챕터 1에서는 Spark DataFrames가 클러스터에서 실행되는 방법을 살펴봤습니다. 이 장에서는 DataFrames 및 Spark SQL 프로그래밍의 이점을 시작으로 이에 대한 개요를 제공합니다.
Spark SQL 및 DataFrame 프로그래밍
DataFrame 및 Spark SQL 이점
Spark SQL 및 DataFrame API는 Spark SQL의 최적화된 실행 엔진을 통해 사용 편의성, 공간 효율성 및 성능 향상을 제공합니다.
최적화된 메모리 사용
Spark SQL은 필요한 열만 스캔하고, 압축을 자동으로 조정하며, 메모리 사용을 최소화하며, JVM 가비지 수집을 최소화하는 데 최적화된 메모리 내 열 기반 형식을 사용하여 DataFrame을 캐시(dataFrame.cache 호출 시)합니다.
Spark SQL Vectorized Parquet 및 ORC 판독기는 열 배치 처리로 압축을 풀고 디코딩하며, 이는 읽기 속도가 약 9배 빠릅니다.
쿼리 최적화
Spark SQL의 Catalyst Optimizer는 논리적 최적화 및 물리적 계획을 처리하여 규칙 기반 및 비용 기반 최적화를 모두 지원합니다. Spark SQL 전체 단계 Java 코드 생성은 가능한 경우 SQL 쿼리에서 운영자 집합에 대해 단일 최적화된 함수를 바이트코드로 생성하여 CPU 사용을 최적화합니다.
Spark SQL을 사용하여 택시 데이터세트 탐색
데이터 준비 및 탐색은 일반적인 머신 러닝(ML) 또는 딥러닝(DL) 프로젝트에서 분석 파이프라인의 60~80%를 차지합니다. ML 모델을 빌드하려면 모델의 정확한 예측에 가장 많이 기여하는 특성을 찾기 위해 데이터세트를 청소, 추출, 탐색 및 테스트해야 합니다. 설명에 도움이 되도록, Spark SQL을 사용하여 택시 데이터세트를 탐색하여 택시 요금 금액을 예측하는 데 도움이 될 수 있는 특성을 분석해볼 것입니다.
파일에서 DataFrame으로 데이터 로드 및 캐시
다음 코드는 CSV 파일의 데이터를 Spark Dataframe에 로드하는 방법을 보여 주며, 챕터 1에서 설명한 대로 DataFrame에 로드할 데이터 소스와 스키마를 지정합니다. DataFrame을 SQL 임시 보기로 등록한 후 SparkSession의 SQL 함수를 사용하여 SQL 쿼리를 실행할 수 있으며, 이 함수는 결과를 DataFrame으로 반환합니다. Spark가 각 쿼리에 대해 다시 로드할 필요가 없도록 DataFrame을 캐시합니다. 또한 Spark는 DataFrames 또는 테이블을 메모리의 열로 캐시할 수 있어 메모리 사용량과 성능을 향상할 수 있습니다.

