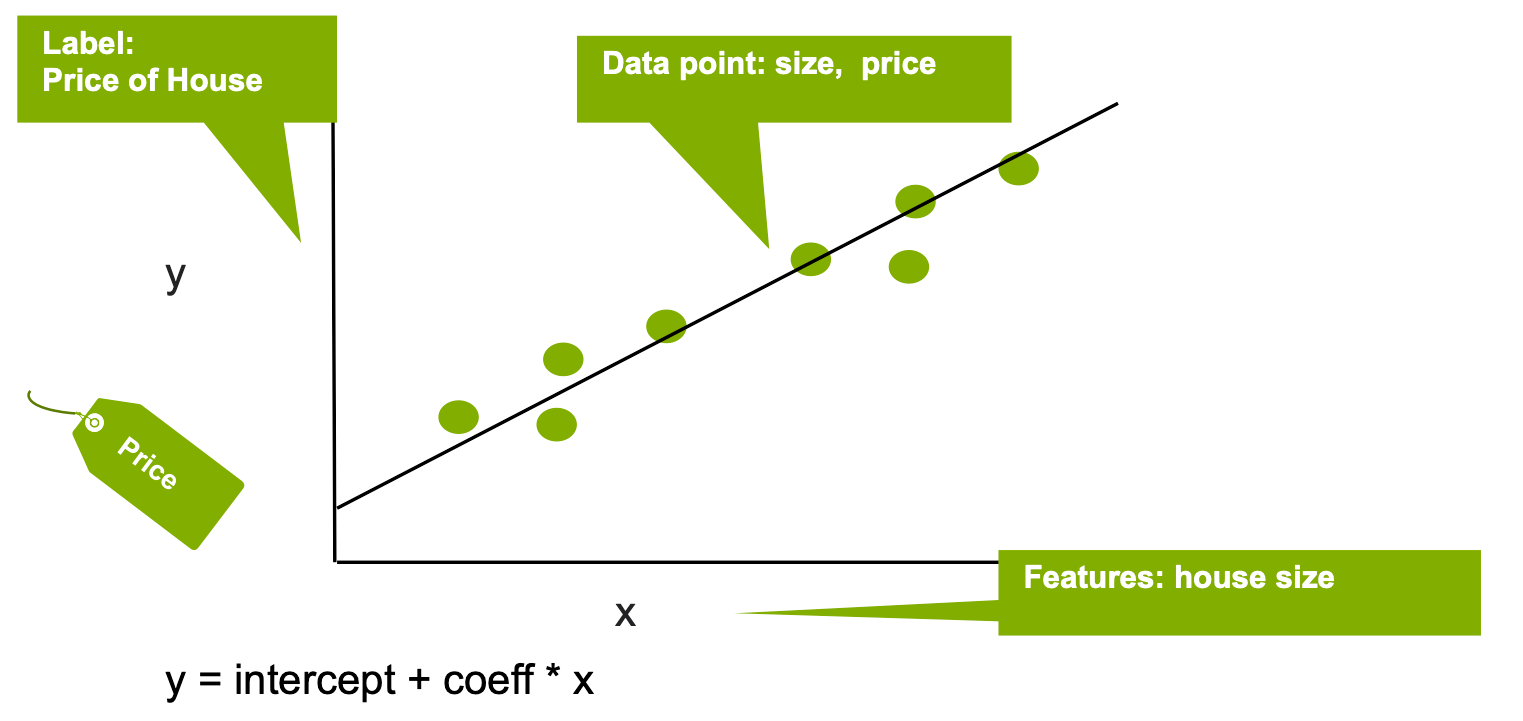
선형 회귀는 Y "레이블"과 X "특성", in this case the relationship between the house price and size, with the equation: Y = 절편 + (계수 * X) + 오류 사이의 관계를 모델화합니다. 계수는 특성이 레이블에 미치는 영향을 측정하며, 이 경우 집 크기가 가격에 미치는 영향을 측정합니다.
다중 선형 회귀는 둘 이상의 "특성"과 "레이블" 사이의 관계를 모델화합니다. 예를 들어, 가격과 집 크기, 침실 수 및 욕실 수 사이의 관계를 모델화하려는 경우 다중 선형 회귀 함수는 다음과 같습니다.
Yi = β0 + β1X1 + β2X2 + · · · + βp Xp + Ɛ
Price = 절편 + (계수1 크기) + (계수2 침실) + (계수3 * 욕실) + 오류.
계수는 각 특성이 가격에 미치는 영향을 측정합니다.
의사결정 트리
의사결정 트리는 if-then-else 패턴을 따르는 규칙 집합을 평가하여 레이블을 예측하는 모델을 만듭니다. 그 동안의 다른 기능 질문은 노드이며 트리의 "true" 또는 "false"라는 대답은 하위 노드의 가지입니다.
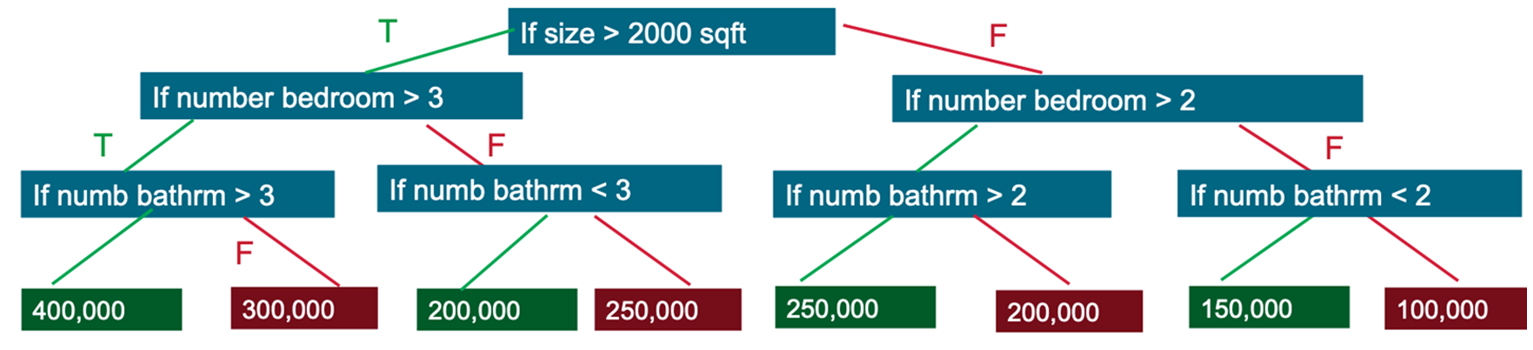
의사결정 트리 모델은 올바른 결정을 내릴 확률을 평가하는 데 필요한 참/거짓 질문의 최소 수를 추정합니다. 의사결정 트리는 범주, 범주의 확률 또는 회귀를 예측하여 연속 숫자 값을 예측하기 위해 분류에 사용할 수 있습니다. 다음은 주택 가격을 예측하는 단순화된 의사결정 트리의 예입니다.
