
Intelligente Dokumentenverarbeitung
Verwandeln Sie komplexe Dokumente, Berichte, Präsentationen, PDFs, Webseiten und Tabellen in durchsuchbare Informationen.
Übersicht: Warum intelligente Dokumentenverarbeitung
Dokumenteneinblicke lesen, verstehen und extrahieren, um die Entscheidungsfindung zu automatisieren
Die intelligente Dokumentenverarbeitung hilft Institutionen dabei, vielfältige multimodale Inhalte – wie Berichte, Verträge, Einreichungen, Richtlinien und Forschungsarbeiten – durch die Identifizierung der wichtigsten Informationen in strukturierte, durchsuchbare Erkenntnisse umzuwandeln.
Die Dokumentenverarbeitung mit offenen NVIDIA Nemotron-Modellen und -Bibliotheken kombiniert hochpräzise Extraktion, multimodalen Abruf und fundierte Generierung. Teams können KI-Agenten erstellen, die Dokumente wie Experten lesen und gleichzeitig die Rückverfolgbarkeit bis zur Originalquelle aufrechterhalten.
Vorteile
Diese umfassen mehrere Bereiche, die Teams aus Analysten, Forschern und Endbenutzern helfen, bessere Ergebnisse zu erzielen.
- Schnellere Erkenntnisgewinnung: Automatisieren Sie die Überprüfung umfangreicher Berichte, Verträge und Richtlinien, damit Teams innerhalb von Sekunden statt Stunden Antworten erhalten.
- Skalierbare Dokumenten-Workloads: Verarbeiten Sie Millionen von PDFs, Webseiten und Tabellen parallel, wenn neue Daten eingehen, ohne dass sich die Mitarbeiterzahl linear erhöht.
- Höhere Entscheidungsqualität: Bewahren Sie Tabellen, Diagramme und Abbildungen, damit KI-Agenten anhand derselben Beweise schlussfolgern, denen Experten heute vertrauen.
- Prüffähigkeit und Compliance: Verankern Sie jede Antwort in zitierten Seiten und Tabellen, um strenge behördliche und interne Audit-Anforderungen zu erfüllen.
- Branchenübergreifende Auswirkungen: Unterstützen Sie verschiedene Workflows in den Bereichen Finanzen, Recht und Wissenschaft mit einer intelligenten Pipeline, die sich an verschiedene Dokumenttypen und Bereiche anpasst.
Quick-Links
Edison Scientific: Kosmos AI Scientist synthetisiert Zehntausende von Forschungsarbeiten
Edison Scientific, ein Spin-out von FutureHouse, entwickelt derzeit Kosmos, einen KI-Wissenschaftler, der zu autonomer Entdeckung fähig ist. Kosmos ist ein Multi-Agent-System mit einem spezialisierten Literaturagenten, der für die Beantwortung von Fragen zu wissenschaftlicher Literatur, klinischen Studien und Patenten entwickelt wurde. Der von Nemotron Parse unterstützte Literaturagent durchsucht autonom über 175 Millionen Dokumente, um Fragen von Forschern zu beantworten und unterstützt mehr als 50.000 Wissenschaftler bei ihrer Entdeckungsarbeit.
Für jede Seite gibt Nemotron Parse semantischen Text für die Einbettung und Suche zurück und segmentiert dann die visuellen Bildregionen für multimodales LLM-Reasoning.
Wissenschaftliche Arbeiten werden nicht nach einem gemeinsamen Standard geschrieben und enthalten häufig komplexe Abbildungen, die falsch interpretiert werden können. Nemotron Parse ist entscheidend für die Identifizierung relevanter Texte, Tabellen und Abbildungen in einer PDF-Datei, die ein LLM dann analysieren und Antworten auf Benutzerabfragen generieren kann.
Edison-Literatur-Agent hilft bei Folgendem:
- Reduzierung manueller Arbeit durch das Verständnis großer Datenmengen
- Schnellere Analyse durch Extrahieren wichtiger Details
- Verbesserung der Qualität von Entscheidungen, die sowohl von Tools als auch von Menschen getroffen werden
Das schnelle und genaue Verständnis wissenschaftlicher Literatur ist eine entscheidende Komponente, die es Kosmos ermöglicht hat, Forschung aus 6 Monaten an einem Tag mit einer Reproduzierbarkeit von 80 % zu absolvieren.
