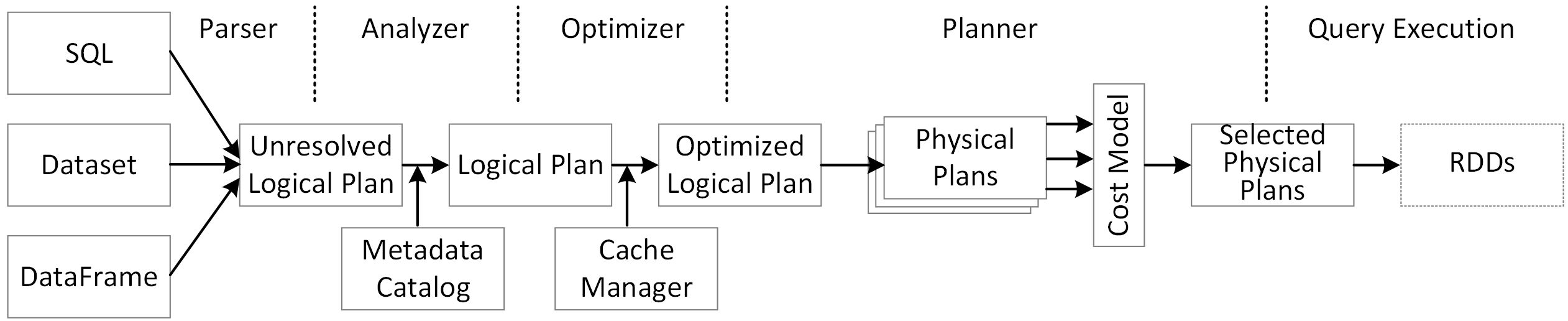
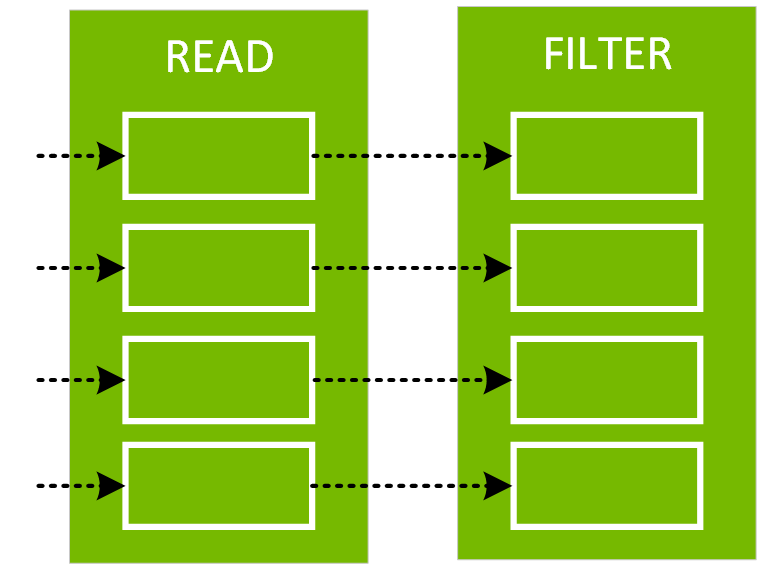
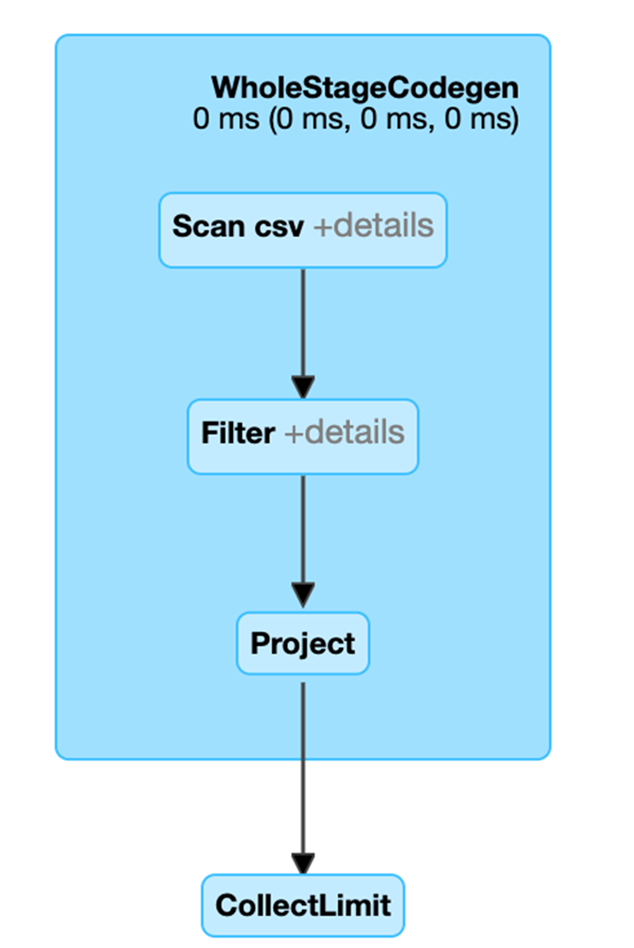
설명("형식 지정") 메서드를 호출하여 DataFrame에 대한 서식이 지정된 물리적 계획을 볼 수 있습니다. 아래 물리적 계획에서 df2용 DAG는 스캔 csv 파일, day_of_week 필터, 그리고 시간, fare_amount 및 day_of_week에 대한 프로젝트(열 선택)로 구성됩니다.
