Inferencia
Servidor de inferencia NVIDIA Triton
Implemente, ejecute y escale la IA para cualquier aplicación en cualquier plataforma.
Inferencia para todas las cargas de trabajo de IA
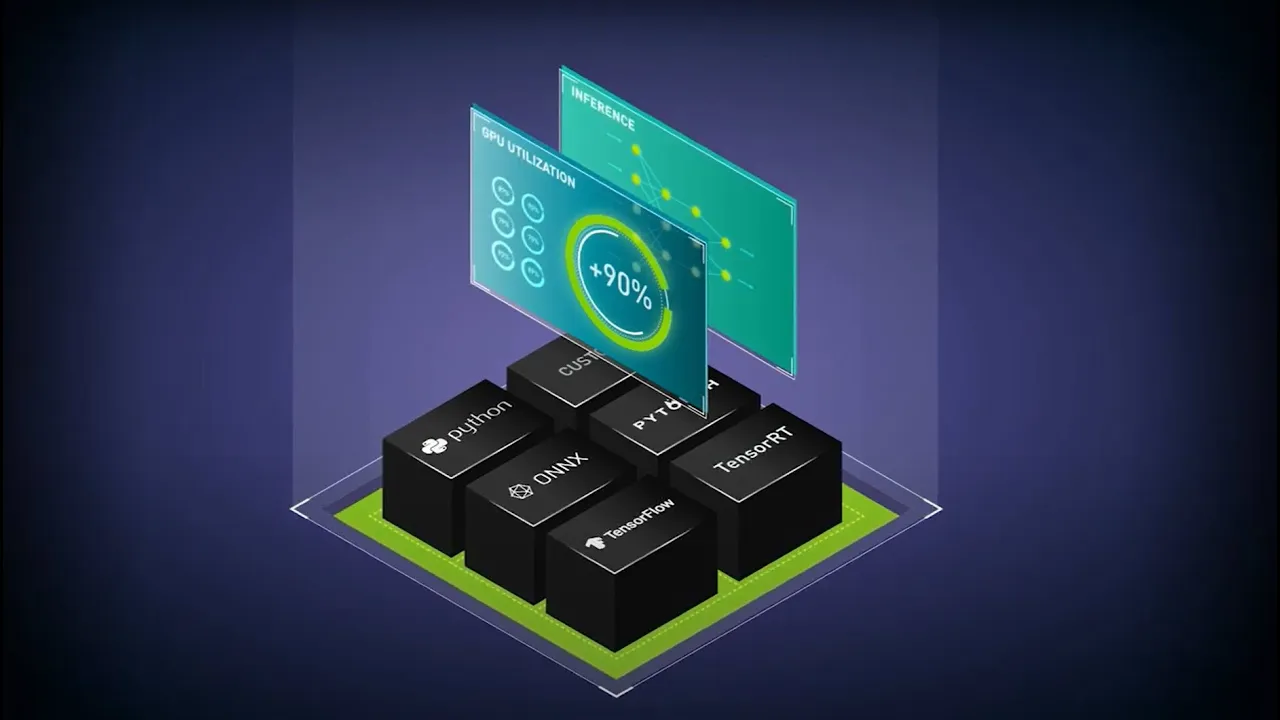
Ejecute la inferencia en modelos de aprendizaje automático o deep learning entrenados desde cualquier entorno en cualquier procesador (GPU, CPU u otro) con el servidor de inferencia NVIDIA Triton™. Como parte de la plataforma de IA de NVIDIA y disponible con NVIDIA AI Enterprise, el servidor de inferencia Triton es un software de código abierto que estandariza la implementación y ejecución de modelos de IA en todas las cargas de trabajo.
Ventajas del servidor de inferencia Triton

Compatible con todos los entornos de entrenamiento e inferencia
Implemente modelos de IA en cualquier entorno principal con el servidor de inferencia Triton, incluidos TensorFlow, PyTorch, Python, ONNX, NVIDIA® TensorRT™, RAPIDS™ cuML, XGBoost, Scikit-learn RandomForest, OpenVINO y C++ personalizado, entre otros.

Inferencia de alto rendimiento en cualquier plataforma
Maximice el rendimiento y el uso con el procesamiento por lotes dinámico, la ejecución simultánea, la configuración óptima y la transmisión de audio y vídeo. El servidor de inferencia Triton es compatible con todas las GPU NVIDIA, CPU x86 y Arm, así como con AWS Inferentia.

Código abierto y diseñado para DevOps y MLOps
Integre el servidor de inferencia Triton en soluciones DevOps y MLOps, como Kubernetes para escalar y Prometheus para supervisar. También se puede utilizar en las principales plataformas de IA y MLOps, tanto en la nube como en las instalaciones.

Seguridad de nivel empresarial, administración y estabilidad de la API
NVIDIA AI Enterprise, que incluye el servidor de inferencia NVIDIA Triton, es una plataforma de software de IA segura y preparada para la producción. Está diseñada para acelerar el tiempo de obtención de valor con asistencia, seguridad y estabilidad de la API.
Explore las funciones y herramientas del servidor de inferencia NVIDIA Triton

Inferencia del modelo lingüístico de gran tamaño
Triton ofrece baja latencia y alto rendimiento para la inferencia de modelos lingüísticos de gran tamaño. Es compatible con TensorRT-LLM, una biblioteca de código abierto para definir, optimizar y ejecutar LLM para la inferencia en producción.

Conjuntos de modelos
Los Conjuntos de modelos Triton te permiten ejecutar cargas de trabajo de IA con varios modelos, canalizaciones y pasos de preprocesamiento y posprocesamiento. Además, permite la ejecución de diferentes partes del conjunto en CPU o GPU y es compatible con varios entornos dentro del conjunto.

NVIDIA PyTriton
PyTriton permite a los desarrolladores de Python incluir Triton con una sola línea de código y utilizarla para ofrecer modelos, funciones de procesamiento sencillas o canalizaciones de inferencia completas para acelerar la creación de prototipos y las pruebas.

Analizador de modelos NVIDIA Triton
El Analizador de modelos reduce el tiempo necesario para buscar la configuración de implementación de modelos óptima, como el tamaño del lote, la precisión y las instancias de ejecución simultánea. Ayuda a seleccionar la configuración óptima para satisfacer los requisitos de latencia, rendimiento y memoria de la aplicación.
Principales clientes en todos los sectores
-
Cliente
-
Integraciones del ecosistema
Primeros pasos con NVIDIA Triton
Utilice las herramientas adecuadas para implementar, ejecutar y escalar la IA en cualquier aplicación y plataforma.
Empiece a desarrollar con código o contenedores
Las personas que deseen acceder al código abierto y los contenedores de Triton para el desarrollo tienen dos opciones para empezar de forma gratuita:
Probar antes de comprar
Las empresas que deseen probar Triton antes de comprar NVIDIA AI Enterprise para la producción disponen de dos opciones para empezar de forma gratuita:
Recursos
-
Videos
-
Formación
-
Blogs
-
Sesiones
-
Casos de éxito
-
Comunidad


















Pasos siguientes
¿Todo listo para empezar?
Utilice las herramientas adecuadas para implementar, ejecutar y escalar la IA en cualquier aplicación y plataforma, o bien explore más recursos de desarrollo.
Contactar con nosotros
Hable con un especialista en productos de NVIDIA sobre cómo pasar de la fase piloto a la de producción con la seguridad, estabilidad de la API y soporte de NVIDIA AI Enterprise.
Obtenga las últimas noticias sobre el servidor de inferencia NVIDIA Triton
Suscríbase para obtener las últimas noticias, actualizaciones y mucho más de NVIDIA.