Quick-Links
Technische Umsetzung
Architekturaufbau

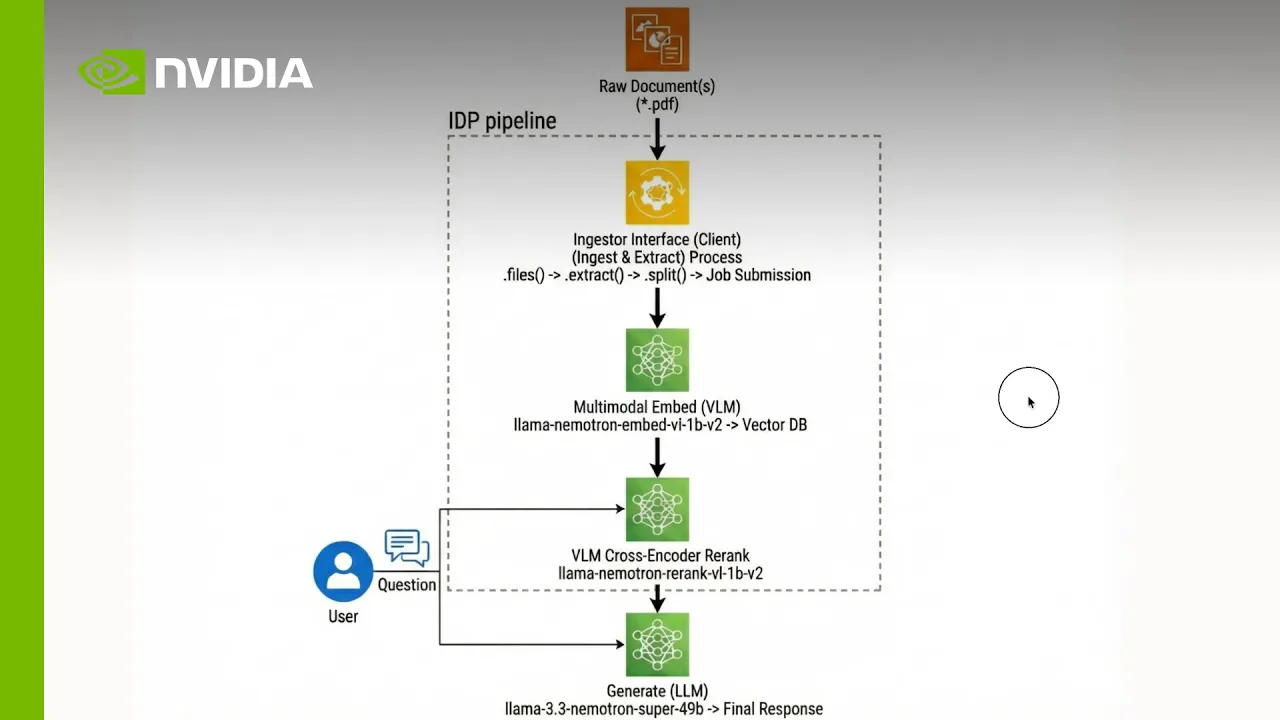
Eine intelligente Dokumentenverarbeitungspipeline basiert auf drei Kernkomponenten: Extraktion, Einbettung und Indexierung sowie Reranking für die Antwortgenerierung.
Entwickler können mit offenen Modellen, NeMo Retriever und NIM-Microservices konfigurieren, erweitern und bereitstellen.
1. Extraktion: Verwandeln komplexer Dokumente in strukturierte Daten
Verwenden Sie die NeMo Retriever-Bibliothek mit selbstgehosteten oder von NVIDIA gehosteten Parsing- und OCR-Diensten, um PDFs, Webseiten und andere multimodale Dokumente zu erfassen und sie in strukturierte Einheiten wie Text-Abschnitte, Markdown-Tabellen und Chart-Crops zu konvertieren und gleichzeitig das Layout und die Semantik beizubehalten. Diese Phase „erschließt“ umfangreiche Inhalte, indem Tabellen als Tabellen und Abbildungen als Bilder behandelt werden und JSON-Ausgaben erzeugt werden, die von nachgelagerten Abruf- und Generierungsmodellen zuverlässig genutzt werden können.