- Q1: 집의 크기가 >2,000sqft 경우
- T:Q2: 침실 수가 >3인 경우
- T:Q3: 욕실 수가 >3인 경우
- T: Price=$400,000
- F: Price=$200,000
- T:Q3: 욕실 수가 >3인 경우
- T:Q2: 침실 수가 >3인 경우
랜덤 포레스트
앙상블 학습 알고리즘은 여러 머신 러닝 알고리즘을 결합하여 더 나은 모델을 얻습니다. 랜덤 포레스트는 분류 및 회귀를 위한 인기 있는 앙상블 학습 방법입니다. 알고리즘은 트레이닝 단계에서 다양한 데이터 하위 집합을 기반으로 여러 의사결정 트리로 구성된 모델을 빌드합니다. 예측은 모든 트리의 결과를 합쳐 분산을 줄이고 예측 정확도를 향상하여 이루어집니다. 랜덤 포레스트 분류의 경우 레이블은 대부분의 트리에서 예측하는 클래스로 예측됩니다. 랜덤 포레스트 회귀의 경우 레이블은 개별 트리의 평균 회귀 예측입니다.
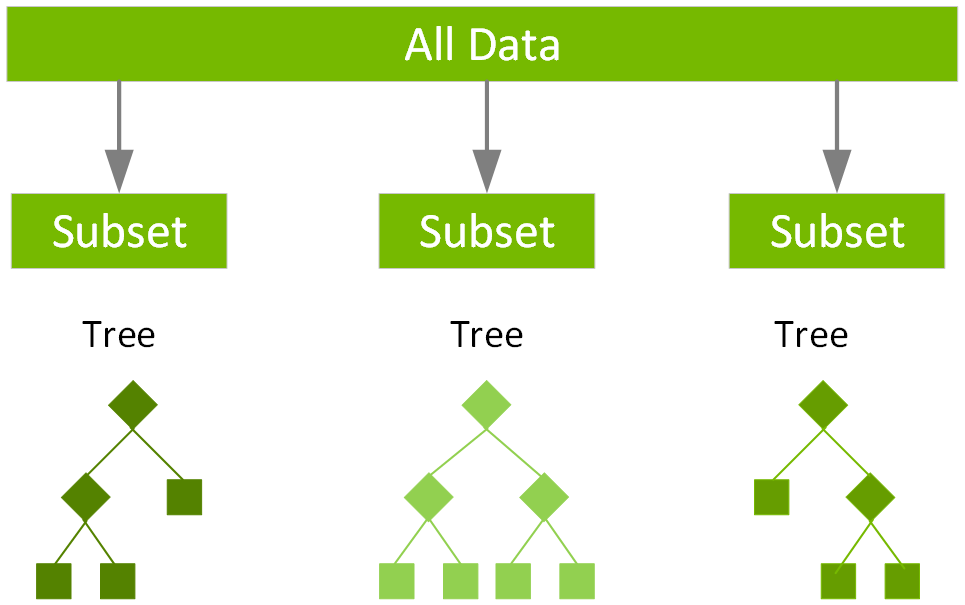
Spark는 회귀에 대해 다음 알고리즘을 제공합니다.
- 선형 회귀
- 일반화된 선형 회귀
- 의사결정 트리 회귀
- 랜덤 포레스트 회귀
- 그래디언트 부스트 트리 회귀
- XGBoost 회귀
- 생존 회귀
- 등장성 회귀
머신 러닝 워크플로우
머신 러닝은 다음과 관련된 반복적인 프로세스입니다.
- 중요한 기능과 라벨을 추출하기 위한 기록 데이터의 분석 및 ETL(추출, 변환, 로딩).
- 모델을 구축하기 위해 ML 알고리즘의 결과를 트레이닝, 테스트 및 평가.
- 프로덕션에서 모델을 새 데이터와 함께 사용하여 예측을 수행.
- 새 데이터로 모니터링 및 모델 업데이트.
Spark ML 파이프라인 사용하기
ML 알고리즘에서 사용할 특성과 레이블은 각 특성의 값을 나타내는 숫자의 벡터인 특성 벡터에 넣어야 합니다. 특성 벡터는 ML 알고리즘의 결과를 학습, 테스트 및 평가하여 최상의 모델을 구축하는 데 사용됩니다.
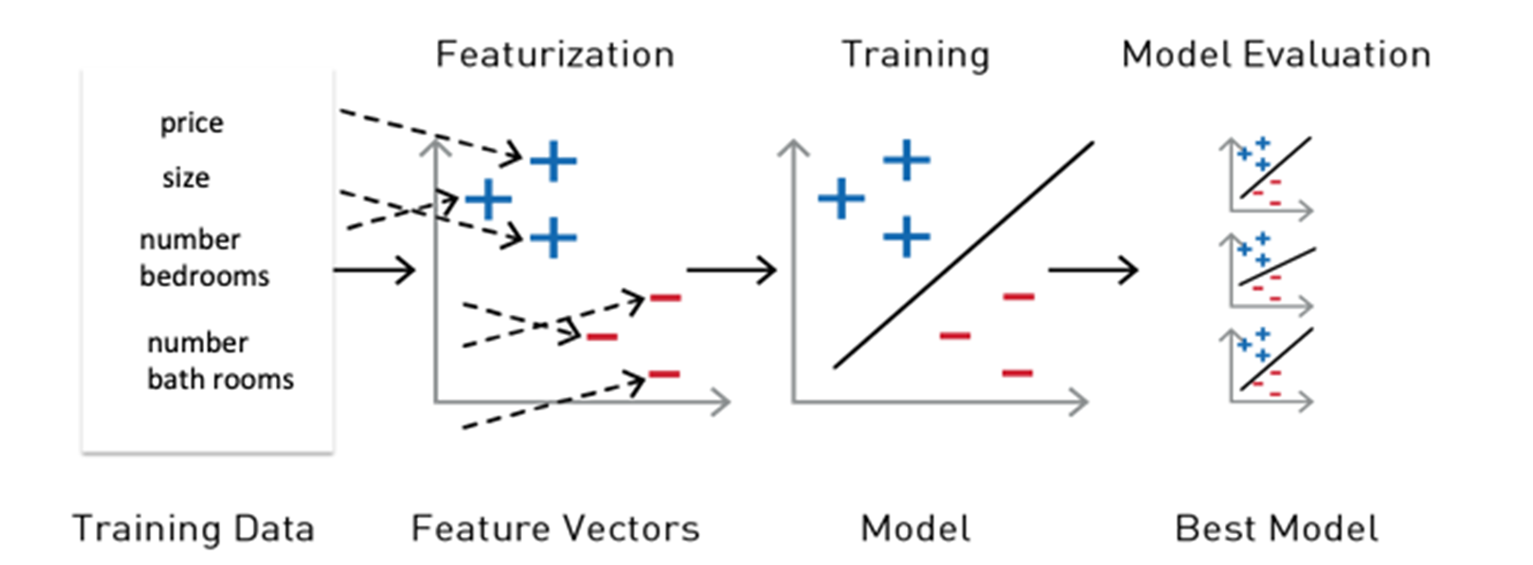
참조 학습 Spark
Spark ML은 ML 파이프라인 또는 워크플로우를 구축하기 위해 DataFrames 위에 구축된 균일한 고급 API 세트를 제공합니다. DataFrames 위에 ML 파이프라인을 구축하면 데이터 조작을 위한 SQL의 용이성을 통해 분할된 데이터 처리의 확장성이 제공됩니다.