// 챕터 1에서와 같이 데이터 로드
val file = "/data/taxi_small.csv"
val df = spark.read.option("inferSchema", "false")
.option("header", true).schema(schema).csv(file)
// 메모리에서 DataFrame을 열 형식으로 캐시
df.cache
// Spark SQL용 DataFrame의 표 보기 생성
df.createOrReplaceTempView("taxi")
// 메모리에서 열 형식의 택시 테이블 캐시
spark.catalog.cacheTable("taxi")
Spark SQL 사용하기
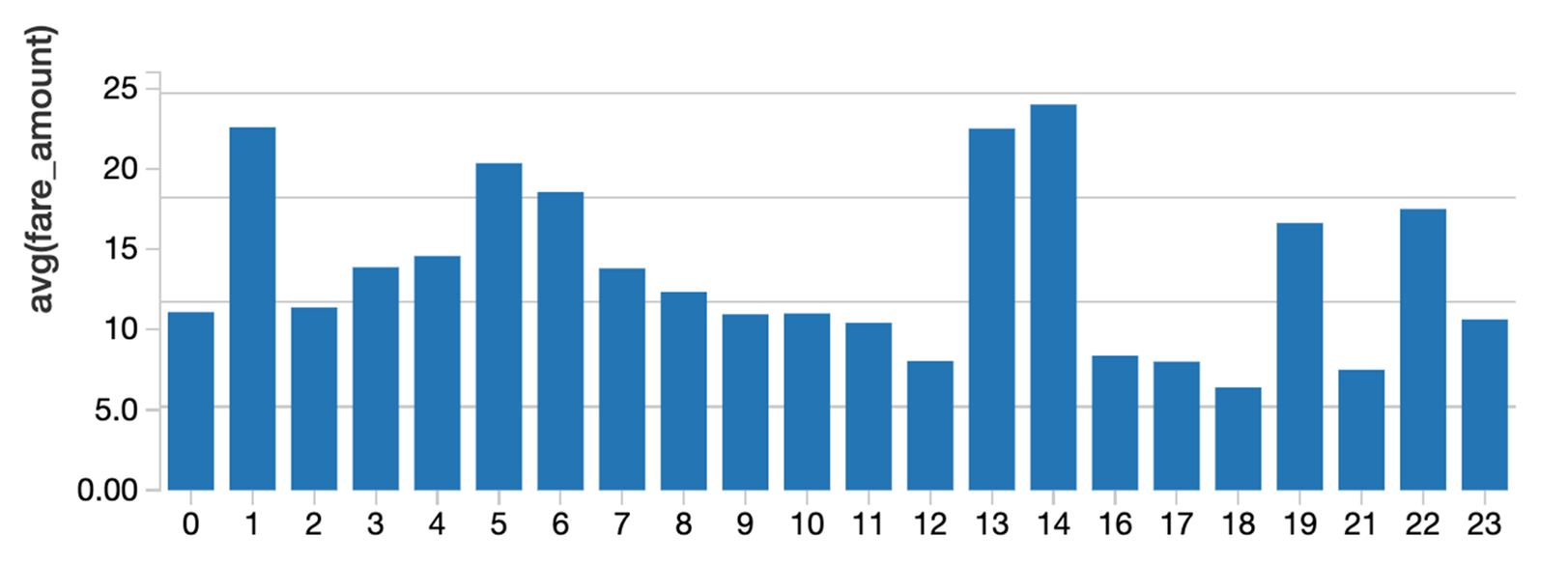