2. Einbettung und Indexierung: Inhalte in großem Maßstab durchsuchbar machen
Führen Sie extrahierte Elemente in multimodale Nemotron-Einbettungsmodelle ein, um Text, Tabellen und Diagramme in dichte Vektoren zu kodieren, die auf den Dokumentenabruf zugeschnitten sind. Speichern Sie diese Vektoren und die zugehörigen Metadaten in einer Vektor-Datenbank wie Milvus, um eine semantische Suche in Millisekunden über Millionen von Dokumentelementen zu ermöglichen und die Wissensdatenbank kontinuierlich auf dem neuesten Stand zu halten, wenn neue Inhalte eintreffen.
3. Reranking und Generierung von begründeten Antworten: Zitierte, hochpräzise Antworten liefern
Rufen Sie Top-K-Kandidaten aus dem Vektor-Index ab und wenden Sie Nemotron-Cross-Encoder-Reranking an, um die Passagen, Tabellen und Abbildungen zu priorisieren, die die Frage eines Benutzers am besten beantworten. Geben Sie diesen neu eingestuften Kontext in ein Nemotron-Generierungsmodell weiter, das fundierte Antworten mit expliziten Zitaten auf die Originalseiten und Diagramme erzeugt, sodass Geschäfts-, Finanz- und wissenschaftliche Teams jeder vom System unterstützten Entscheidung vertrauen und diese überprüfen können.
Code-Walkthrough für die Erstellung einer intelligenten Dokumentenverarbeitungspipeline mit offenen Nemotron-Technologien
Quick-Links
Partnernetzwerk
Quick-Links
FAQs
Eine NVIDIA RAG-Pipeline in Produktionsqualität umfasst eine Vektor-Datenbank und containerisierte NIM-Microservices oder eine Kubernetes-basierte Bereitstellung, um Extraktion, Einbettung und Abruf über große Dokumentenvolumen hinweg zu skalieren. Für selbst gehostete Bereitstellungen sollten NVIDIA-GPUs mit ausreichendem VRAM gewählt werden. Alternativ können gehostete Endpunkte die Anforderungen an die lokale Infrastruktur reduzieren. Außerdem sollten Sie Extraktionseinstellungen (wie Tabellenausgabeformat und Aufteilung auf Seitenebene) anpassen, geeignete Nemotron-Extraktions-, Einbettungs- und Reranking-Modelle auswählen und das System instrumentieren, um Durchsatz, Latenz und Zitierqualität zu messen, um Unternehmens-SLAs zu erfüllen.
Nemotron Parse nutzt eine Vision-Language-Architektur mit Spatial Grounding, um Text, Tabellen, Diagramme und Layout-Elemente zu erkennen und zu extrahieren und strukturierte, maschinenlesbare Ausgaben anstelle von flachem Text zu erzeugen. Es bewahrt die Tabellenstruktur, Lesereihenfolge und semantische Klassen, verbessert die Genauigkeit bei anspruchsvollen Benchmarks erheblich und macht den nachgelagerten Abruf und das Reasoning über PDFs, Scans und komplexe Berichte viel zuverlässiger. Diese strukturierten Ausgaben können auch mehr semantisches Chunking unterstützen, was Abrufsystemen dabei hilft, Dokumente entlang aussagekräftiger Inhaltsgrenzen aufzuteilen, anstatt nach willkürlichen Textfenstern.
Antwort: In einer RAG-Pipeline bestimmt die Extraktionsstufe die Qualität und Struktur der für den Abruf verfügbaren Belege. Verwenden Sie PDFium für digital erstellte PDFs, wenn der Durchsatz Priorität hat, OCR, wenn Sie eine visuelle Extraktion mit einer starken Balance zwischen Geschwindigkeit und Genauigkeit wünschen, und Nemotron Parse, wenn ein ausführlicheres Layout und eine umfassendere Dokumentenstruktur die Chunking- und Abrufqualität verbessern. In NeMo Retriever leitet die Auswahl des OCR-Extraktionspfads die Dokumentenextraktion über den NeMo Retriever-OCR-Dienst.
Kurz gesagt: PDFium eignet sich am besten für digital erstellte PDFs, OCR balanciert Geschwindigkeit und visuelle Extraktion und Nemotron Parse priorisiert Layout-Genauigkeit und semantische Struktur.
Quick-Links