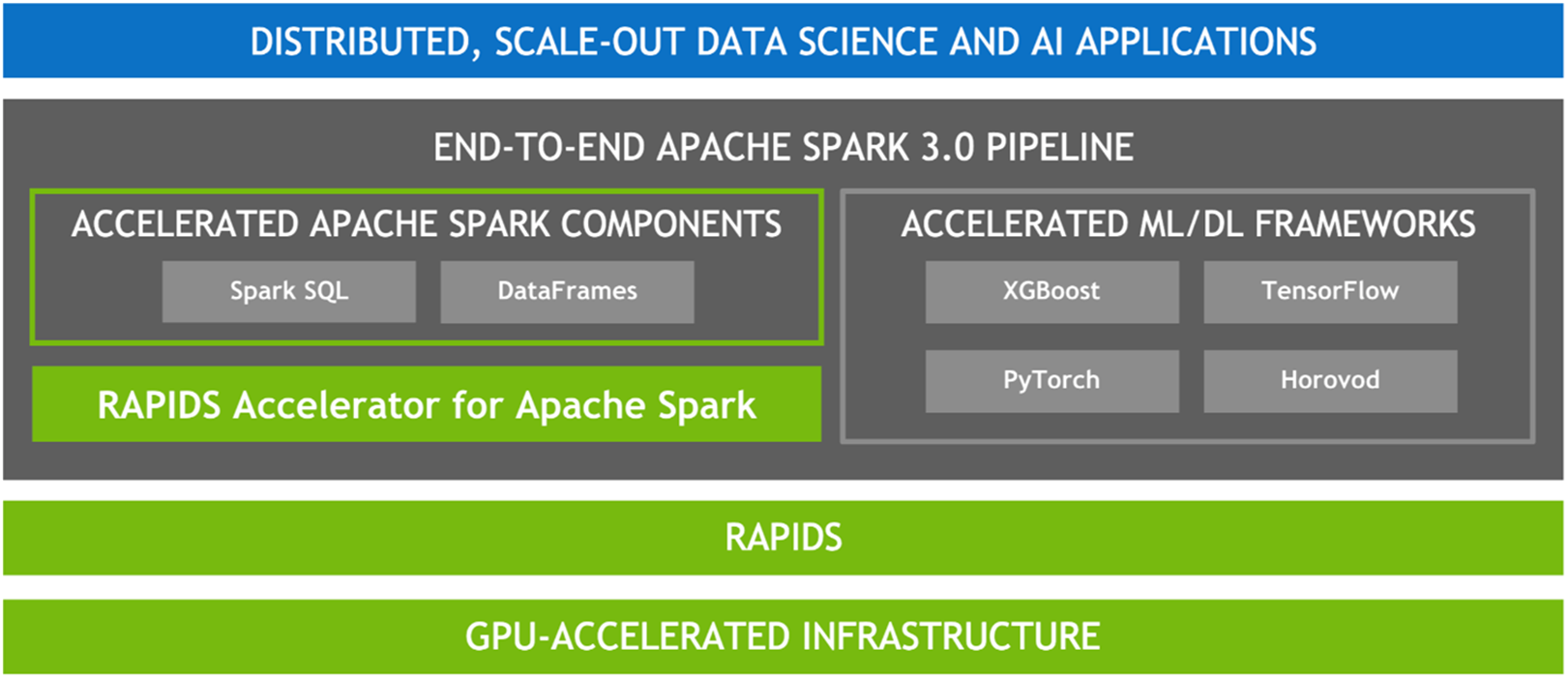
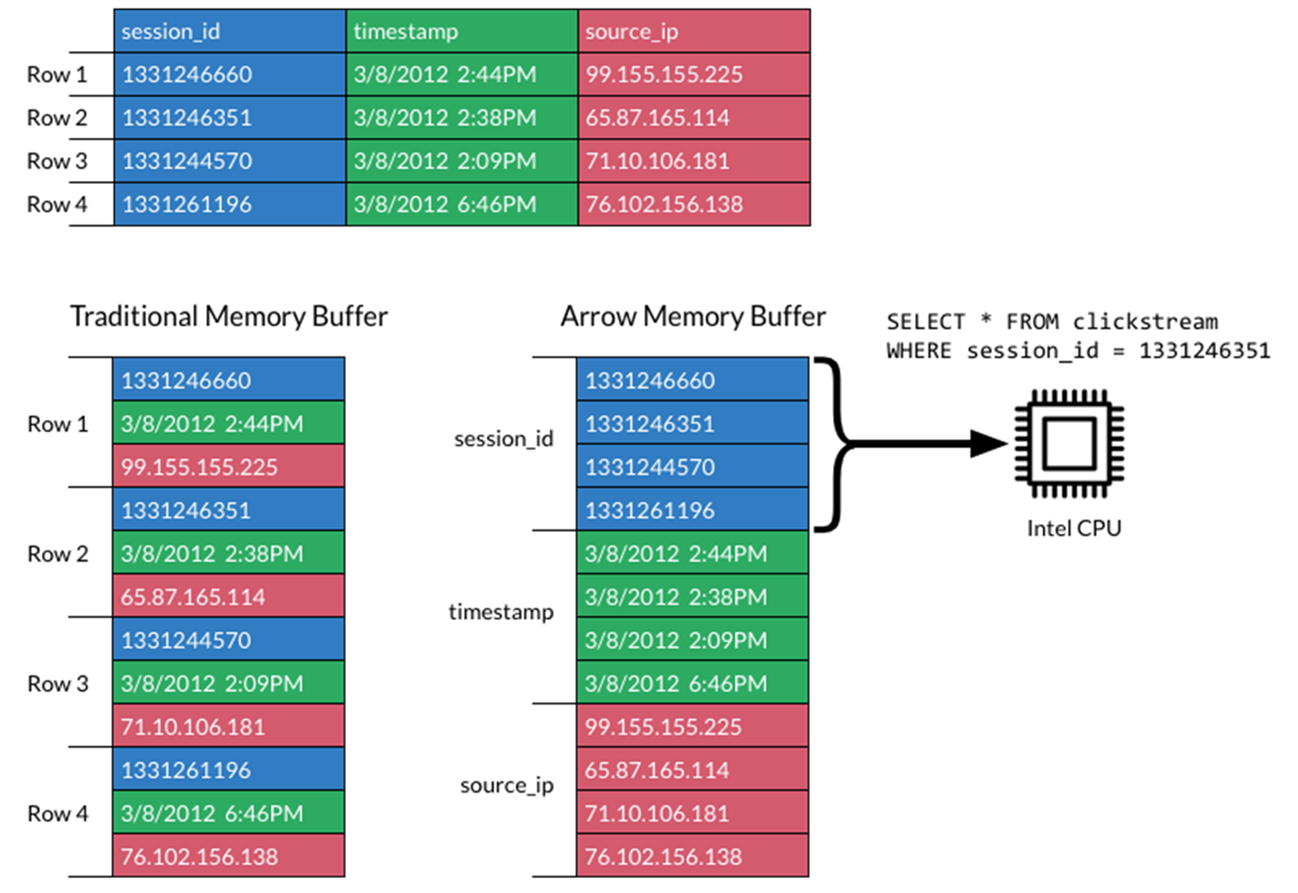
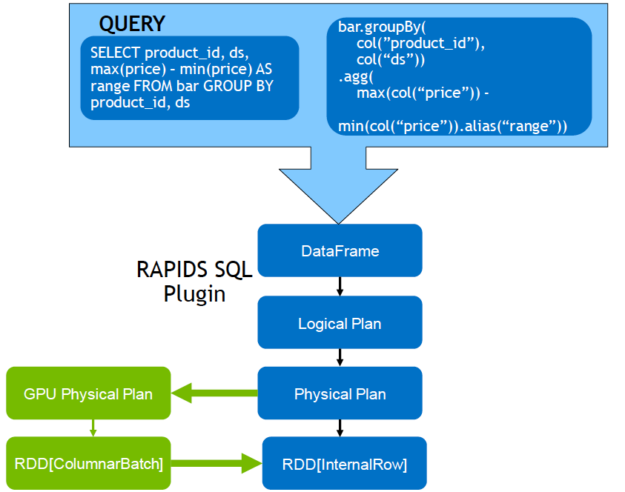
