Thomas Davenport 在《Competing on Analytics》一書的更新版本中表示,分析技術在過去十年間發生巨變。現在設備伺服器可執行更強大而實惠的分散式運算,而更為精良的機器學習 (ML) 技術使公司能儲存並分析各種不同類型且更大量的資料。
前言:GPU 為何能推動資料科學發展?
資料分析的演變
巨量資料處理的起始
Google 發明了分散式檔案系統與彈性分散式處理框架 MapReduce,以便在設備伺服器的大規模叢集中,對網路上爆量的內容進行分類。Google 檔案系統 (GFS) 將叢集資料節點中的檔案資料分割、分散並複製。MapReduce 則將運算分散於叢集的各個資料節點中,方法如下:使用者指定可處理索引鍵/值組來產生一組中繼索引鍵/值組的對應功能,再指定能合併與同一中繼金鑰相關之所有中間值的歸納功能。GFS 和 MapReuce 皆專為容錯而設計,藉由容錯移轉至另一節點以進行資料處理。
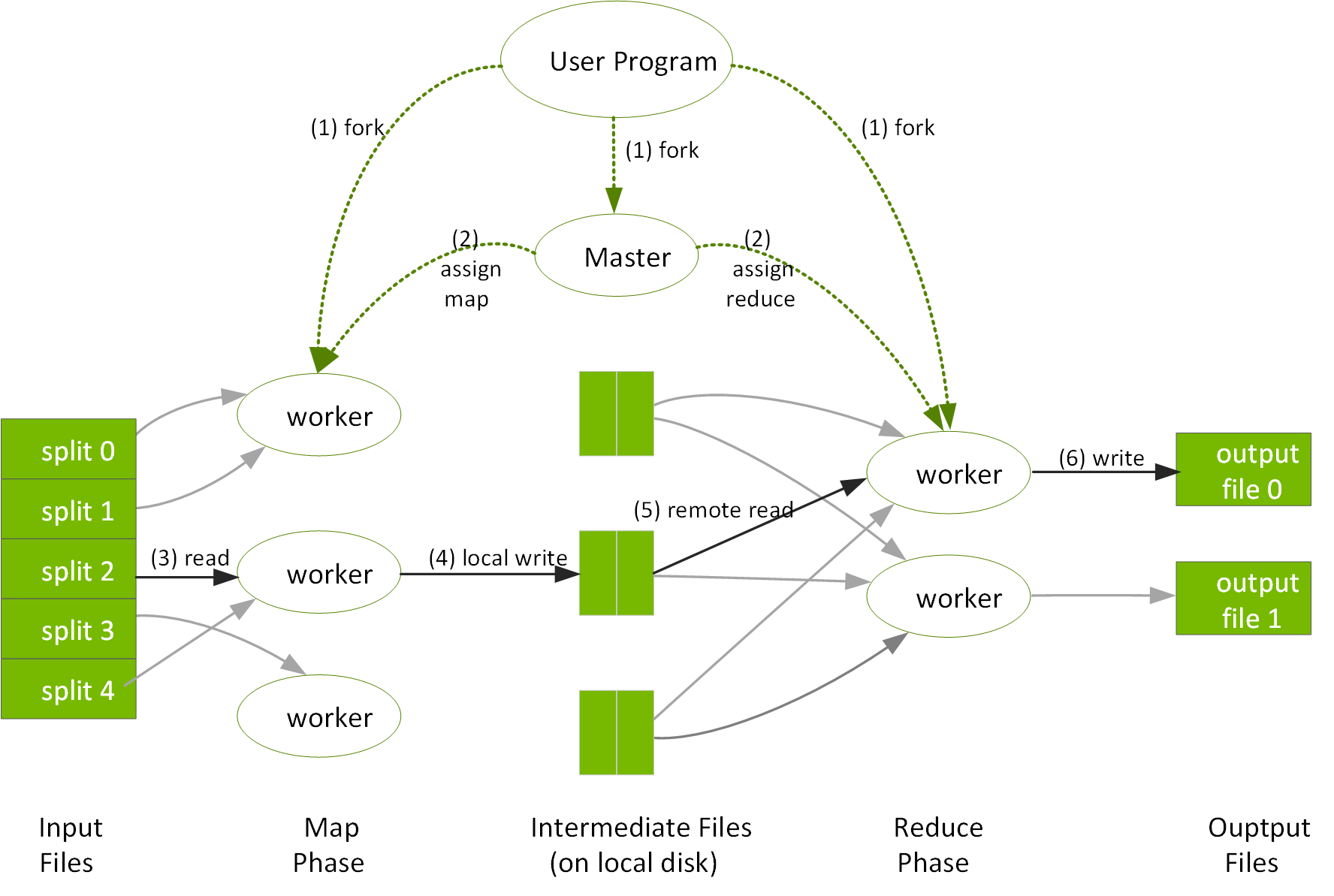