이제 Spark SQL을 사용하여 택시 요금 금액에 영향을 줄 수 있는 요소가 무엇인지 탐색할 수 있습니다.
%sql
시간, avg(fare_amount) 선택
택시에서
시간별 그룹 주문별 그룹
Zeppelin이나 Jupyter와 같은 노트북을 사용하면 SQL 결과를 그래프 형식으로 표시할 수 있습니다.
다음은 DataFrame API와 동일한 쿼리입니다.
df.groupBy("hour").avg("fare_amount")
.orderBy("hour").show(5)
결과:
+----+------------------+
|hour| avg(fare_amount)|
+----+------------------+
| 0.0|11.083333333333334|
| 1.0|22.581632653061224|
| 2.0|11.370820668693009|
| 3.0|13.873989218328841|
| 4.0| 14.57204433497537|
+----+------------------+
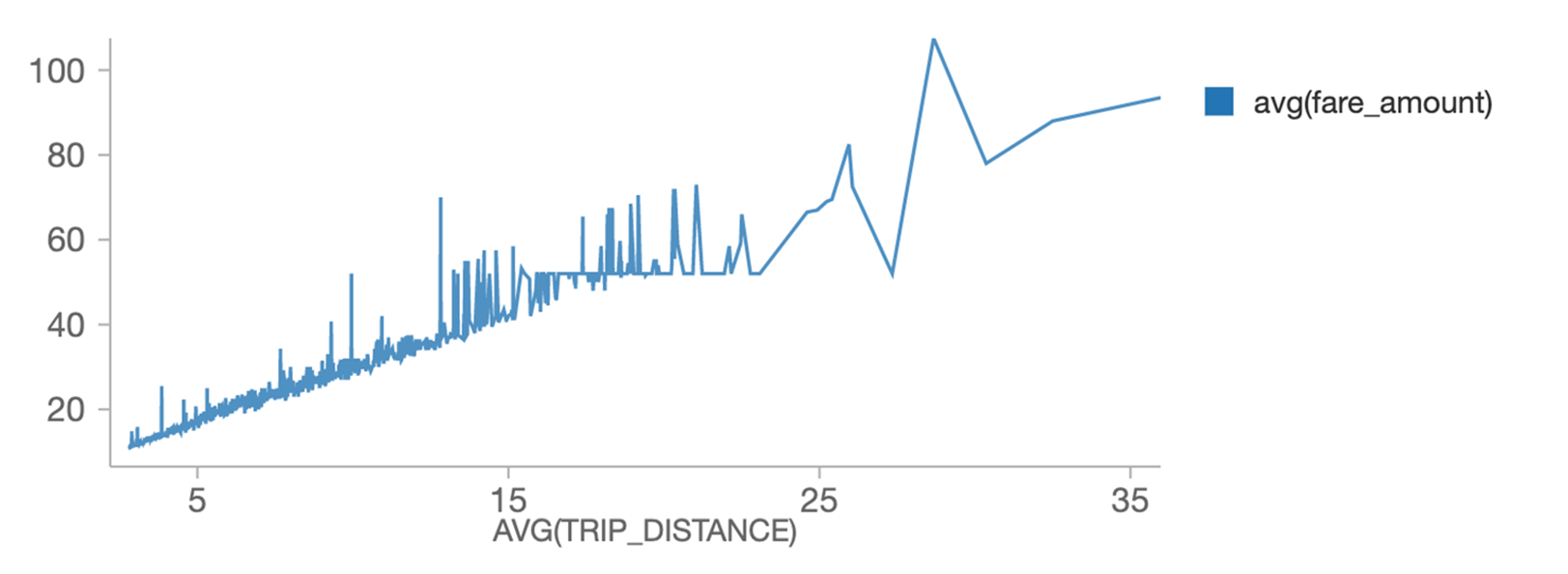
평균 주행 거리 대비 평균 운임은 얼마인가요?
%sql
trip_distance,avg(trip_distance), avg(fare_amount) 선택
택시에서
trip_distance 순서로 avg(trip_distance) desc로 그룹화
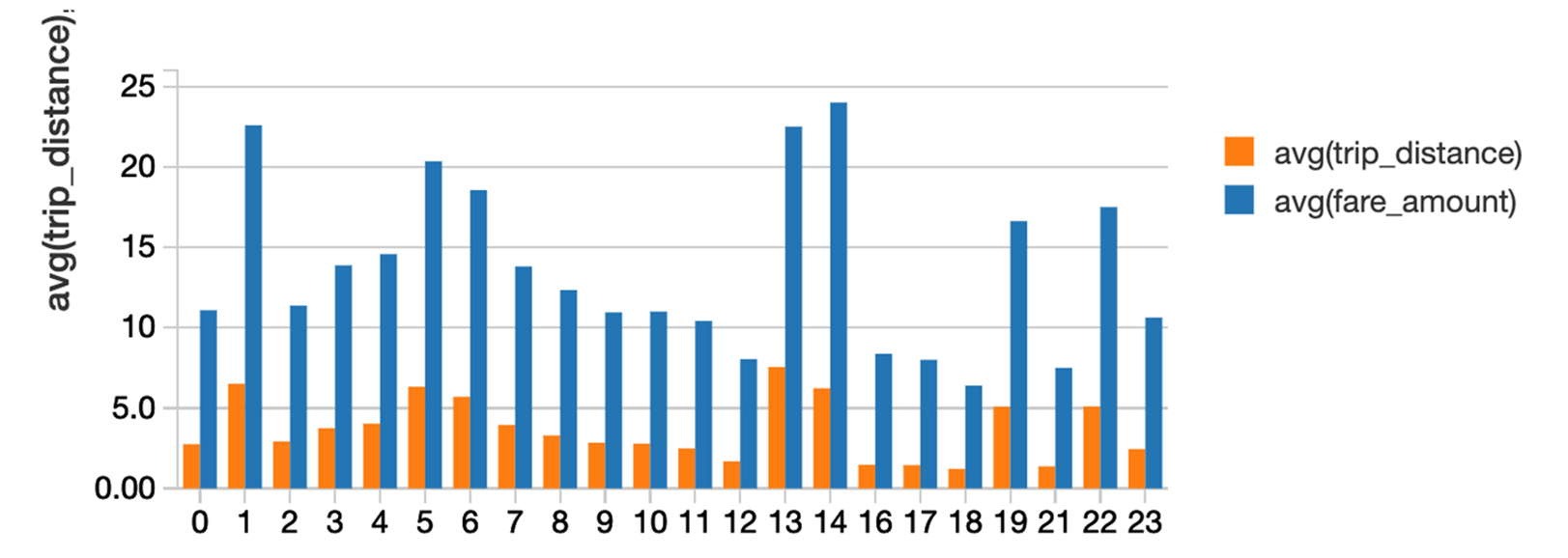
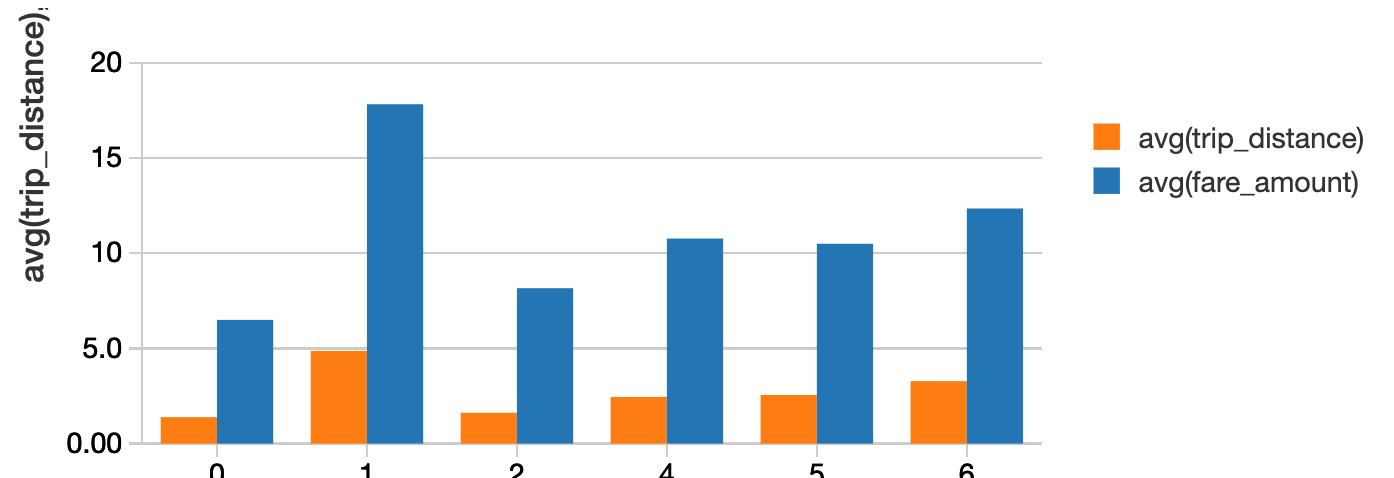
하루 중 시간당 평균 운임과 평균 주행 거리는 얼마인가요?