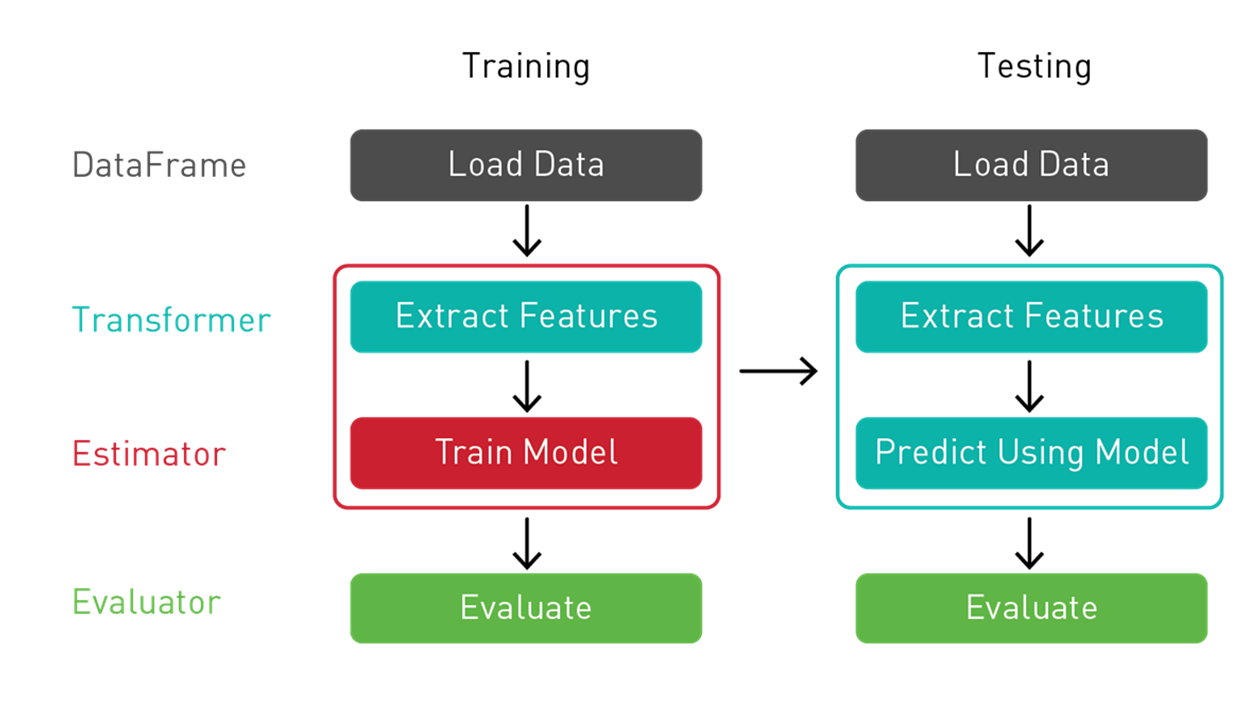
Spark ML 파이프라인을 사용하여 트랜스포머를 통해 데이터를 전달하고 특성, 모델을 생성하기 위한 추정자 및 모델의 정확도를 측정하기 위한 평가자를 추출합니다.
- 트랜스포머: 트랜스포머는 하나의 DataFrame을 다른 데이터프레임으로 변환하는 알고리즘입니다. 트랜스포머를 사용하여 특성 벡터 열이 있는 DataFrame을 만들 것입니다.
- 추정자: 추정자는 DataFrame에 맞게 트랜스포머를 생성할 수 있는 알고리즘입니다. 추정자를 사용하여 모델을 트레이닝하고 특성 벡터 열이 있는 DataFrame에 예측 열을 추가할 수 있는 모델 트랜스포머를 반환합니다.
- 파이프라인: 파이프라인은 ML 워크플로우를 지정하기 위해 여러 트랜스포머와 추정자를 함께 연결합니다.
- 평가자: 평가자는 레이블 및 예측 DataFrame 열에서 학습된 모델의 정확도를 측정합니다.
예시 사용 사례 데이터세트
이 예제에서는 StatLib 리포지토리의 캘리포니아 주택 가격 데이터세트를 사용할 것입니다. 이 데이터세트에는 1990년 캘리포니아 인구 조사의 데이터를 기반으로 하는 20,640개의 레코드가 포함되어 있으며 각 레코드는 지리적 블록을 나타냅니다. 다음 목록은 데이터세트의 특성에 대한 설명을 제공합니다.
- 평균 주택 값: 블록 내 가구에 대한 평균 주택 값(1천 달러 단위).
- 경도: 동/서 측정, 값이 높을수록 서쪽입니다.
- 위도: 남/북 측정, 값이 높을수록 북쪽입니다.
- 주택 평균 연식: 블록 내에서 집의 평균 연식, 낮을수록 새 집입니다.
- 총 방 수: 블록 내의 총 방 수입니다.
- 총 침실 수: 블록 내의 총 침실 수입니다.
- 인구: 블록 내에 거주하는 총 사람 수입니다.
- 가구: 블록 내의 총 가구 수입니다.
- 중위 소득: 주택 블록 내 가구의 중위 소득(1만 달러 단위).
To build a model, you extract the features that most contribute to the prediction. In order to make some of the features more relevant for predicting the median house value, instead of using totals we’ll calculate and use these ratios: rooms per house=total rooms/households, people per house=population/households, and bedrooms per rooms=총 침실/총 방 수.
이 시나리오에서는 다음 레이블 및 특성에서 랜덤 포레스트 회귀를 사용합니다.