參考資料:MapReduce Google 白皮書
在 Google 發表描述 MapReduce 框架的白皮書一年之後,Doug Cutting 與 Mike Cafarella 打造了 Apache Hadoop。
然而,Hadoop 的效能卻在檢查點結果傳送至磁碟的模型上遇到瓶頸。與此同時,Hadoop 的普及也受到 MapReduce 低階程式設計模型的阻礙。資料流程與迭代演算需要將多個 MapReduce 工作鏈結在一起,不僅程式難以設計,更為磁碟帶來大量讀取與寫入作業。
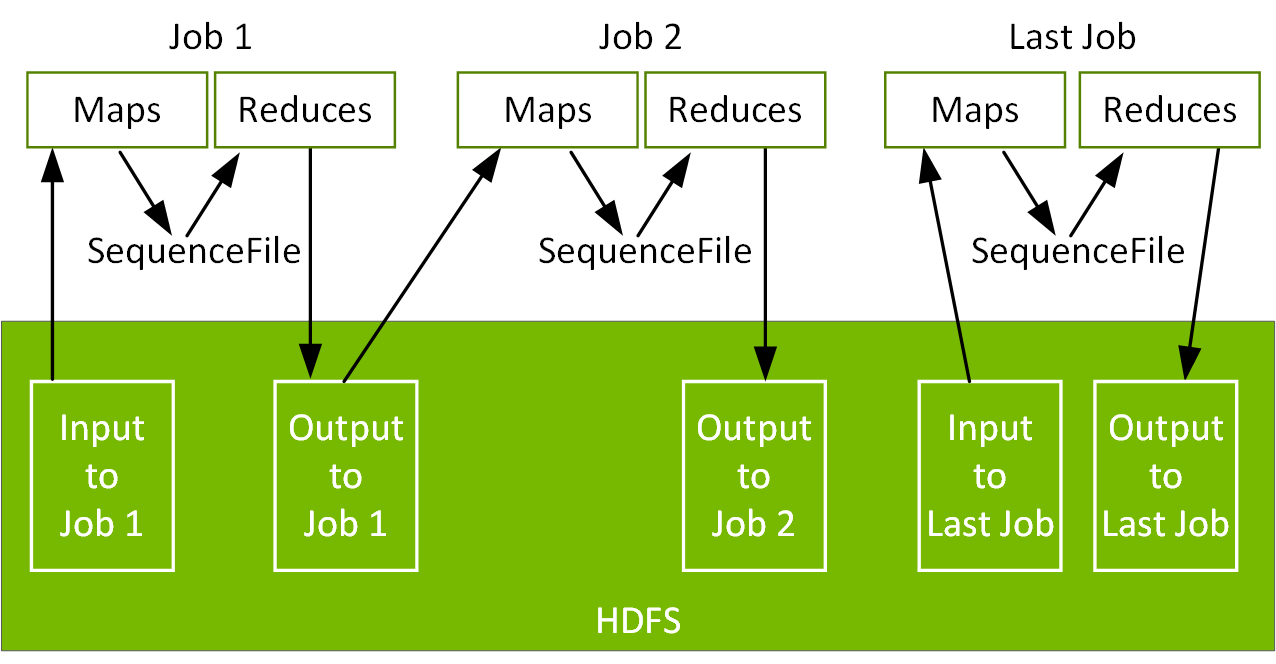
Apache Spark 讓巨量資料處理變得更快、更容易
Apache Spark 最初是加州大學柏克萊分校 AMPLab 的研究專案,後於 2014 年成為 Apache 軟體基金會的高階專案,現由上百名來自不同組織的開發人員所組成的社群共同維護。Spark 的開發目的是為了保持 MapReduce 可擴充、分散與容錯處理框架的優點,同時提高效率並使其更易於使用。