챕터 3에서는 Spark 3.x에서 GPU 가속의 기능에 대해 이야기했습니다. 이 챕터에서는 GPU를 활용하여 RAPIDS 라이브러리를 통해 처리를 가속화하는 Apache Spark 3.x의 새로운 RAPIDS 라이브러리를 사용하여 시작하는 기본 사항을 살펴보겠습니다(자세한 내용은 Apache Spark의 RAPIDS 액셀러레이터로 시작하기 참조).
Apache Spark의 RAPIDS 액셀러레이터는 다음과 같은 기능 및 한계를 가지고 있습니다.
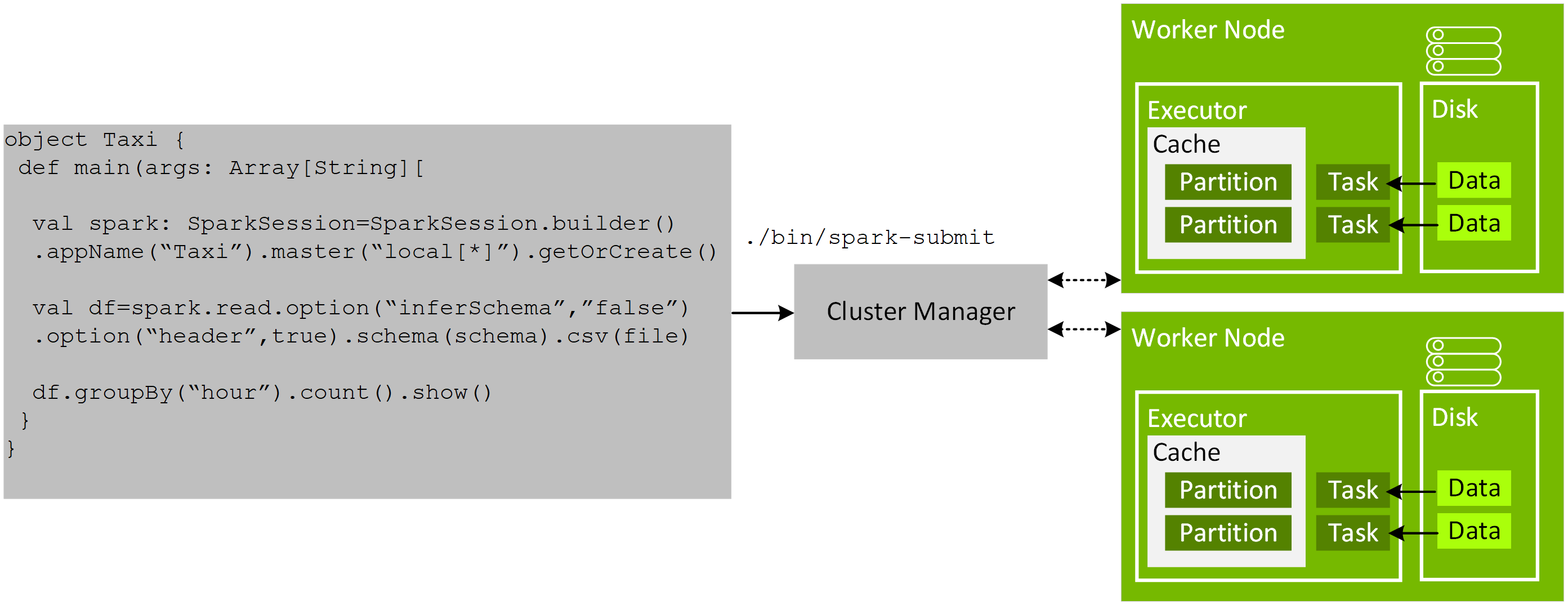