- 레이블 → 중위 집값
- 특성 → {"중위 나이", "중위 소득", "집당 방 수", "집당 인구 수", "집당 침실 수", "경도", "위도" }
파일에서 DataFrame으로 데이터 로드

첫 번째 단계는 데이터를 DataFrame에 로딩하는 것입니다. 다음 코드에서는 데이터세트에 로딩할 데이터 소스 및 스키마를 지정합니다.
import org.apache.spark._
import org.apache.spark.ml._
import org.apache.spark.ml.feature._
import org.apache.spark.ml.regression._
import org.apache.spark.ml.evaluation._
import org.apache.spark.ml.tuning._
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.ml.Pipeline
val schema = StructType(Array(
StructField("longitude", FloatType,true),
StructField("latitude", FloatType, true),
StructField("medage", FloatType, true),
StructField("totalrooms", FloatType, true),
StructField("totalbdrms", FloatType, true),
StructField("population", FloatType, true),
StructField("houshlds", FloatType, true),
StructField("medincome", FloatType, true),
StructField("medhvalue", FloatType, true)
))
var file ="/path/cal_housing.csv"
var df = spark.read.format("csv").option("inferSchema", "false").schema(schema).load(file)
df.show
결과:
+---------+--------+------+----------+----------+----------+--------+---------+---------+
|longitude|latitude|medage|totalrooms|totalbdrms|population|houshlds|medincome|medhvalue|
+---------+--------+------+----------+----------+----------+--------+---------+---------+
| -122.23| 37.88| 41.0| 880.0| 129.0| 322.0| 126.0| 8.3252| 452600.0|
| -122.22| 37.86| 21.0| 7099.0| 1106.0| 2401.0| 1138.0| 8.3014| 358500.0|
| -122.24| 37.85| 52.0| 1467.0| 190.0| 496.0| 177.0| 7.2574| 352100.0|
+---------+--------+------+----------+----------+----------+--------+---------+---------+
In the following code example, we use the DataFrame withColumn() transformation, to add columns for the ratio features: rooms per house=total rooms/households, people per house=population/households, and bedrooms per rooms=총 침실/총 방 수. 그런 다음 DataFrame을 캐시하고 SQL 사용의 성능과 용이성을 위해 임시 보기를 만듭니다.
// 특성에 대한 비율 생성
df = df.withColumn("roomsPhouse", col("totalrooms")/col("houshlds"))
df = df.withColumn("popPhouse", col("population")/col("houshlds"))
df = df.withColumn("bedrmsPRoom", col("totalbdrms")/col("totalrooms"))
df=df.drop("totalrooms","houshlds", "population" , "totalbdrms")
df.cache
df.createOrReplaceTempView("house")
spark.catalog.cacheTable("house")
요약 통계
Spark DataFrames에는 통계 처리를 위한 몇 가지 기본 제공 기능이 포함되어 있습니다. describe() 함수는 숫자 열에 대한 요약 통계 계산을 수행하고 DataFrame으로 반환합니다. 다음 코드에는 레이블 및 일부 특성에 대한 몇 가지 통계가 나와 있습니다.
df.describe("medincome","medhvalue","roomsPhouse","popPhouse").show
결과:
+-------+------------------+------------------+------------------+------------------+
|summary| medincome| medhvalue| roomsPhouse| popPhouse|
+-------+------------------+------------------+------------------+------------------+
| count| 20640| 20640| 20640| 20640|
| mean|3.8706710030346416|206855.81690891474| 5.428999742190365| 3.070655159436382|
| stddev|1.8998217183639696|115395.61587441359|2.4741731394243205| 10.38604956221361|
| min| 0.4999| 14999.0|0.8461538461538461|0.6923076923076923|
| max| 15.0001| 500001.0| 141.9090909090909|1243.3333333333333|
+-------+------------------+------------------+------------------+------------------+
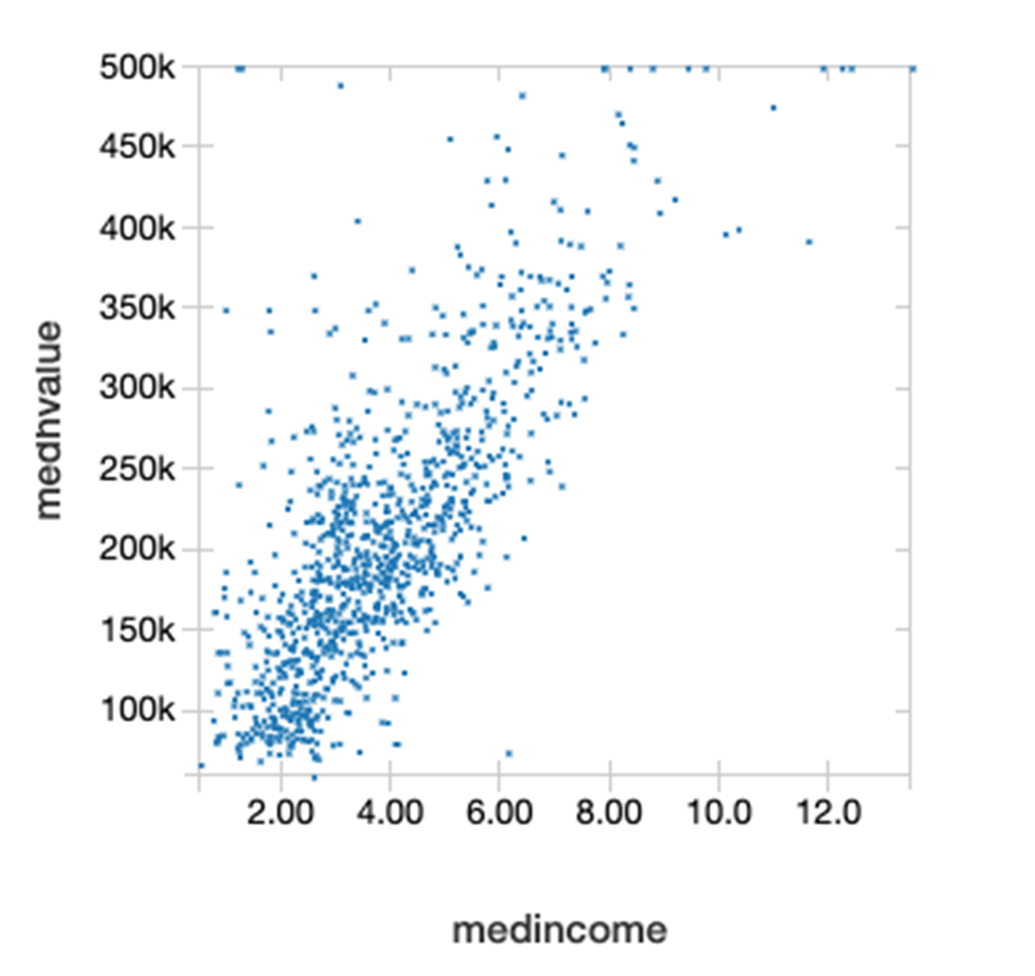
DataFrame Corr() 함수는 DataFrame의 두 열의 Pearson 상관 관계 계수를 계산합니다. 이는 공분산 방법에 따라 두 변수 간의 통계적 관계를 측정합니다. 상관 계수 값은 1에서 -1 사이이며, 여기서 1은 완벽한 양수 관계, -1은 완벽한 음수 관계를 나타내며 0은 아무런 관계가 없음을 나타냅니다. 아래는 중위 소득과 중위 집값이 양의 상관 관계를 가지고 있음을 알 수 있습니다.
df.select(corr("medhvalue","medincome")).show()
+--------------------------+
|corr(medhvalue, medincome)|
+--------------------------+
| 0.688075207464692|
+--------------------------+
Y축의 중위 집값과 X축의 중위 소득의 다음 산점도는 이 둘이 서로 선형적으로 연관되어 있음을 나타냅니다.