Spark 的資料流程及迭代演算效率比 MapReduce 來得好,因為 Spark 將資料快取於迭代間的記憶體內,同時使用較輕量的執行緒。Spark 提供的功能程式設計模型也比 MapReduce 來得更豐富。
分散式資料工作表
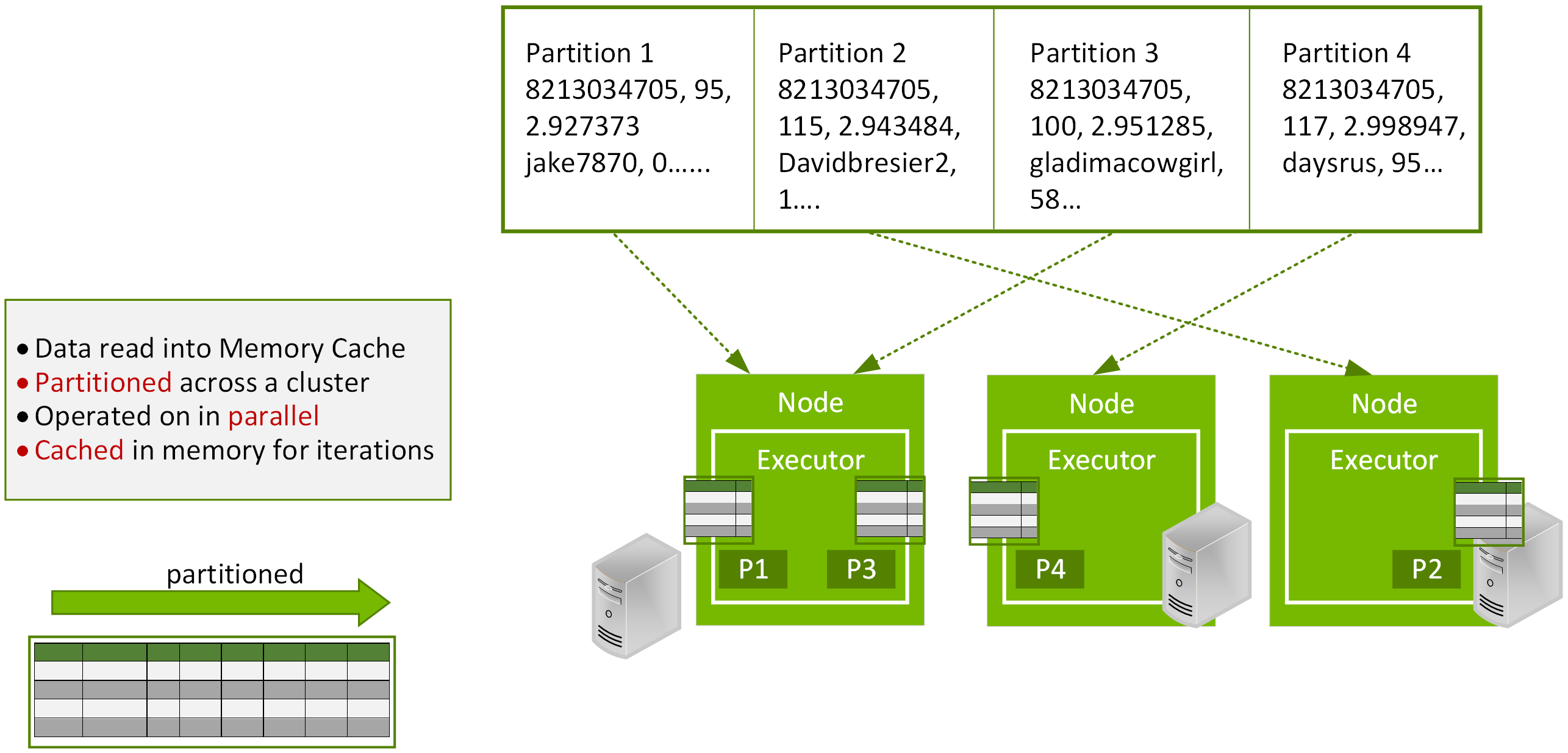
Spark 雖然減輕了 Hadoop 上發生的輸入/輸出 (I/O) 問題,但現在越來越多應用程式的瓶頸從 I/O 變成了運算。還好,伴隨 GPU 加速運算的發展,這個效能瓶頸有了解套之道。
GPU 加速運算處理
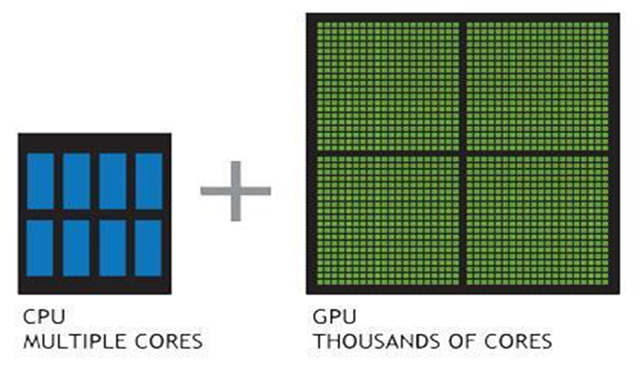
繪圖處理器 (GPU) 因為每次浮點運算 (效能) 的價格極為低廉而大受歡迎,如今更透過加快平行處理的多核心伺服器,有效解決運算效能遭遇的瓶頸。
CPU 由幾個針對連續序列處理進行最佳化的核心組成。而 GPU 則擁有大規模的平行架構,由上千個更小、效率更高的核心所組成,專為同時處理多項工作而設計。比起只包含 CPU 的設定,GPU 處理資料的速度快上許多。