%sql
시간, avg(fare_amount), avg(trip_distance) 선택
택시에서
시간별 그룹 주문별 그룹
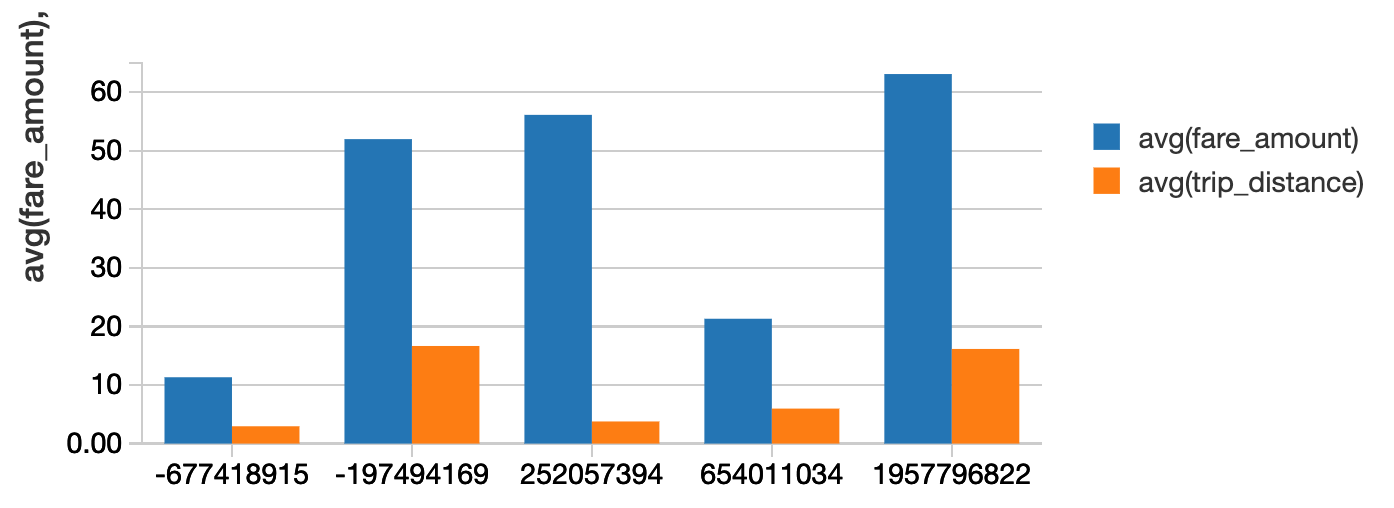
속도 코드당 평균 운임과 평균 주행 거리는 얼마인가요?
%sql
시간, avg(fare_amount), avg(trip_distance) 선택
택시에서
rate_code order by rate_code로 그룹화
주중 하루 평균 운임과 평균 주행 거리는 얼마입니까?
%sql
day_of_week, avg(fare_amount), avg(trip_distance) 선택
택시에서
day_of_week 순서 day_of_week로 그룹화
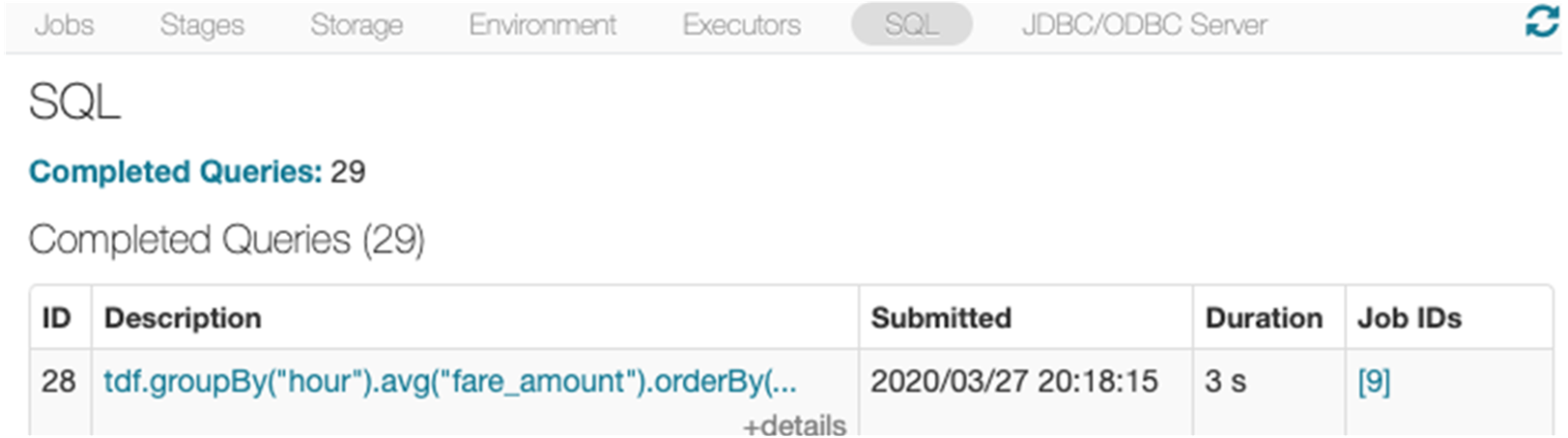
Spark 웹 UI를 사용하여 Spark SQL을 모니터링
SQL 탭
Spark SQL 탭을 사용하여 쿼리 계획 세부 정보 및 SQL 메트릭과 같은 쿼리 실행 정보를 볼 수 있습니다. 쿼리 링크를 클릭하면 작업의 DAG가 표시됩니다.