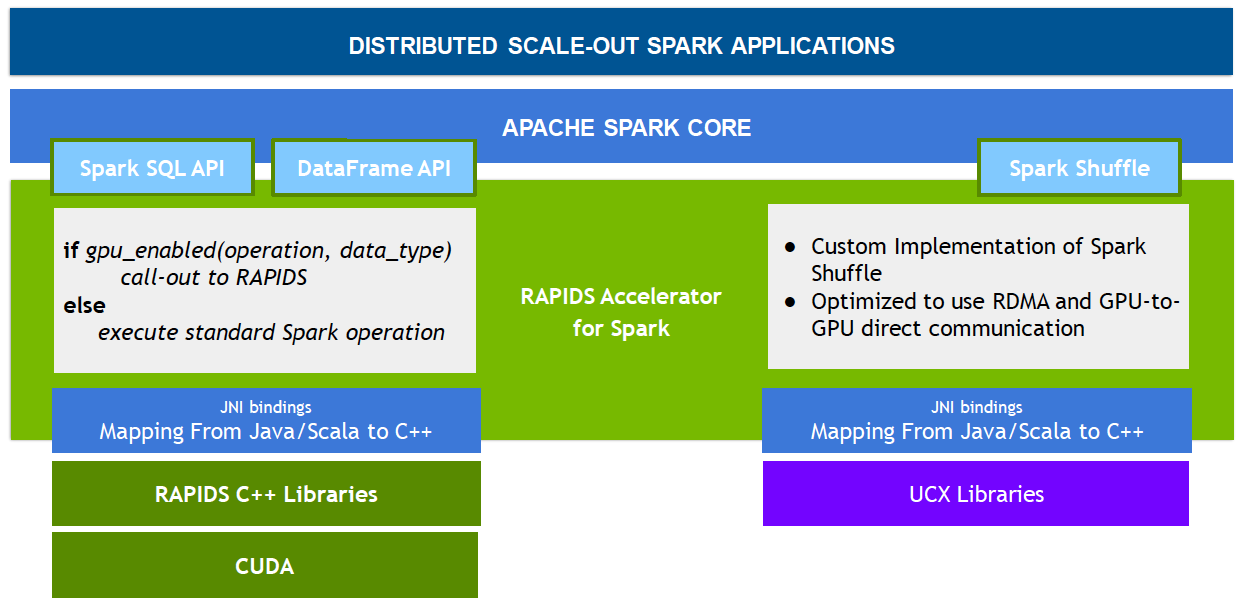
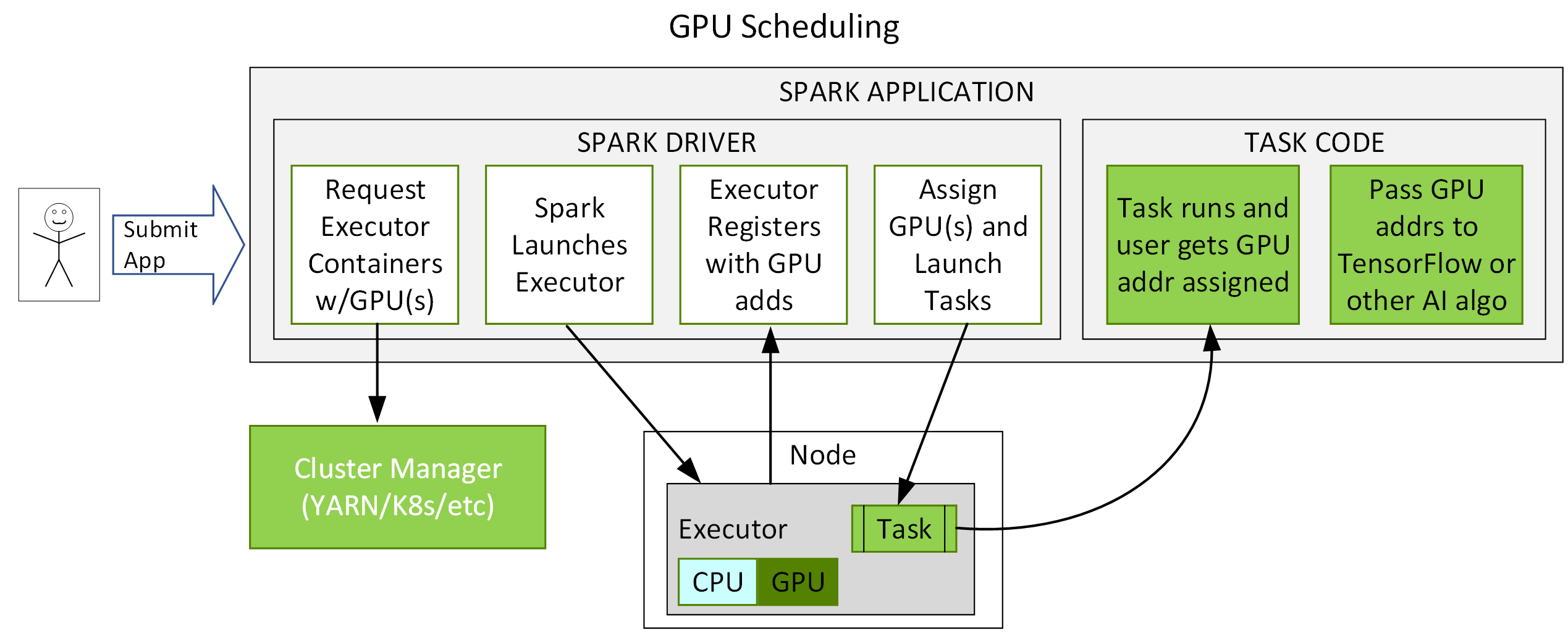
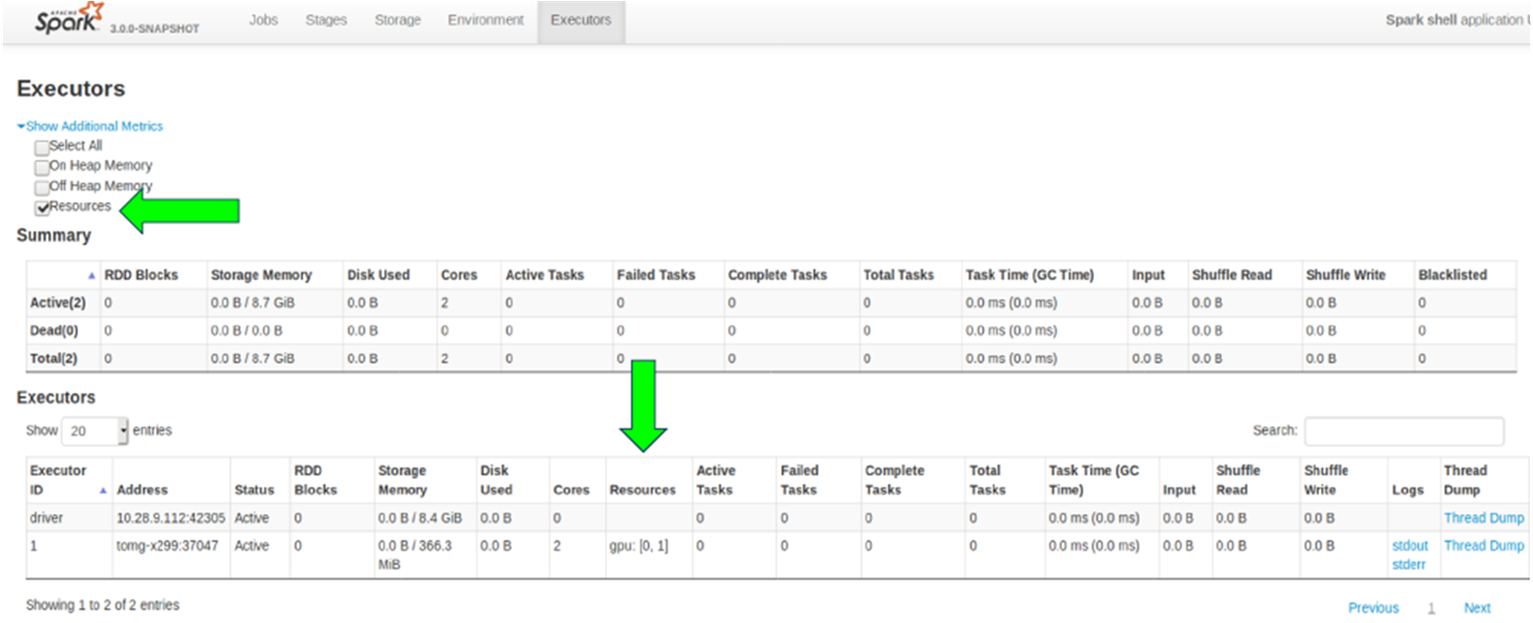