다음 코드는 DataFrame randomSplit 방법을 사용하여 데이터세트를 무작위로 두 개로 분할하며 트레이닝에 80%, 테스트에 20%로 분할합니다.
val Array(trainingData, testData) = df.randomSplit(Array(0.8, 0.2), 1234)
특성 추출 및 파이프라이닝
다음 코드는 VectorAssembler(트랜스포머)를 생성하며, 이는 파이프라인에서 지정된 열 목록을 단일 특성 벡터 열에 결합하는 데 사용됩니다.
val featureCols = Array("medage", "medincome", "roomsPhouse", "popPhouse", "bedrmsPRoom", "longitude", "latitude")
//특성을 특성 벡터 열에 넣기
val assembler = new
VectorAssembler().setInputCols(featureCols).setOutputCol("rawfeatures")
다음 코드는 DataFrame 열 요약 통계를 사용하여 단위 분산으로 확장하여 특성을 표준화하는 파이프라인에서 사용될 StandardScaler(트랜스포머)를 만듭니다.
val scaler = new
StandardScaler().setInputCol("rawfeatures").setOutputCol("features").setWithStd(true.setWithMean(true)
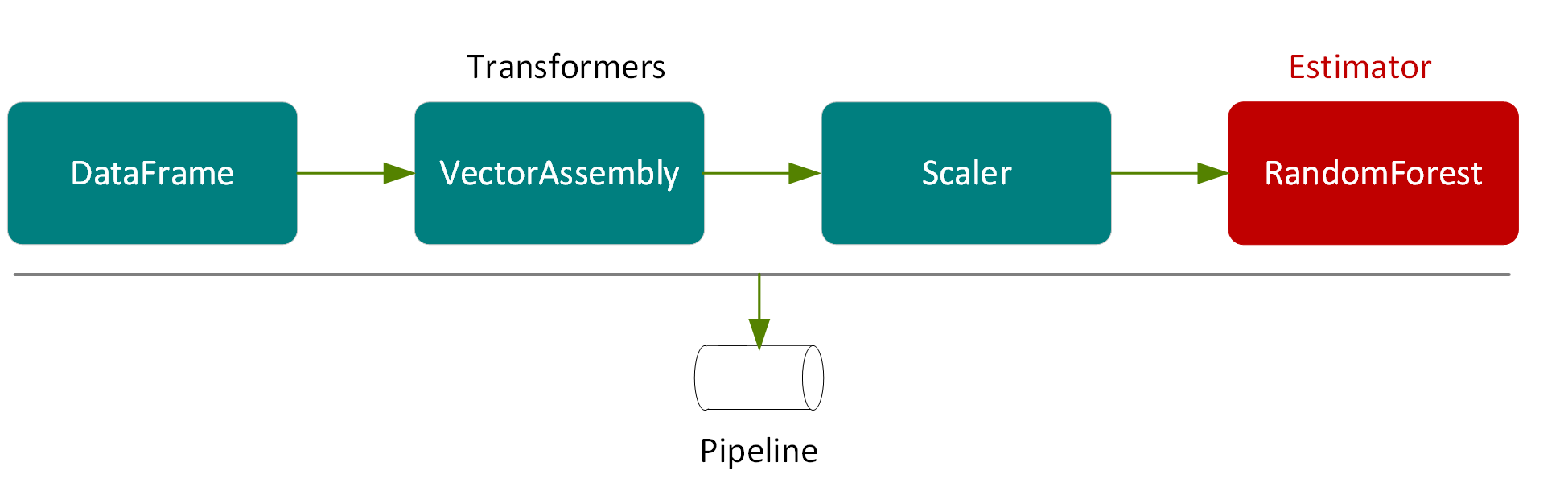
파이프라인에서 이러한 트랜스포머를 실행한 결과는 다음 그림과 같이 데이터세트에 확장된 특성 열을 추가하는 것입니다.

파이프라인의 마지막 요소는 기능 및 레이블 벡터를 트레이닝한 다음 RandomForestRegressorModel(트랜스포머)을 반환하는 RandomForestRegressor(추정자)입니다.
val rf = new
RandomForestRegressor().setLabelCol("medhvalue").setFeaturesCol("features")
다음 예제에서는 VectorAssembler, Scaler 및 RandomForestRegressor를 파이프라인에 넣습니다. 파이프라인은 여러 트랜스포머와 추정자를 함께 연결하여 모델을 트레이닝하고 사용하기 위한 ML 워크플로우를 지정합니다.
val steps = Array(assembler, scaler, rf)
val pipeline = new Pipeline().setStages(steps)
모델 트레이닝
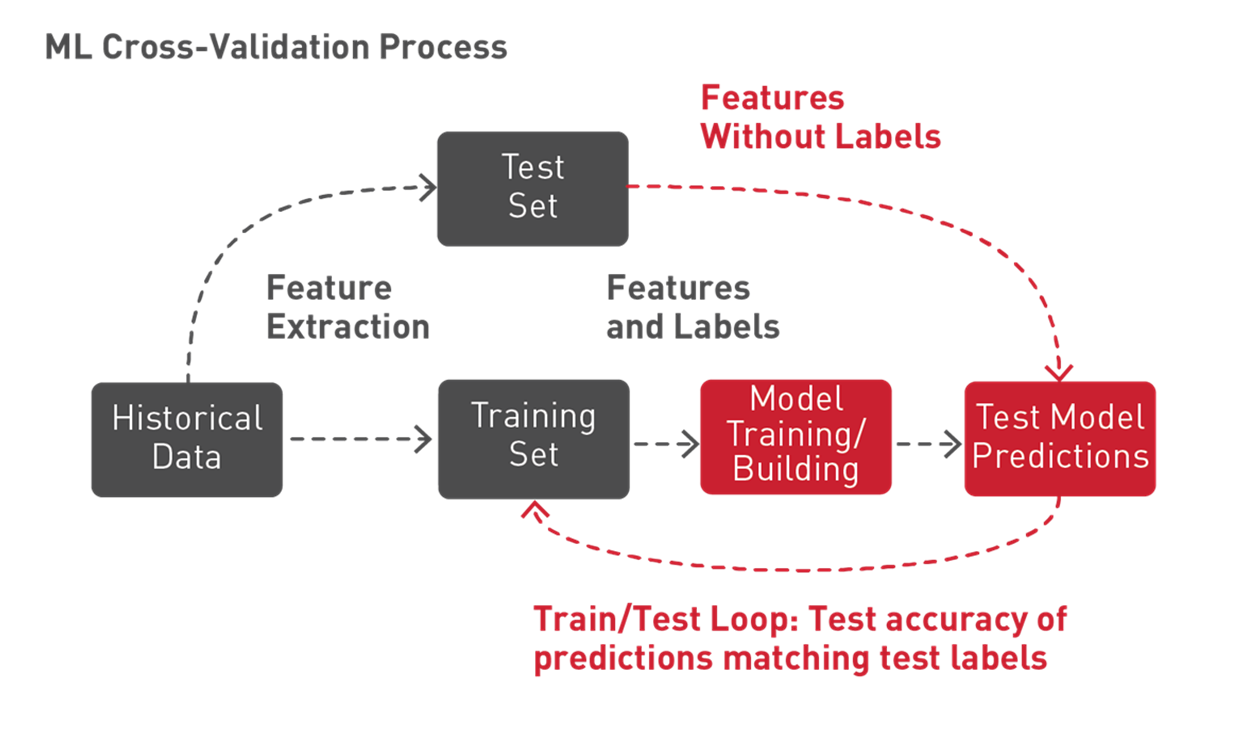
Spark ML은 ML 알고리즘의 매개변수 값이 최상의 모델을 생성하는지 판단하기 위해 다양한 매개변수 조합을 시도하도록 k-fold 교차 유효성 검사라는 기술을 지원합니다. k-fold 교차 유효성 검사를 사용하면 데이터가 무작위로 k 파티션으로 분할됩니다. 각 파티션은 테스트 데이터세트로 한 번 사용되며 나머지는 트레이닝에 사용됩니다. 그런 다음 테스트 세트를 사용하여 모델을 생성하고 테스트 세트로 평가하여 k 모델 정확도가 측정됩니다. 가장 높은 정확도 측정으로 이어지는 모델 매개변수는 최고의 모델을 생성합니다.