val df = spark.read.option("inferSchema", "false") .option("header", true).schema(schema).csv(file)
val df2 = df.select($"hour", $"fare_amount", $"day_of_week").filter($"day_of_week" === "6.0" )
df2.show(3)
결과:
+----+-----------+-----------+
|hour|fare_amount|day_of_week|
+----+-----------+-----------+
|10.0| 11.5| 6.0|
|10.0| 5.5| 6.0|
|10.0| 13.0| 6.0|
+----+-----------+-----------+
df2.explain(“formatted”)
결과:
== Physical Plan ==
* Project (3)
+- * Filter (2)
+- Scan csv (1)
(1) Scan csv
Location: [dbfs:/FileStore/tables/taxi_tsmall.csv]
Output [3]: [fare_amount#143, hour#144, day_of_week#148]
PushedFilters: [IsNotNull(day_of_week), EqualTo(day_of_week,6.0)]
(2) Filter [codegen id : 1]
Input [3]: [fare_amount#143, hour#144, day_of_week#148]
Condition : (isnotnull(day_of_week#148) AND (day_of_week#148 = 6.0))
(3) Project [codegen id : 1]
Output [3]: [hour#144, fare_amount#143, day_of_week#148]
Input [3]: [fare_amount#143, hour#144, day_of_week#148]
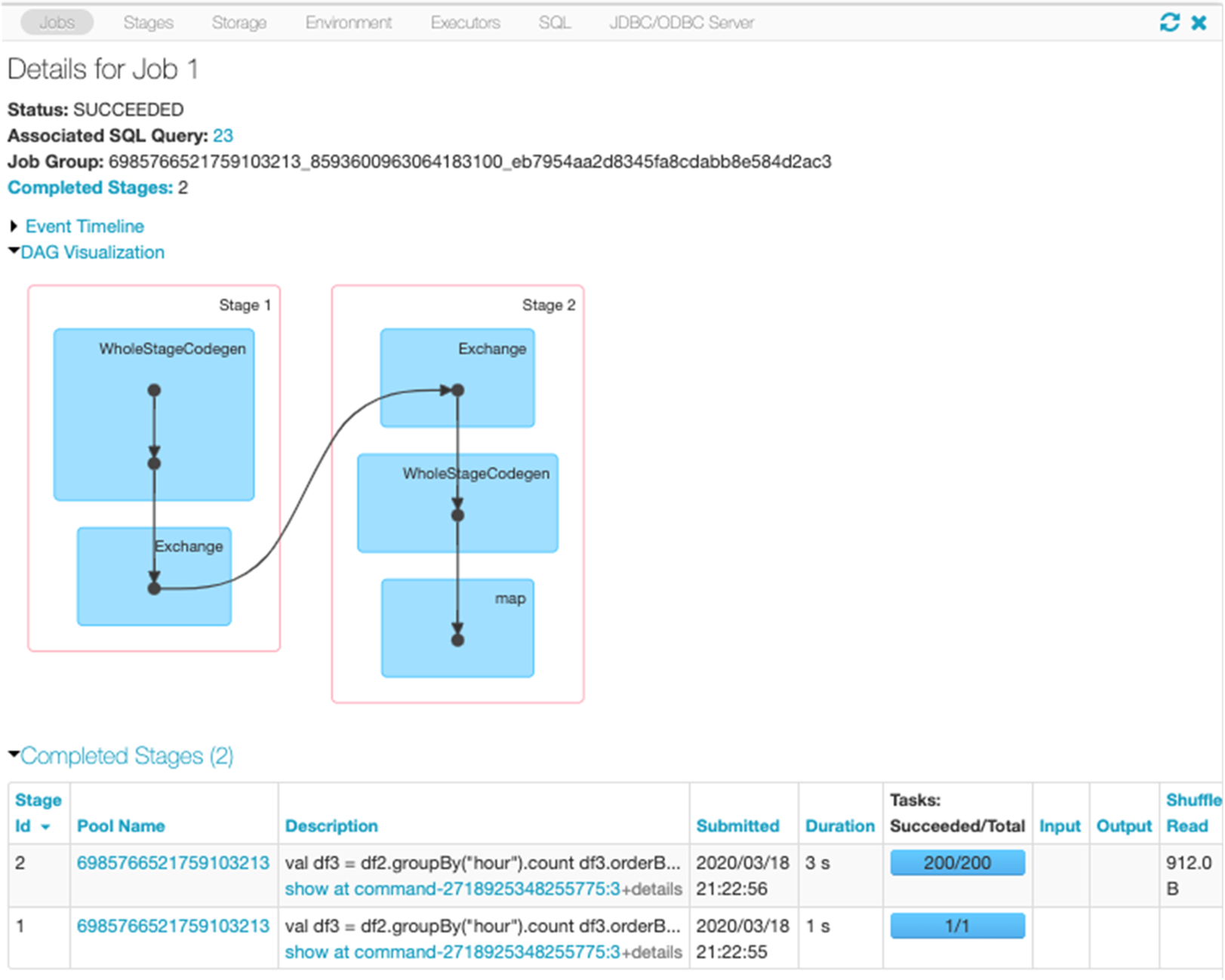
웹 UI SQL 탭에서는 Catalyst에서 생성된 계획에 대해 자세히 볼 수 있습니다. 쿼리 설명 링크를 클릭하면 DAG와 쿼리에 대한 세부 정보가 표시됩니다.
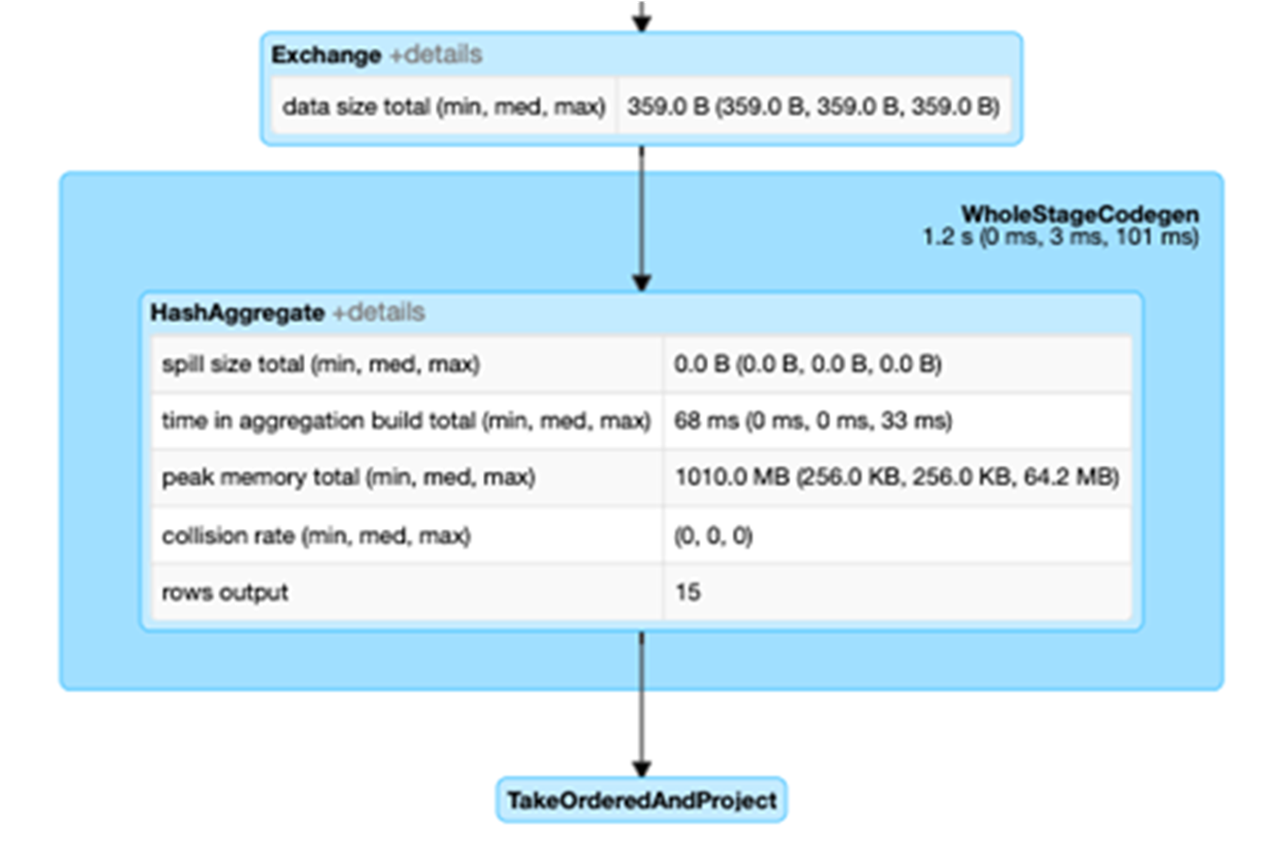
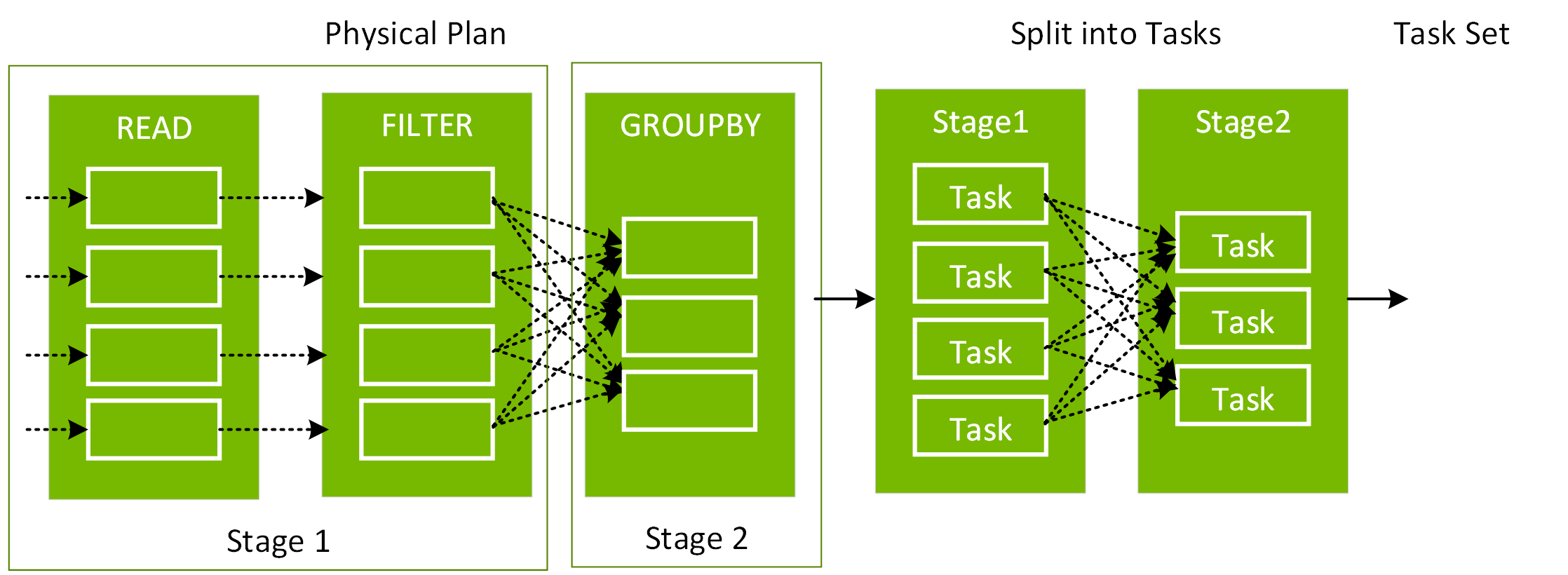
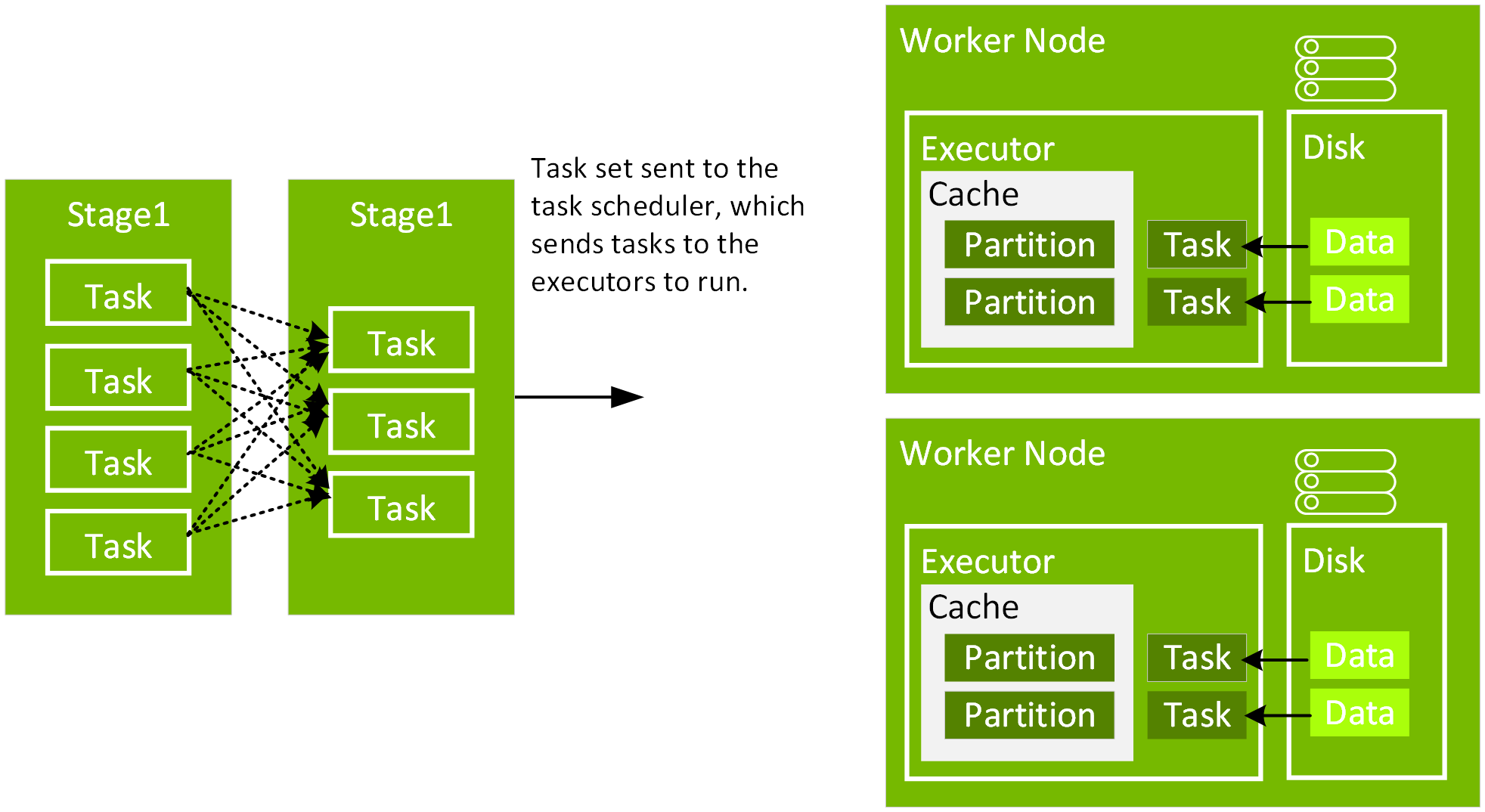