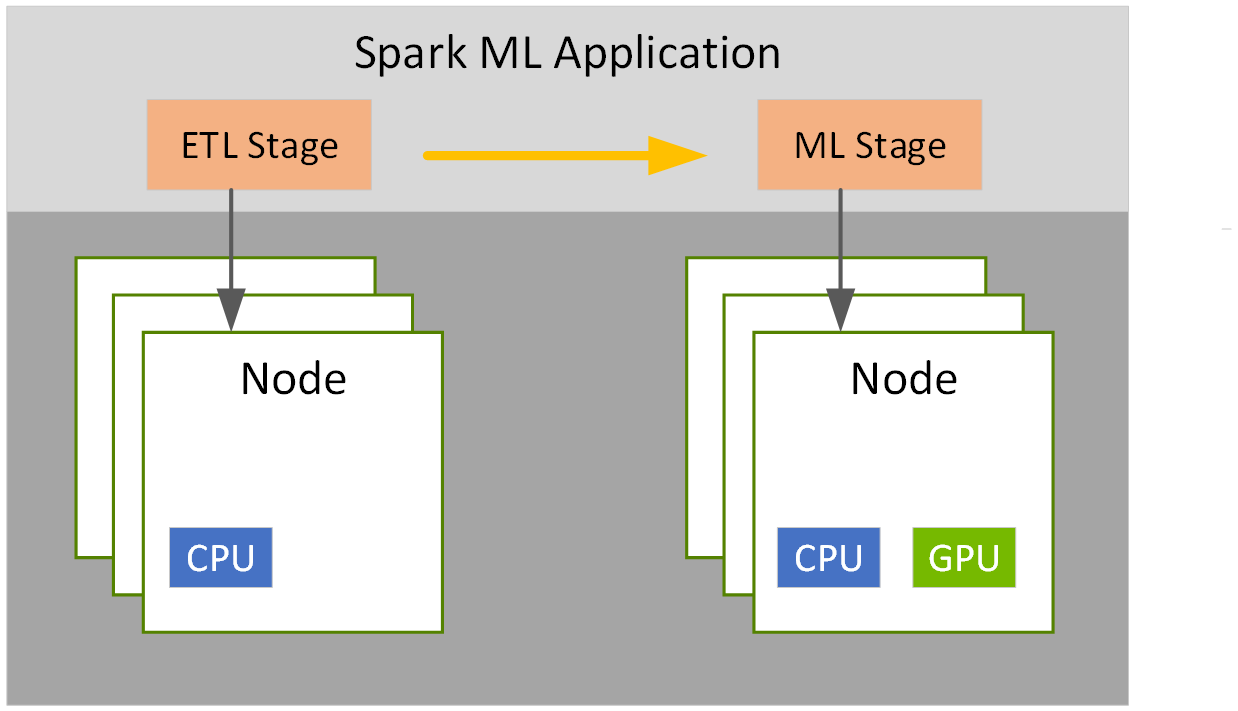
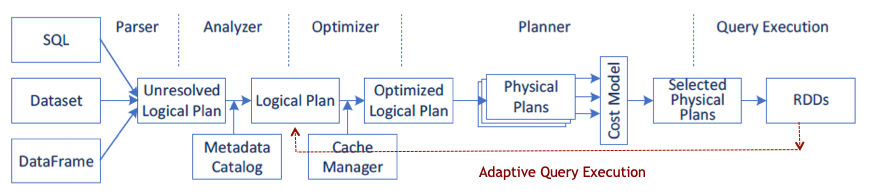
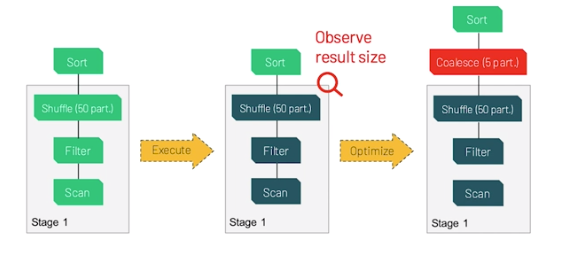
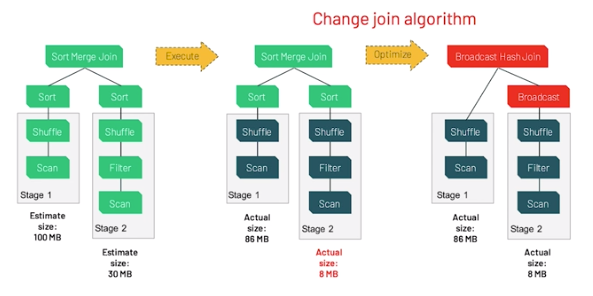