Spark ML은 교차 유효성 검사 워크플로우에서 테스트할 매개변수가 설정된 그리드 검색이라는 프로세스를 사용하여 다양한 매개변수 조합을 시도하는 변환/추정 파이프라인을 통해 k-fold 교차 유효성 검사를 지원합니다.
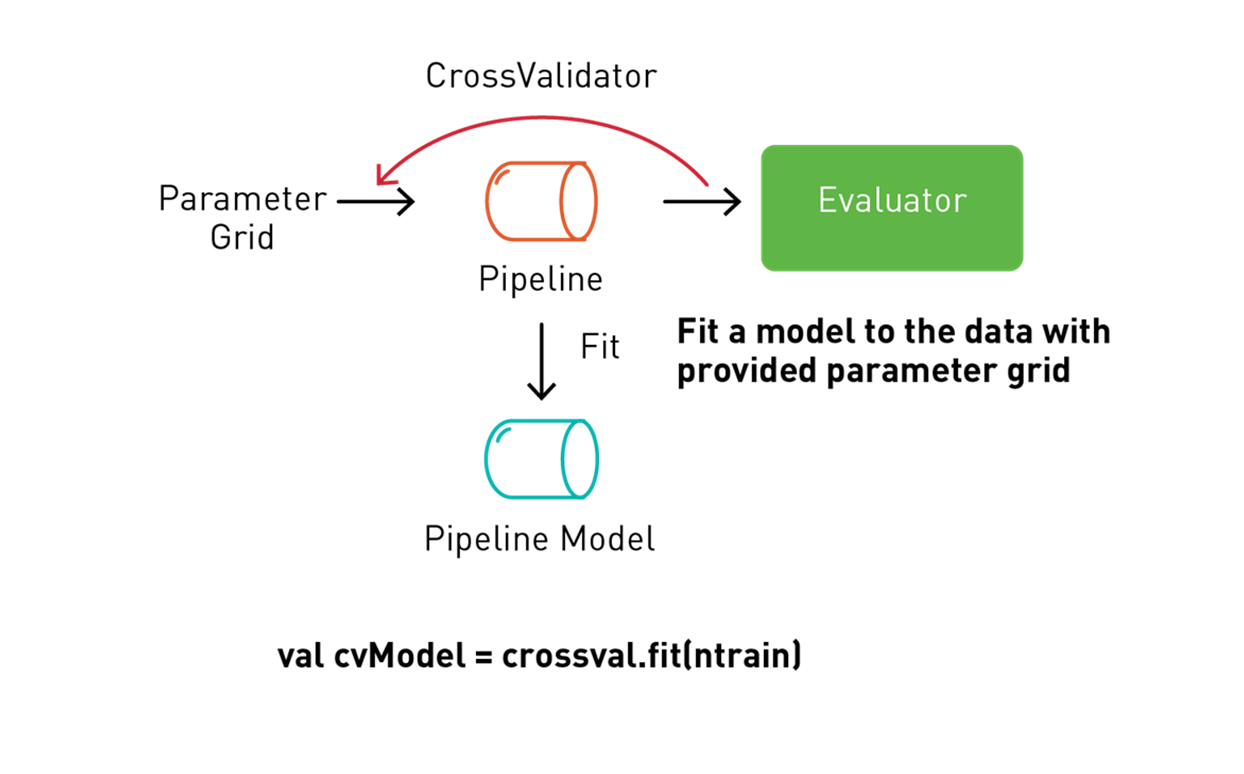
다음 코드는 ParamGridBuilder를 사용하여 모델 트레이닝을 위한 매개변수 그리드를 구성합니다. 테스트 medhvalue 열을 테스트 예측 열과 비교하여 모델을 평가하는 RegressionEvaluator를 정의합니다. 모델 선택을 위해 CrossValidator를 사용합니다. CrossValidator는 파이프라인, 매개변수 그리드 및 평가자를 사용하여 트레이닝 데이터세트에 맞도록 하며 최상의 모델을 반환합니다. CrossValidator는 ParamGridBuilder를 사용하여 RandomForestRegressor 추정자의 maxDepth, maxBins 및 numbTrees 매개변수를 반복하고 모델을 평가하여 신뢰할 수 있는 결과를 위해 매개변수 값당 세 번 반복합니다.
val paramGrid = new ParamGridBuilder()
.addGrid(rf.maxBins, Array(100, 200))
.addGrid(rf.maxDepth, Array(2, 7, 10))
.addGrid(rf.numTrees, Array(5, 20))
.build()
val evaluator = new RegressionEvaluator()
.setLabelCol("medhvalue")
.setPredictionCol("prediction")
.setMetricName("rmse")
val crossvalidator = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(3)
// 트레이닝 데이터세트를 조정하고 모델 반환
val pipelineModel = crossvalidator.fit(trainingData)
다음으로, 특성의 중요성을 출력하기 위해 최고의 모델을 얻을 수 있습니다. 결과는 중위 소득, 집당 인구 수 및 경도가 가장 중요한 특성이라는 것을 보여줍니다.