DAG에서 +세부 정보를 클릭하면 해당 스테이지에 대한 세부 정보가 표시됩니다.
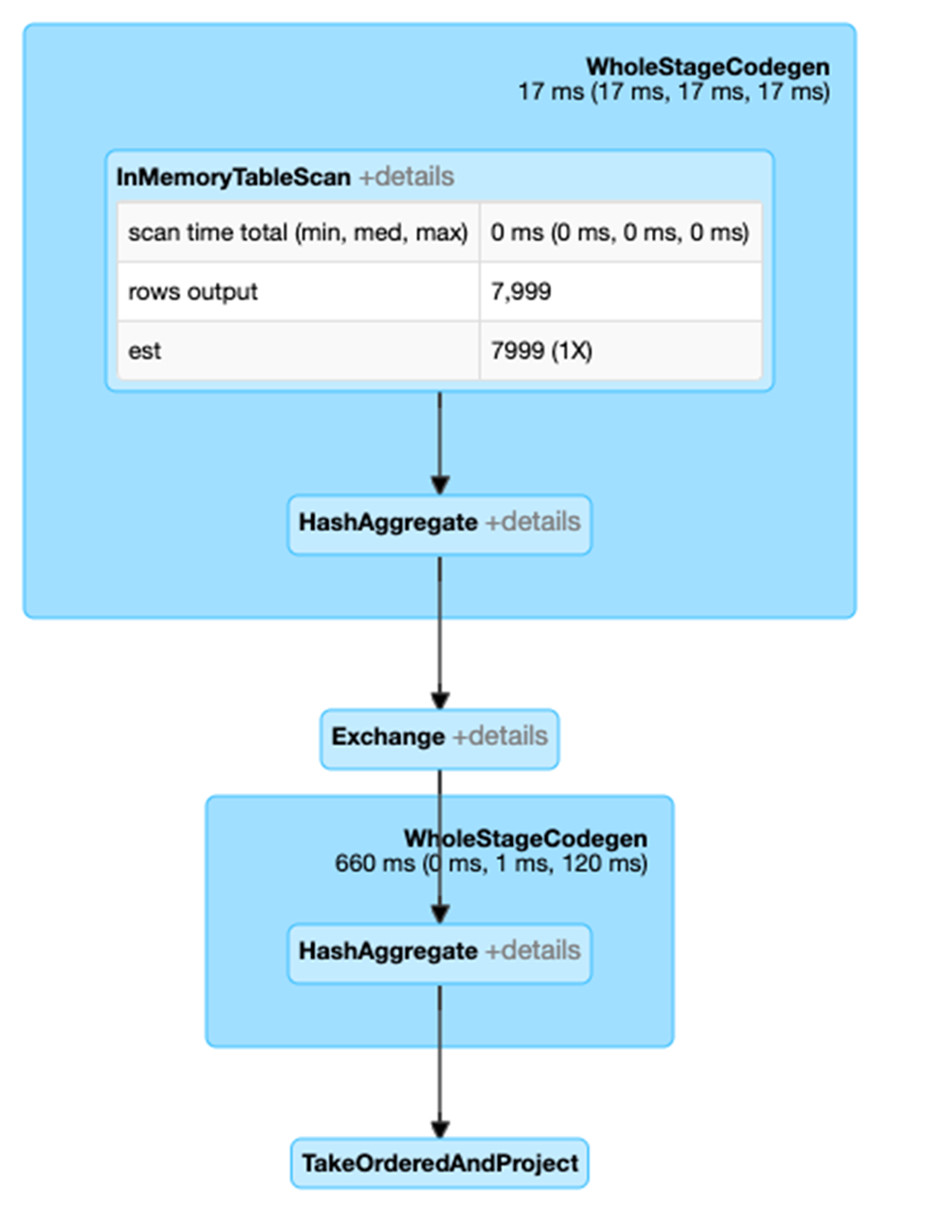
하단의 세부 정보 링크를 클릭하면 논리적 계획과 물리적 계획이 텍스트 형식으로 표시됩니다.