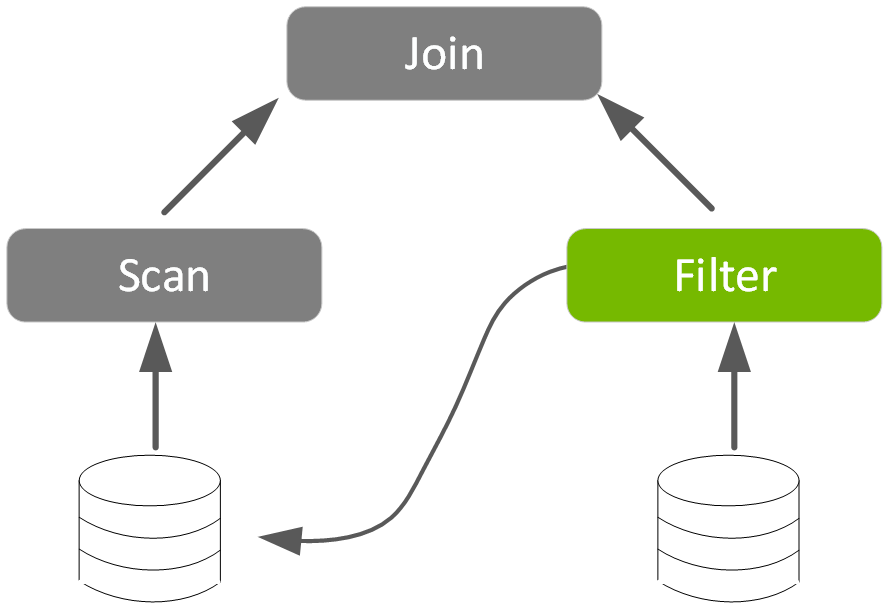
由於許多資料處理工作具備平行的特性,因此 GPU 的大規模平行架構自然能夠進行平行化並加速 Spark 資料處理查詢,就如同 GPU 加速人工智慧 (AI) 中的深度學習 (DL)。因此,NVIDIA® 與 Spark 社群攜手合作,在 Spark 3.x 中執行 GPU 加速。
雖然 Spark 以分割區的形式在節點之間分配運算,但一直以來,分割區內的運算都是在 CPU 核心上進行。然而,在 Spark 中 GPU 加速的好處不勝枚舉。首先,伺服器的需求數量減少,可降低基礎架構成本。而且,由於查詢完成速度更快,取得結果的時間亦會縮短。此外,由於 GPU 加速是透明的,專為在 Spark 上執行所打造的應用程式無需更改,就可享有 GPU 加速帶來的效益。