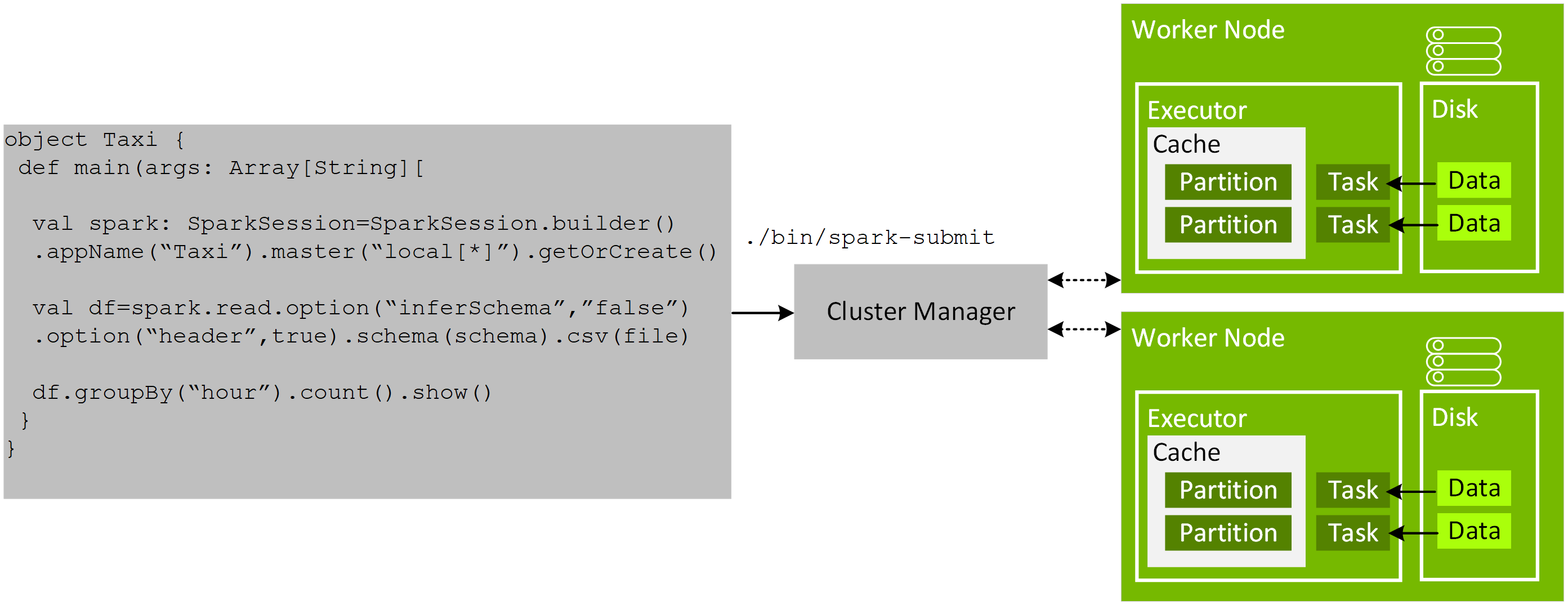
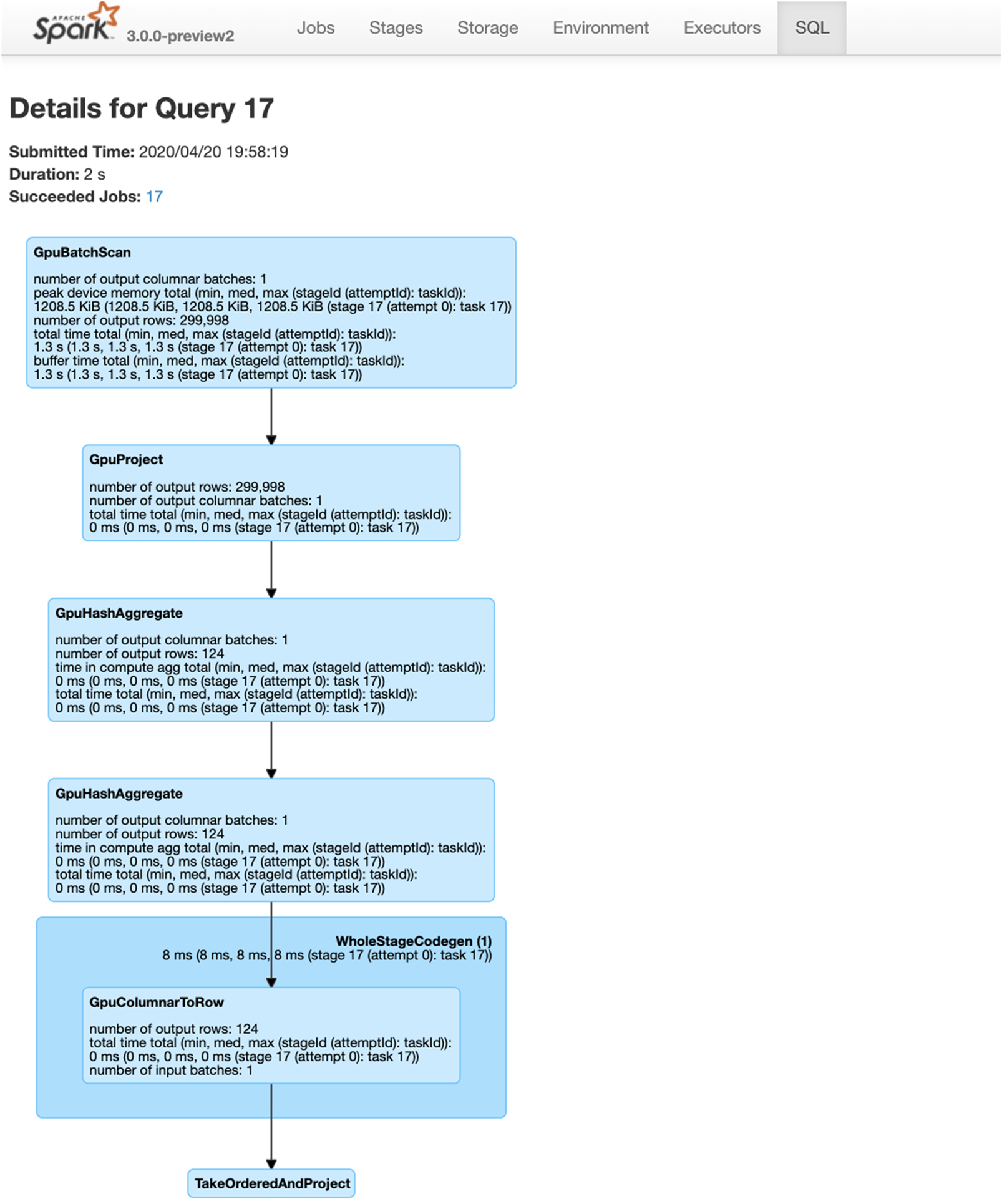