쿼리 계획 세부 정보에서 다음을 확인할 수 있습니다.
- 각 스테이지의 시간.
- 파티션 필터, 프로젝션 및 필터 푸시다운이 발생하는 경우.
- 단계(Exchange)와 셔플된 데이터 양 간의 셔플. 조인 또는 집계가 많은 데이터를 셔플하는 경우 버킷을 고려하십시오.
- (spark.sql.shuffle.partitions 옵션으로 셔플할 때 사용할 파티션 수를 설정할 수 있습니다.)
- 사용 중인 조인 알고리즘입니다. 하나의 테이블이 작으며 정렬 병합 조인이 큰 테이블에 사용되어야 하는 경우 브로드캐스트 조인을 사용해야 합니다. 브로드캐스트 힌트를 사용하여 Spark를 조인에 테이블을 브로드캐스트하도록 안내할 수 있습니다. 정렬 병합 조인 알고리즘을 사용하여 큰 테이블을 빠르게 조인하려면 버킷을 사용하여 테이블을 미리 정렬하고 그룹화할 수 있습니다. 이렇게 하면 정렬 병합에서 셔플되는 것이 방지됩니다.
Spark SQL ANALYZE TABLE 테이블 이름 COMPUTE STATISTICS를 사용하여 Catalyst Planner의 비용 기반 최적화를 활용합니다.
작업 탭
작업 탭 요약 페이지에는 모든 작업의 상태, 기간 및 진행률과 전체 이벤트 타임라인 등의 상위 수준 작업 정보가 표시됩니다. 다음은 확인할 몇 가지 메트릭입니다.
- 기간: 작업의 시간을 확인합니다.
- 스테이지 성공/총 작업, 성공/합계: 스테이지/작업 오류가 있는지 확인합니다.
스테이지 탭
스테이지 탭에는 모든 작업에 대한 요약 메트릭이 표시됩니다. 메트릭을 사용하여 실행자 또는 작업 배포에 대한 문제를 식별할 수 있습니다. 다음은 찾아봐야 할 몇 가지 사항입니다.
- 기간: 시간이 오래 걸리는 작업이 있습니까? 작업 프로세스 시간이 불균형하면 리소스가 낭비될 수 있습니다.
- 상태: 실패한 작업이 있습니까?
- 읽기 크기, 쓰기 크기: 데이터 크기에 비뚤어진 것이 있습니까?
- 파티션/작업의 균형이 맞지 않으면 다시 분할하는 것이 좋습니다.
스토리지 탭
스토리지 탭에는 디스크 정보의 크기와 메모리 크기가 있는 디스크에 캐시되거나 유지되는 DataFrame이 표시됩니다. 스토리지 탭을 사용하여 캐시된 DataFrames가 메모리에 적합한지 확인할 수 있습니다. DataFrame을 다시 사용하려고 하며 메모리에 맞는 경우, 캐싱하면 실행 속도가 빨라집니다.
실행자 탭
실행자 탭에는 애플리케이션을 위해 만들어진 실행자에 의한 요약 메모리, 디스크 및 작업 사용 정보가 표시됩니다. 이 탭을 사용하여 애플리케이션에 필요한 리소스의 양이 있는지 확인할 수 있습니다.
- 읽기 쓰기 열 셔플: 스테이지 간에 전송되는 데이터의 크기를 표시합니다.