val featureImportances = pipelineModel
.bestModel.asInstanceOf[PipelineModel]
.stages(2)
.asInstanceOf[RandomForestRegressionModel]
.featureImportances
assembler.getInputCols
.zip(featureImportances.toArray)
.sortBy(-_._2)
.foreach { case (feat, imp) =>
println(s"feature: $feat, importance: $imp") }
결과:
feature: medincome, importance: 0.4531355014139285
feature: popPhouse, importance: 0.12807843645878508
feature: longitude, importance: 0.10501162983981065
feature: latitude, importance: 0.1044621179898163
feature: bedrmsPRoom, importance: 0.09720295935509805
feature: roomsPhouse, importance: 0.058427239343697555
feature: medage, importance: 0.05368211559886386
다음 예제에서는 최대 깊이 2, 최대 빈 50 및 트리 5개의 반환되는 교차 유효성 검사 프로세스를 사용하여 생성된 최고의 랜덤 포레스트 모델에 대한 매개변수를 가져옵니다.
val bestEstimatorParamMap = pipelineModel
.getEstimatorParamMaps
.zip(pipelineModel.avgMetrics)
.maxBy(_._2)
._1
println(s"Best params:\n$bestEstimatorParamMap")
결과:
rfr_maxBins: 50,
rfr_maxDepth: 2,
rfr_-numTrees: 5
예측 및 모델 평가
다음으로는 원래 DataFrame의 20% 무작위 분할이었으며 트레이닝에 사용되지 않은 테스트 DataFrame을 사용하여 모델의 정확도를 측정합니다.
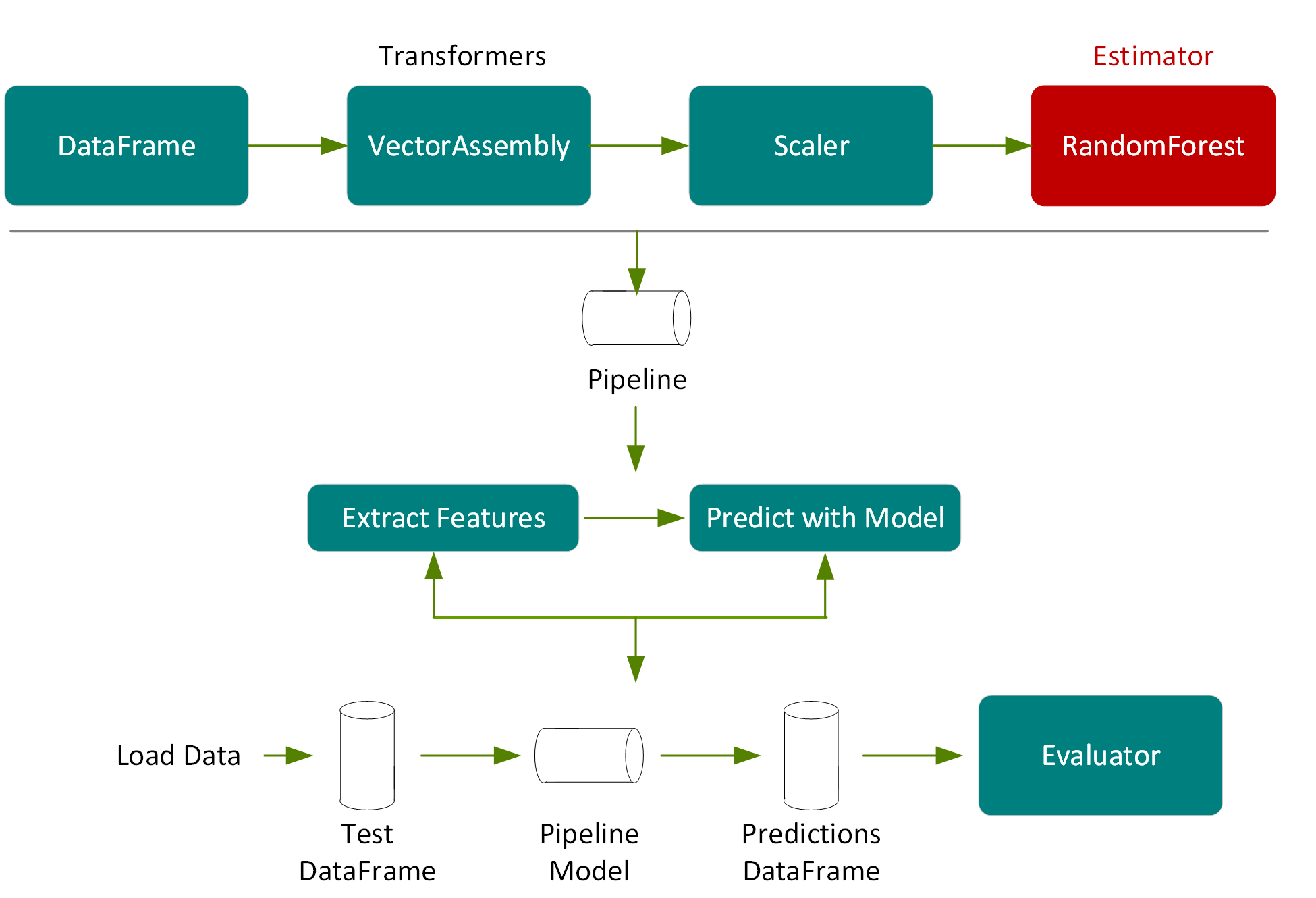
다음 코드에서는 파이프라인 단계에 따라 테스트 DataFrame을 통과하고 특성 추출 단계를 통해 모델 조정에 의해 선택된 랜덤 포레스트 모델을 추정한 다음 새 DataFrame의 열에서 예측을 반환하는 파이프라인 모델의 변환을 호출합니다.
val predictions = pipelineModel.transform(testData)
predictions.select("prediction", "medhvalue").show(5)
결과:
+------------------+---------+
| prediction|medhvalue|
+------------------+---------+
|104349.59677450571| 94600.0|
| 77530.43231856065| 85800.0|
|111369.71756877871| 90100.0|
| 97351.87386020401| 82800.0|
+------------------+---------+
With the predictions and labels from the test data, we can now evaluate the model. To evaluate the linear regression model, you measure how close the predictions values are to the label values. The error in a prediction, shown by the green lines below, is the difference between the prediction (the regression line Y value) and the actual Y value, or label. (Error = 예측-레이블).