- 열 기반 처리가 있는 GPU에서 Spark SQL을 실행 가능
- 사용자의 API 변경 필요 없음
- 행에서 열로 전환 및 뒤로 처리
- Rapids cuDF 라이브러리 사용
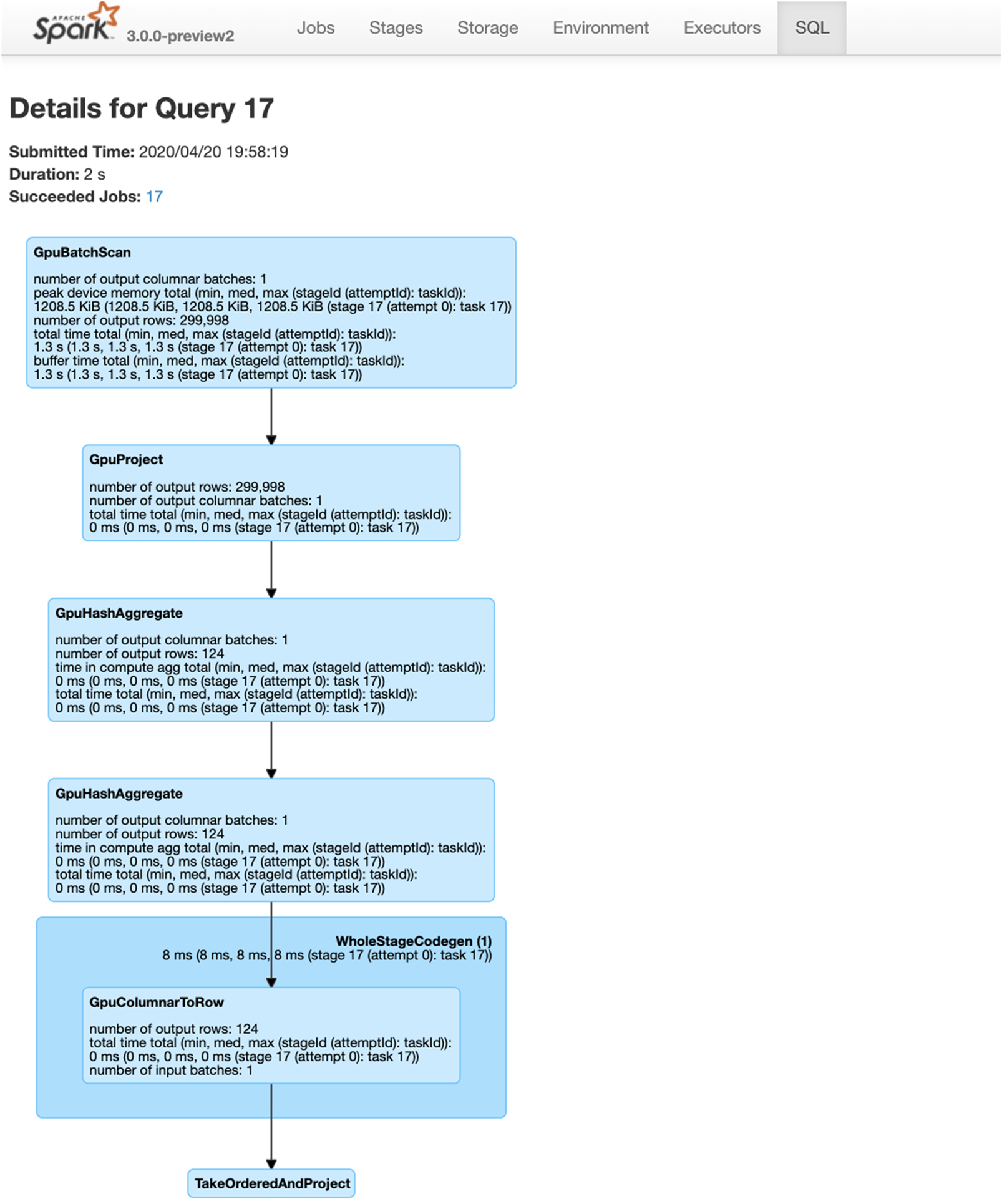
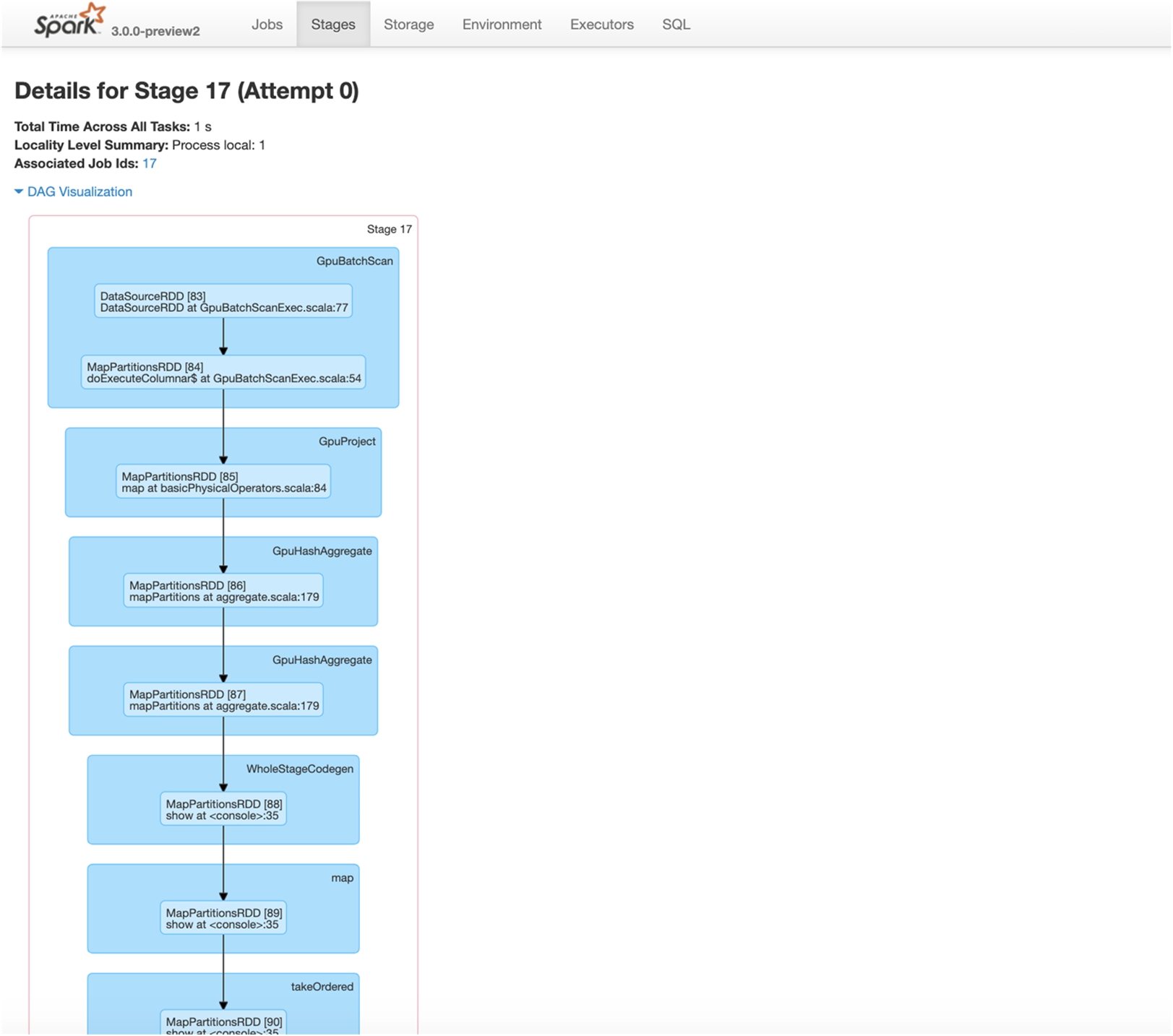
- GPU에서 지원되는 SQL 작업을 실행합니다. 작업이 구현되지 않았거나 GPU와 호환되지 않는 경우, Spark CPU 버전을 사용하여 폴백됩니다.
- 플러그인은 RDD를 직접 조작하는 작업을 가속화할 수 없습니다.
- 액셀러레이터 라이브러리는 또한 UCX를 활용하여 GPU에 최대한 많은 데이터를 유지하고 GPU 간 전송을 위해 CPU를 우회하여 GPU 전송을 최적화할 수 있는 Spark의 셔플을 구현합니다.
이 GPU 가속을 사용하려면 다음이 필요합니다.
- Apache Spark 3.0+
- RAPIDS Dataframe 라이브러리 cuDF 버전에 대한 요구 사항을 준수하는 GPU로 구성된 Spark 클러스터.