一旦有大量的資料需要在叢集的節點間廣播、彙總或收集,網路就可能成為瓶頸。GPUDirect 遠端直接記憶體存取與 NVIDIA 集合通訊函式庫可讓 GPU 直接在節點間彼此聯絡,實現更高速的多 GPU 與多節點歸納作業,有效解決瓶頸問題。
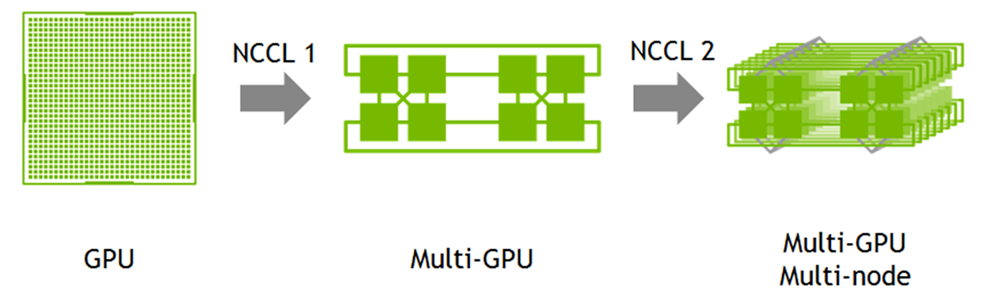
GPUDirect 遠端直接記憶體存取 (RDMA) 的優點對於大規模且複雜的提取、轉換、載入 (ETL) 工作負載也是關鍵,因為如此一來,工作負載就能宛如在一台大型伺服器上般順暢運作。
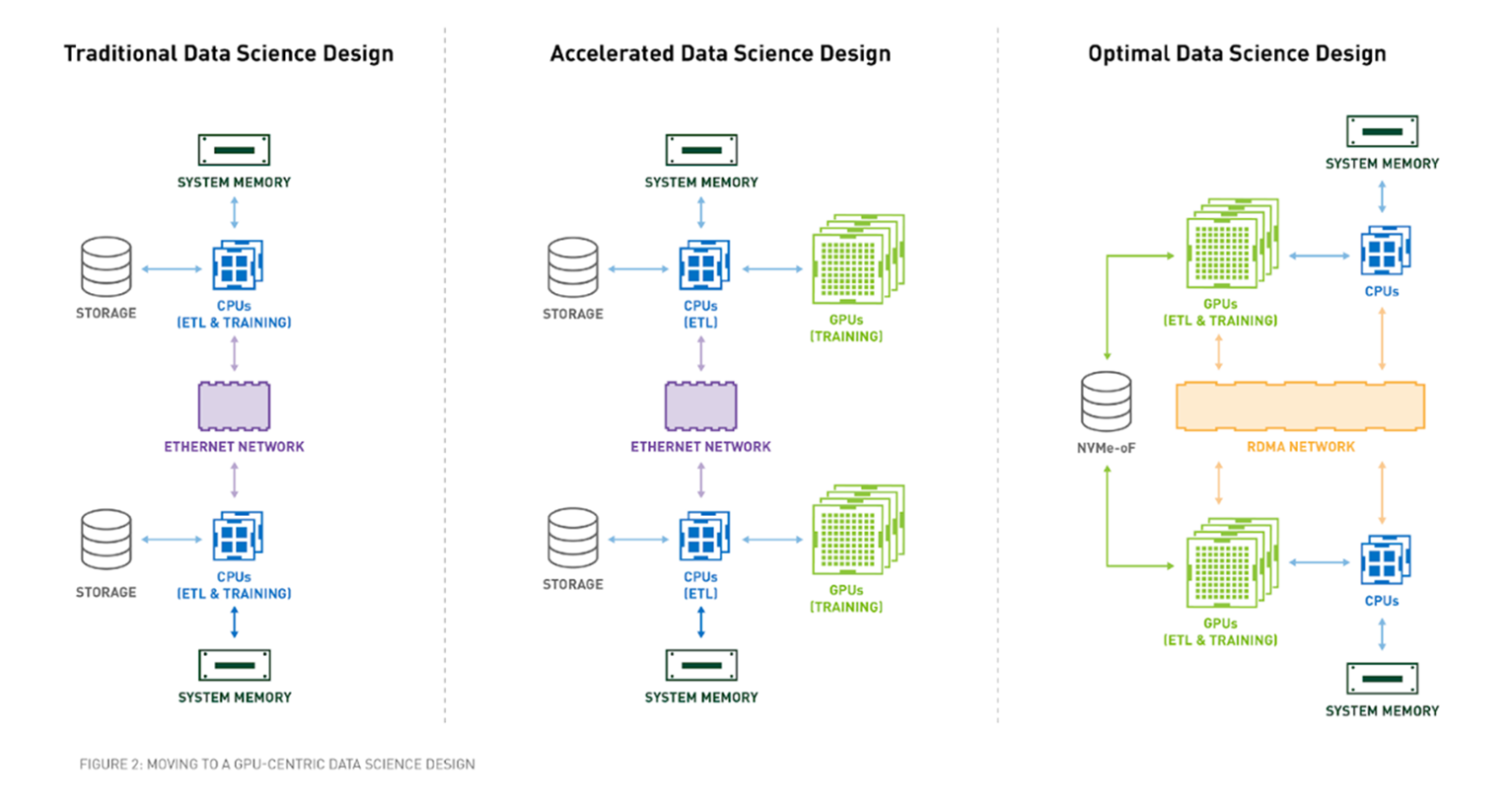
RAPIDS 支援的 GPU 加速資料科學
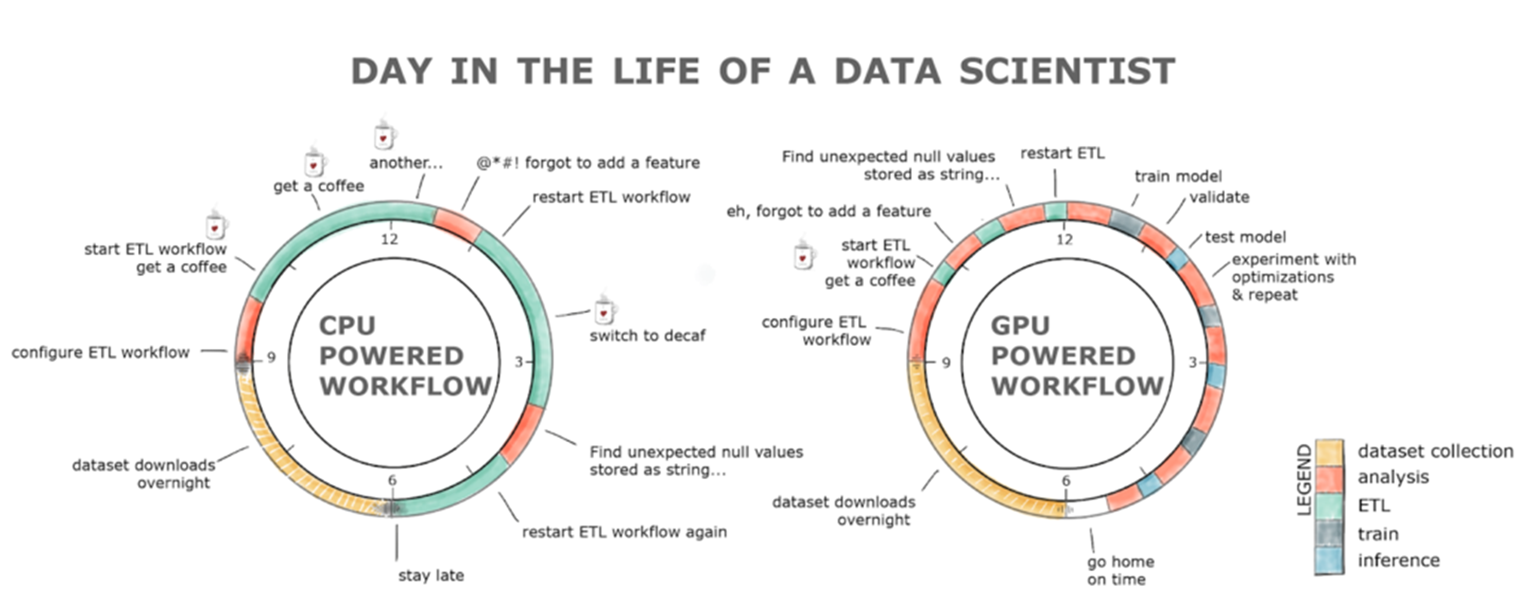
資料探索是資料科學的關鍵要素之一。要為機器學習準備資料集,就要瞭解資料集、清理和操控資料類型與格式,並為學習演算法擷取特徵。這類工作都被歸類在 ETL 的範圍之下。ETL 通常是一個迭代的探索性過程。隨著資料集的增加,此過程在 CPU 上運作的互動力便會下降。