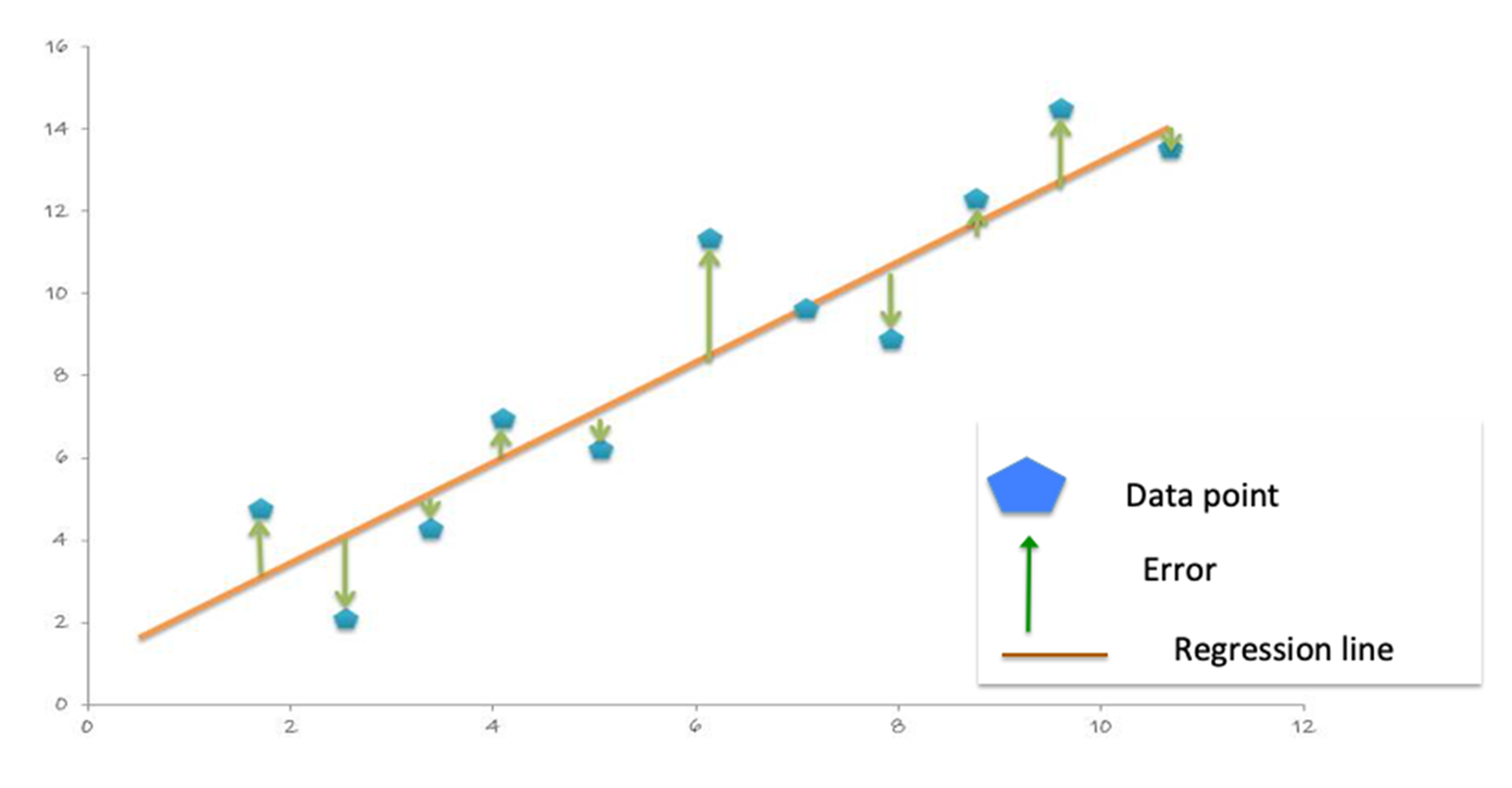
평균 절대 오차(MAE)는 레이블과 모델 예측 간의 절대적인 차이의 평균입니다. 절대 징후는 부정적인 징후를 제거합니다.
MAE = 합계(절대(예측 레이블)) / 관측 수).
The Mean Square Error (MSE) is the sum of the squared errors divided by the number of observations. The squaring removes any negative signs and also gives more weight to larger differences. (MSE = 합계(제곱(예측 레이블)) / 관측 수).
루트 평균 제곱 오류(RMSE)는 MSE의 제곱근입니다. RMSE는 예측 오류의 표준 편차입니다. 오류는 회귀선 레이블 데이터 포인트에서 얼마나 멀리 떨어져 있는지에 대한 측정값이며, RMSE는 이러한 오류가 얼마나 산점되어 있는지 측정합니다.
The following code example uses the DataFrame withColumn transformation, to add a column for the error in prediction: error=예측-medhvalue. 그런 다음 예측, 중위 집값 및 오류(1천 달러 단위)에 대한 요약 통계를 표시합니다.
predictions = predictions.withColumn("error",
col("prediction")-col("medhvalue"))
predictions.select("prediction", "medhvalue", "error").show
결과:
+------------------+---------+-------------------+
| prediction|medhvalue| error|
+------------------+---------+-------------------+
| 104349.5967745057| 94600.0| 9749.596774505713|
| 77530.4323185606| 85800.0| -8269.567681439352|
| 101253.3225967887| 103600.0| -2346.677403211302|
+------------------+---------+-------------------+
predictions.describe("prediction", "medhvalue", "error").show
결과:
+-------+-----------------+------------------+------------------+
|summary| prediction| medhvalue| error|
+-------+-----------------+------------------+------------------+
| count| 4161| 4161| 4161|
| mean|206307.4865123929|205547.72650805095| 759.7600043416329|
| stddev|97133.45817381598|114708.03790345002| 52725.56329678355|
| min|56471.09903814694| 26900.0|-339450.5381565819|
| max|499238.1371374392| 500001.0|293793.71945819416|
+-------+-----------------+------------------+------------------+
다음 코드 예제에서는 Spark RegressionEvaluator를 사용하여 36636.35(1천 달러 단위)를 반환하는 예측 DataFrame에서 MAE를 계산합니다.
val maevaluator = new RegressionEvaluator()
.setLabelCol("medhvalue")
.setMetricName("mae")
val mae = maevaluator.evaluate(predictions)
결과:
mae: Double = 36636.35
다음 코드 예제에서는 Spark RegressionEvaluator를 사용하여 52724.70을 반환하는 예측 DataFrame에서 RMSE를 계산합니다.
val evaluator = new RegressionEvaluator()
.setLabelCol("medhvalue")
.setMetricName("rmse")
val rmse = evaluator.evaluate(predictions)
결과:
rmse: Double = 52724.70

모델 저장
이제 조정된 파이프라인 모델을 나중에 프로덕션 환경에서 사용할 수 있도록 분산된 파일 저장소에 저장할 수 있습니다. 이렇게 하면 특성 추출 단계와 모델 조정에서 랜덤 포레스트 모델을 모두 저장할 수 있습니다.
pipelineModel.write.overwrite().save(modeldir)
파이프라인 모델을 저장한 결과는 메타데이터에 대한 JSON 파일과 모델 데이터에 대한 Parquet입니다. 로드 명령으로 모델을 다시 로드할 수 있습니다. 원래 모델 및 다시 로드된 모델은 동일합니다.
val sameModel = CrossValidatorModel.load(“modeldir")
요약
이 챕터에서는 회귀, 의사결정 트리 및 랜덤 포레스트 알고리즘에 대해 이야기했습니다. Spark ML 파이프 라인의 기초를 다루고 평균 주택 가격을 예측하기 위해 실제 예제를 사용했습니다.