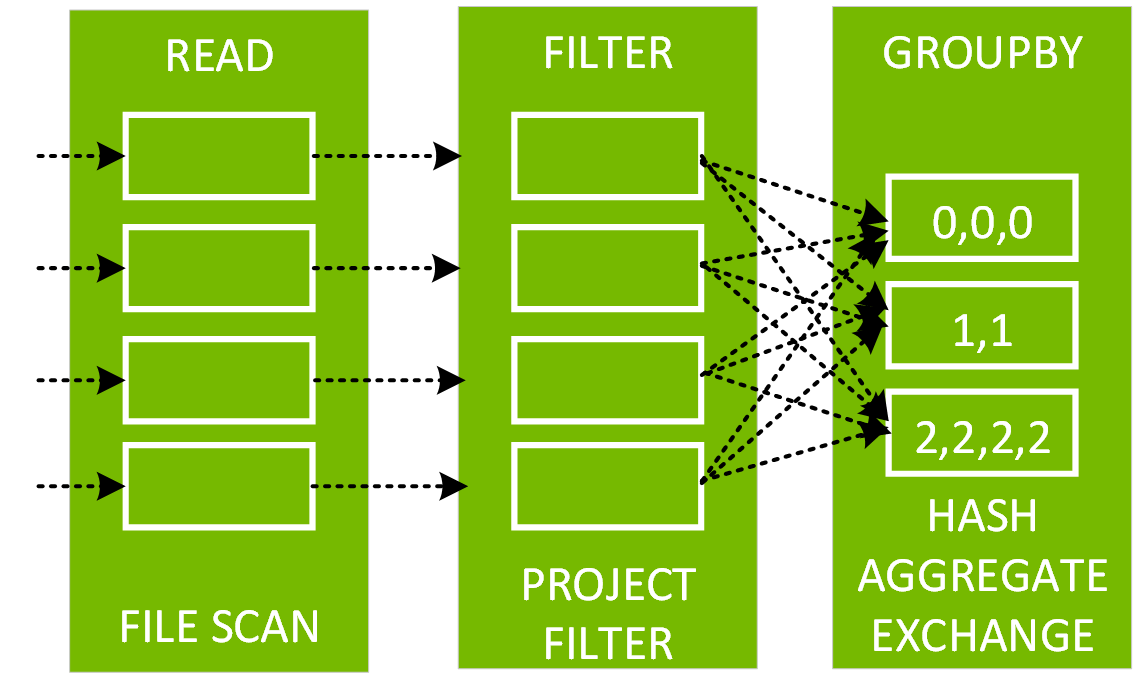
설명 후 다음 코드에서 df3에 대한 물리적 계획은 Scan, Filter, Project, HashAggregate, Exchange 및 HashAggregate로 구성되어 있음을 알 수 있습니다. Exchange는 groupBy 변환에 의해 발생한 셔플입니다. Spark는 Exchange에서 데이터를 셔플하기 전에 각 파티션에 대한 해시 집계를 수행합니다. 교환 후에는 이전 하위 집계의 해시 집계가 만들어집니다. df2가 캐시된 경우 이 DAG에서 파일 스캔 대신 메모리 내 스캔을 하게 됩니다.