過去幾年來,GPU 一直是深度學習 (DL) 發展的原動力,而 ETL 及傳統機器學習工作負載則繼續以 Python 編寫,且通常搭配 Scikit-Learn 等單一執行緒工具或 Spark 等大型多 CPU 分散式解決方案。
RAPIDS 是一套開放原始碼軟體函式庫與 API,專為完全於 GPU 上執行的端對端資料科學與分析流程而設計,且可在典型端對端資料科學工作流程中實現 50 倍以上的加速比。RAPIDS 加速了包括資料載入在內的整個資料科學流程,實現更具生產力、互動性與探索性的工作流程。
RAPIDS 以 GPU 運算架構與軟體平台 NVIDIA® CUDA® 為基礎,透過易於使用的 API,展現 GPU 平行運算技術與高頻寬記憶體速度。RAPIDS 著重分析與資料科學的常見資料準備工作,透過熟悉的 DataFrame API 提供強大的 GPU DataFrame,並與 ApacheArrow 資料結構相容。
Apache Arrow 制定了標準化、跨語言並針對資料區域最佳化的欄式記憶體格式,加快現代 CPU 或 GPU 的分析處理效能,同時在無需序列化額外負荷的情況下,提供零複製串流訊息與程序間的通訊。
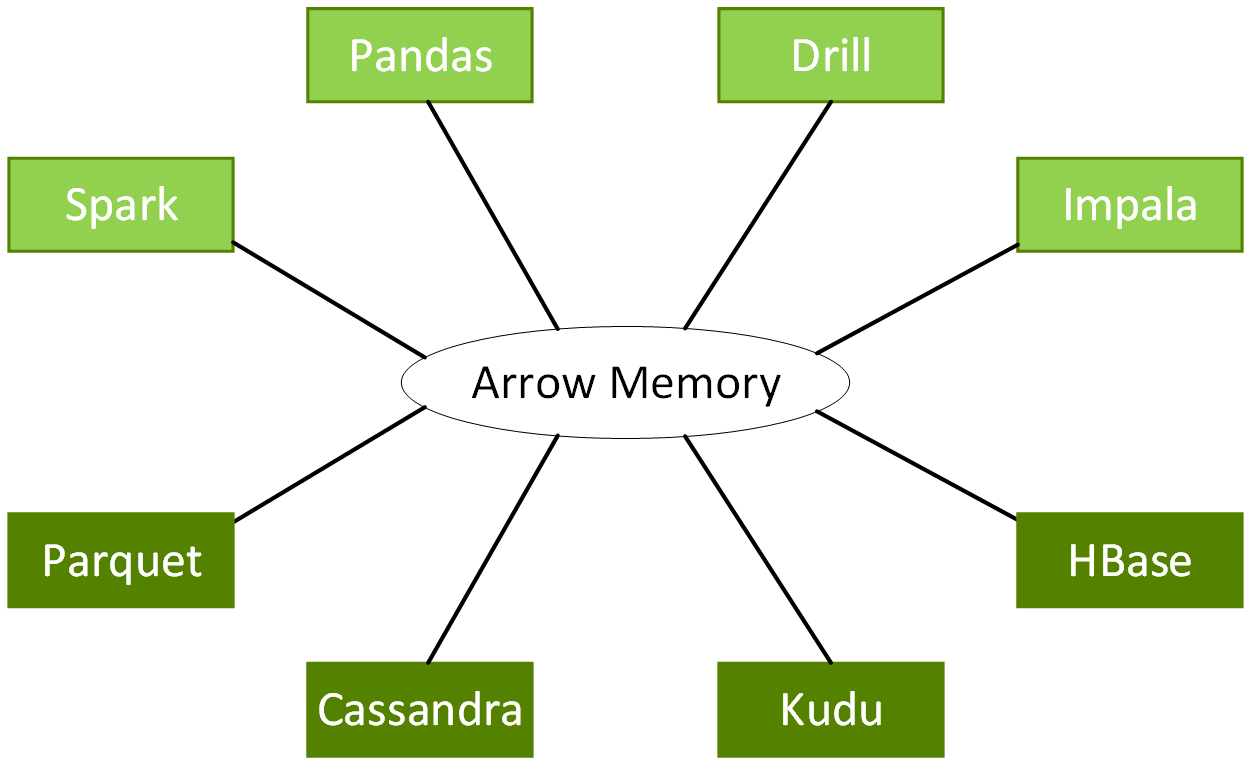
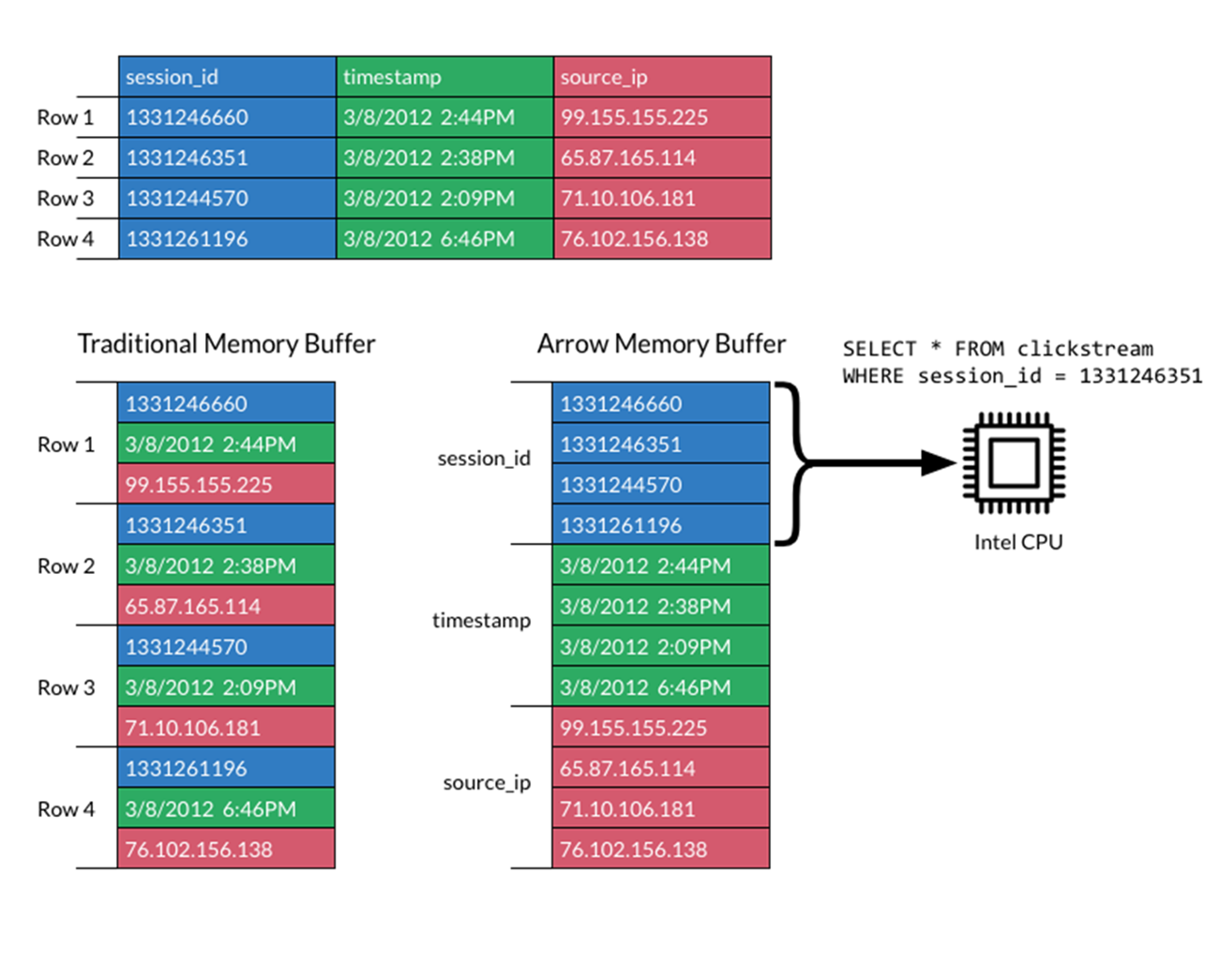
DataFrame API 能在不產生典型序列化與還原序列化成本的情況下,與各種機器學習演算法整合,進而實現端對端流程加速。
藉由隱藏低階 CUDA 程式設計的複雜性,RAPIDS 打造出執行資料科學工作的簡易之道。由於有更多資料科學家使用 Python 和其他高階語言,因此對於快速改善開發時間來說,少量甚至無需修改程式碼即可加速這一點非常重要。
利用 GPU 與 RAPIDS 函式庫提升資料科學框架