- 스토리지 메모리 열: 현재 사용된 메모리/사용 가능한 메모리를 보여줍니다.
- 작업 시간 열: 작업 시간/가비지 수집 시간을 표시합니다.
분할 및 버킷
파일 분할 및 버킷은 Spark SQL에서 일반적인 최적화 기술입니다. 파일이나 디렉토리에서 데이터를 미리 집계하여 데이터 왜곡 및 데이터 축소를 줄이는 데 도움이 될 수 있습니다. DataFrames는 영구 테이블로 저장할 때 정렬, 분할 및/또는 버킷화할 수 있습니다. 분할은 지정된 열에 따라 디렉토리 계층 구조에 파일을 저장하여 읽기를 최적화합니다. 예를 들어 DataFrame을 1년 단위로 분할하는 경우:
df.write.format("parquet")
.partitionBy("year")
.option("path", "/data ")
.saveAsTable("taxi")
디렉토리는 다음 구조를 가집니다.
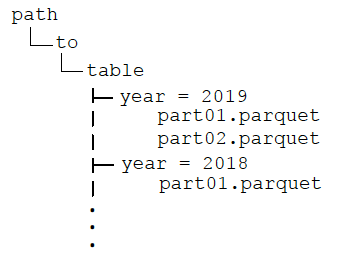
After partitioning the data, when queries are made with filter operators on the partition column, the Spark SQL catalyst optimizer pushes down the partition filter to the datasource. The scan reads only the directories that match the partition filters, reducing disk I/O and data loaded into memory. For example, the following query reads only the files in the year = '2019' 디렉토리.
df.filter("year = '2019')
.groupBy("year").avg("fareamount")
When visualizing the physical plan for this query, you will see Scan PrunedInMemoryFileIndex[ /data/year=2019], PartitionFilters: [ (year = 2019)] .
분할과 마찬가지로 버킷화는 데이터를 값별로 분할합니다. 그러나 버킷화는 버킷 값의 해시를 통해 고정된 수의 버킷에 데이터를 배포하는 반면 분할은 각 파티션 열 값에 대한 디렉토리를 만듭니다. 테이블은 두 개 이상의 값으로 버킷화할 수 있으며 분할 여부에 관계없이 버킷화를 사용할 수 있습니다. 이전 예제에 버킷화를 추가하는 경우 디렉토리 구조는 이전과 동일하며, 연도 디렉토리의 데이터 파일은 4개의 버킷에 시간별로 그룹화됩니다.
df.write.format("parquet")
.partitionBy("year")
.bucketBy(4,"hour")
.option("path", "/data ")
.saveAsTable("taxi")
데이터를 버킷화한 후 버킷 값의 집계 및 조인(와이드 변환)은 파티션 간에 데이터를 셔플하여 네트워크와 디스크 I/O를 줄입니다. 또한 버킷 필터 가지치기가 데이터 소스로 푸시되어 디스크 I/O를 줄이고 메모리에 로드되는 데이터를 줄일 수 있습니다. 다음 쿼리는 연도의 파티션 필터를 데이터 원본으로 푸시다운하며 시간으로 집계하기 위한 셔플을 방지합니다.
df.filter("year = '2019')
.groupBy("hour")
.avg("hour")
분할은 필터링을 위해 쿼리에서 자주 사용되는 열과 디렉토리에서 파일을 배포할 수 있는 충분한 해당 데이터를 가진 열 값의 개수가 제한된 열에서만 사용해야 합니다. 작은 파일은 과도한 병렬이 있는 경우 덜 효율적이며 큰 파일이 너무 적으면 병렬성을 해칠 수 있습니다. 버킷화는 고유한 버킷화 열 값의 개수가 많을 때 잘 작동하며 버킷 열은 쿼리에서 자주 사용됩니다.
요약
이 챕터에서는 Spark SQL과 표 데이터를 사용하는 방법을 살펴봤습니다. 이러한 코드 예제는 Spark SQL을 사용하여 데이터를 처리하는 기초로 재사용할 수 있습니다. 또 다른 챕터에서는 DataFrames와 동일한 데이터를 사용하여 택시 요금을 예측합니다.