val df3 = df2.groupBy("hour").count
df3.orderBy(asc("hour"))show(5)
결과:
+----+-----+
|hour|count|
+----+-----+
| 0.0| 12|
| 1.0| 47|
| 2.0| 658|
| 3.0| 742|
| 4.0| 812|
+----+-----+
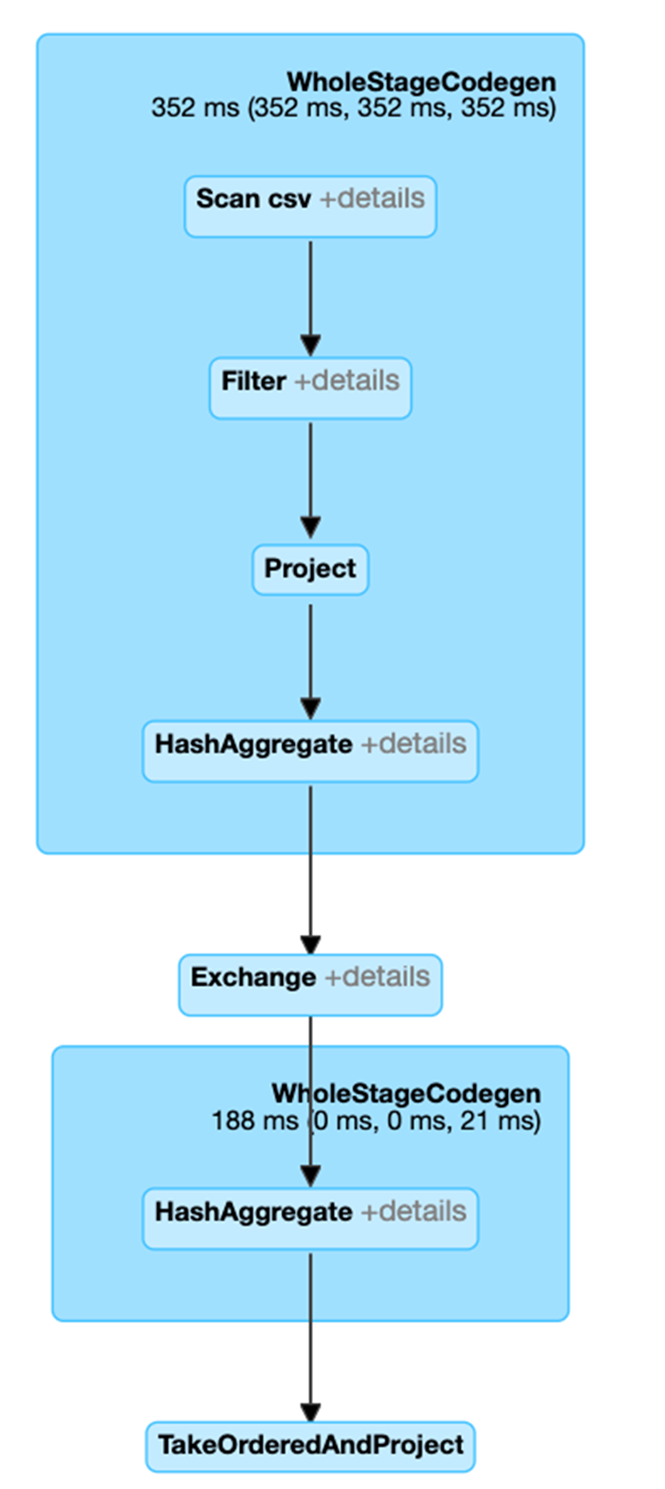
df3.explain
결과:
== Physical Plan ==
* HashAggregate (6)
+- Exchange (5)
+- * HashAggregate (4)
+- * Project (3)
+- * Filter (2)
+- Scan csv (1)
(1) Scan csv
Output [2]: [hour, day_of_week]
(2) Filter [codegen id : 1]
Input [2]: [hour, day_of_week]
Condition : (isnotnull(day_of_week) AND (day_of_week = 6.0))
(3) Project [codegen id : 1]
Output [1]: [hour]
Input [2]: [hour, day_of_week]
(4) HashAggregate [codegen id : 1]
Input [1]: [hour]
Functions [1]: [partial_count(1) AS count]
Aggregate Attributes [1]: [count]
Results [2]: [hour, count]
(5) Exchange
Input [2]: [hour, count]
Arguments: hashpartitioning(hour, 200), true, [id=]
(6) HashAggregate [codegen id : 2]
Input [2]: [hour, count]
Keys [1]: [hour]
Functions [1]: [finalmerge_count(merge count) AS count(1)]
Aggregate Attributes [1]: [count(1)]
Results [2]: [hour, count(1) AS count]
이 쿼리에 대한 SQL 탭 링크를 클릭하면 작업의 DAG가 표시됩니다.
세부 정보 확장 확인란을 선택하면 각 단계에 대한 자세한 정보가 표시됩니다. 첫 번째 블록인 WholeStageCodegen은 성능을 향상시키기 위해 여러 연산자(스캔 csv, 필터, 프로젝트 및 HashAggregate)를 단일 Java 함수로 컴파일합니다. 행 수 및 스필 크기와 같은 메트릭이 다음 화면에 표시됩니다.