RAPIDS 加速發展的另一種方式是整合頂尖資料科學框架,包括 PyTorch、Chainer 及深度學習專用的 ApacheMxNet,還有 Apache Spark 與 Dask 等分散式運算框架,以從 GPU 工作站流暢擴充至多 GPU 伺服器與多節點叢集。此外,開放原始碼 SQL 引擎 BlazingSQL 之類的產品現更以 RAPIDS 為基礎,為使用者提供更多的加速功能。
Apache Spark 3.x 提供使用者 API 與設定,可輕鬆要求並使用 GPU 來增強 GPU 應用程式效能,現在更進一步在 GPU 上實現欄式處理;這些都是 Spark 3.x 以前未支援的功能。Spark 於內部添加 GPU 排程,進一步與叢集管理員 (YARN、Kubernetes 等) 整合以便請求 GPU,並添加外掛程式點以利延展並在 GPU 上執行操作。因此 Spark 應用程式開發人員能更輕鬆要求並使用 GPU,還能與深度學習及人工智慧框架 (如 Spark 上的 Horovod 及 TensorFlow) 更為緊密整合,更加有效地利用 GPU。這種延展性也有助實現欄式處理,為使用者開啟新增外掛程式以透過 GPU 加速查詢的可能性。
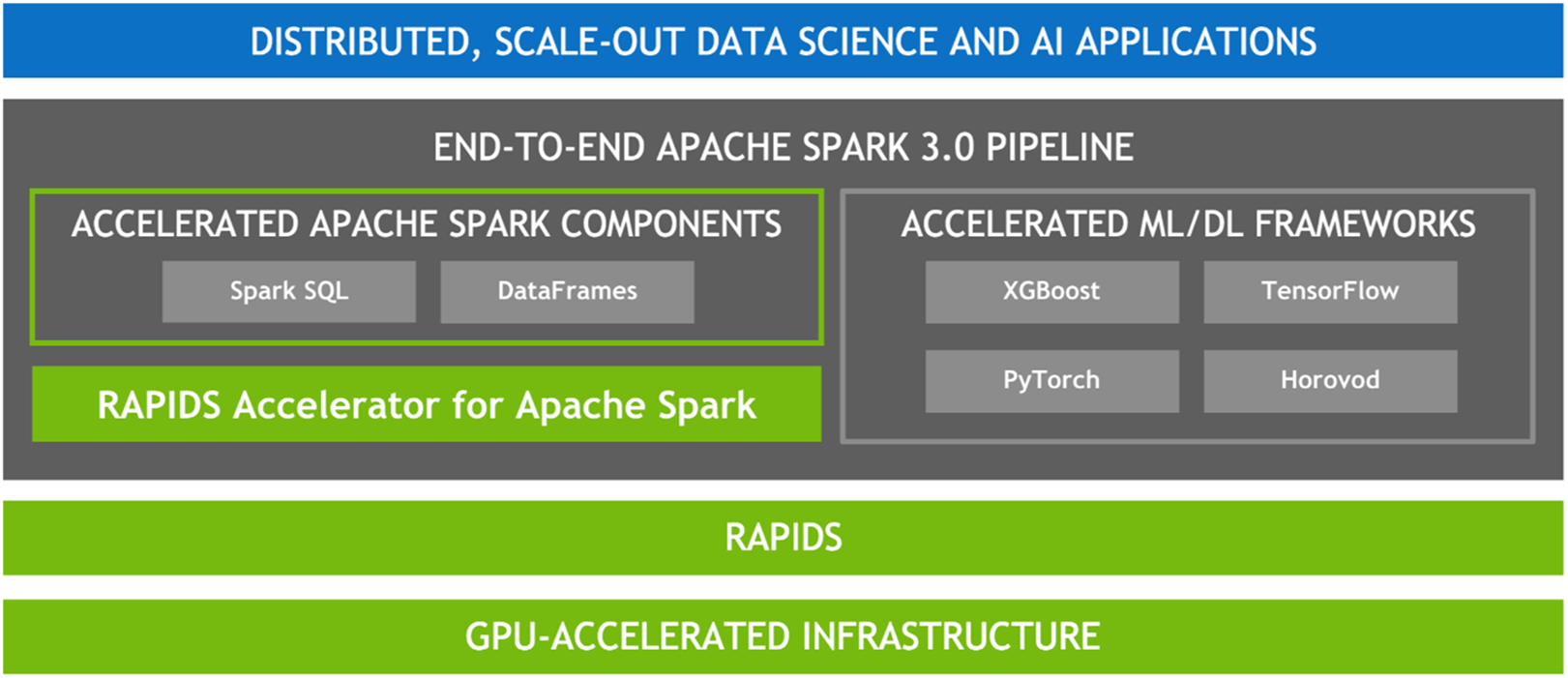
我們將在本電子書繼續探討下方所示的 Apache Spark 3.x 堆疊如何加速 Spark 3.x 應用程式。
GPU 加速的軟體堆疊 APACHE SPARK 3.x
實際執行 NVIDIA GPU
無論產業或使用案例為何,只要將機器學習用於實作,就能將許多資料科學問題分解成類似的步驟,包括:迭代前置處理資料以建立功能、用不同的參數訓練模型,並且評估模型以確保效能轉化為有價值的成果。
RAPIDS 有助加快這一切步驟,同時徹底發揮使用者的硬體投資。早期客戶已讓原本需數日乃至數週的整個資料流程,縮短至幾分鐘即可完成。由於更多迭代有助資料科學家探索更多模型與參數組合,並用更大型的資料集進行訓練,客戶得以同時降低成本並提高模型準確性。
零售商的預測越來越精準。金融公司越來越善於評估信貸風險。廣告技術公司預測點擊率的能力也不斷提升。資料科學家往往能有 1-2 % 的改善。這能轉化為數千萬乃至數億美元的收益與盈利能力。