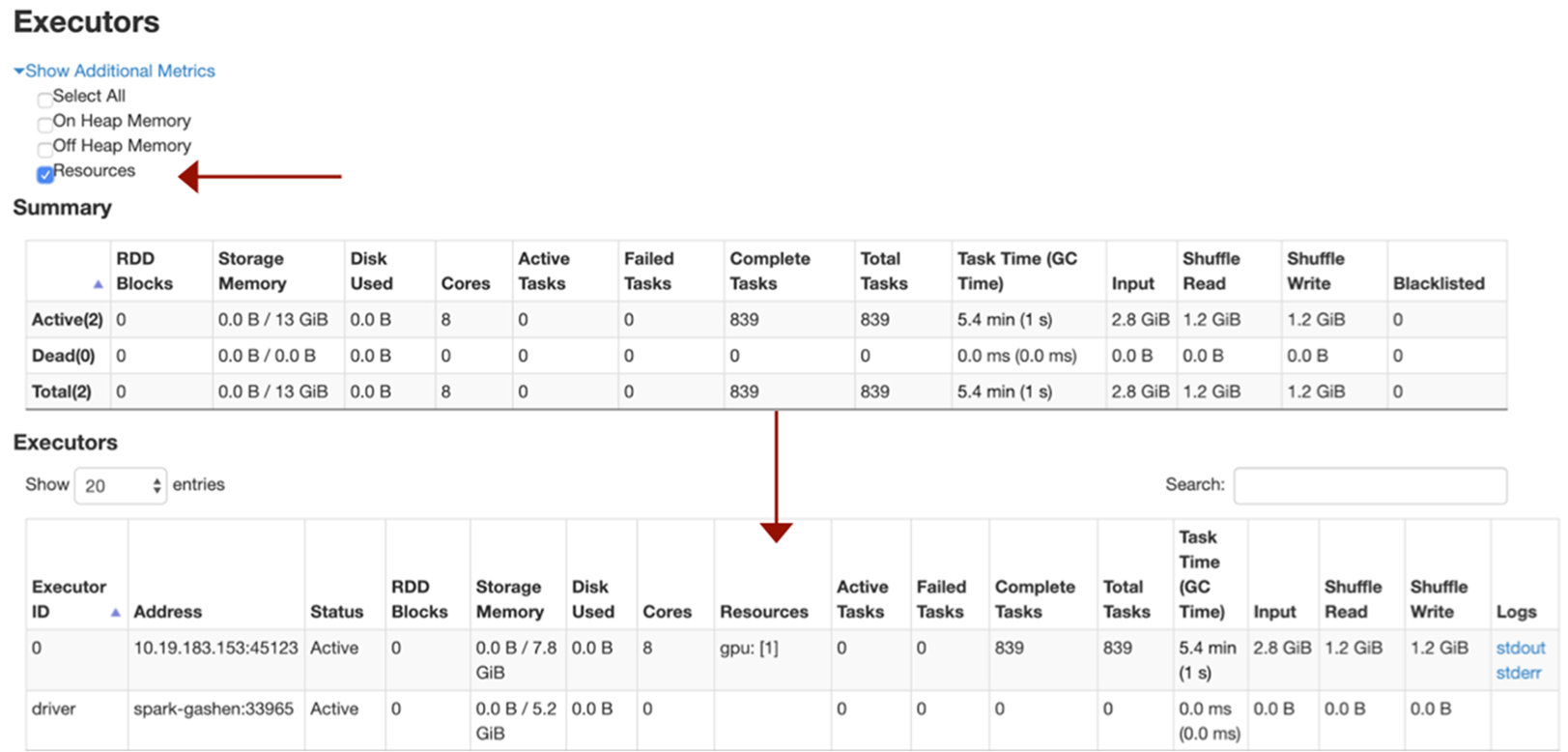
- 실행자당 하나의 GPU.
- 다음 jar 추가:
- 클러스터에서 사용할 수 있는 CUDA 버전에 해당하는 cudf jar.
- RAPIDS Spark 액셀러레이터 플러그인 jar.
- com.nvidia.spark.SQLPlugin에 config spark.plugins 설정