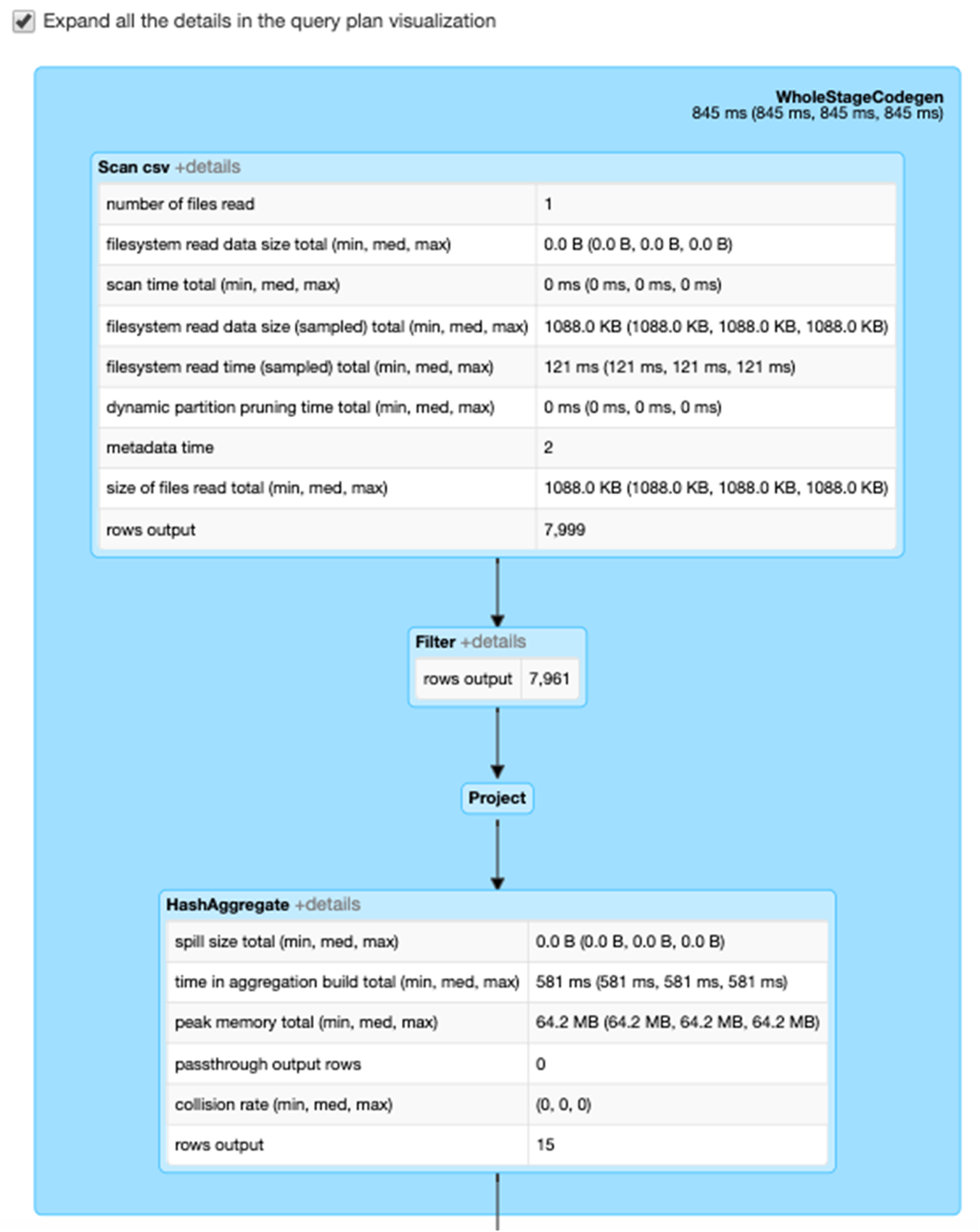
Exchange라는 두 번째 블록에는 작성된 셔플 레코드 수와 데이터 크기 합계를 포함하여 셔플 교환의 메트릭이 표시됩니다.