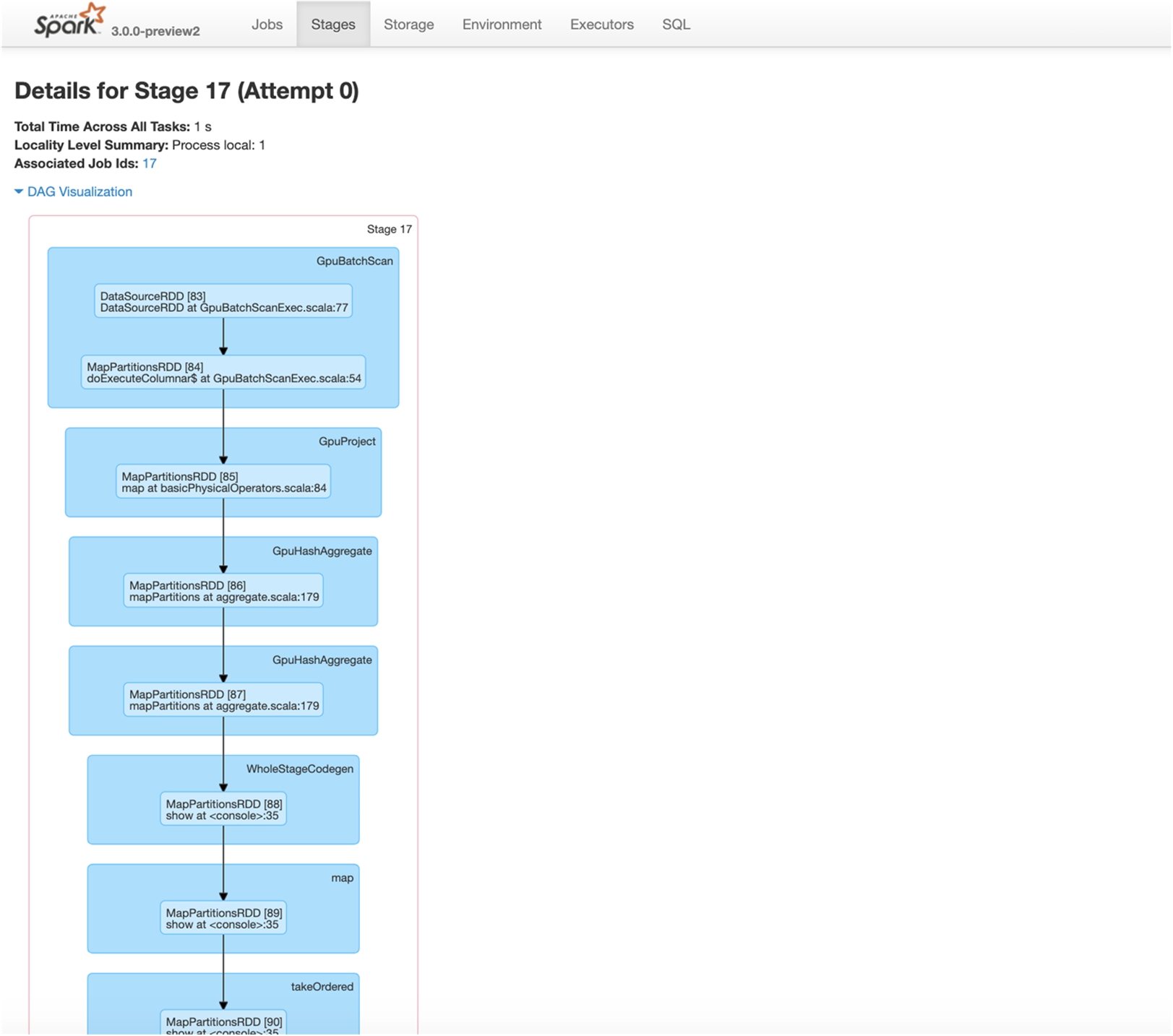
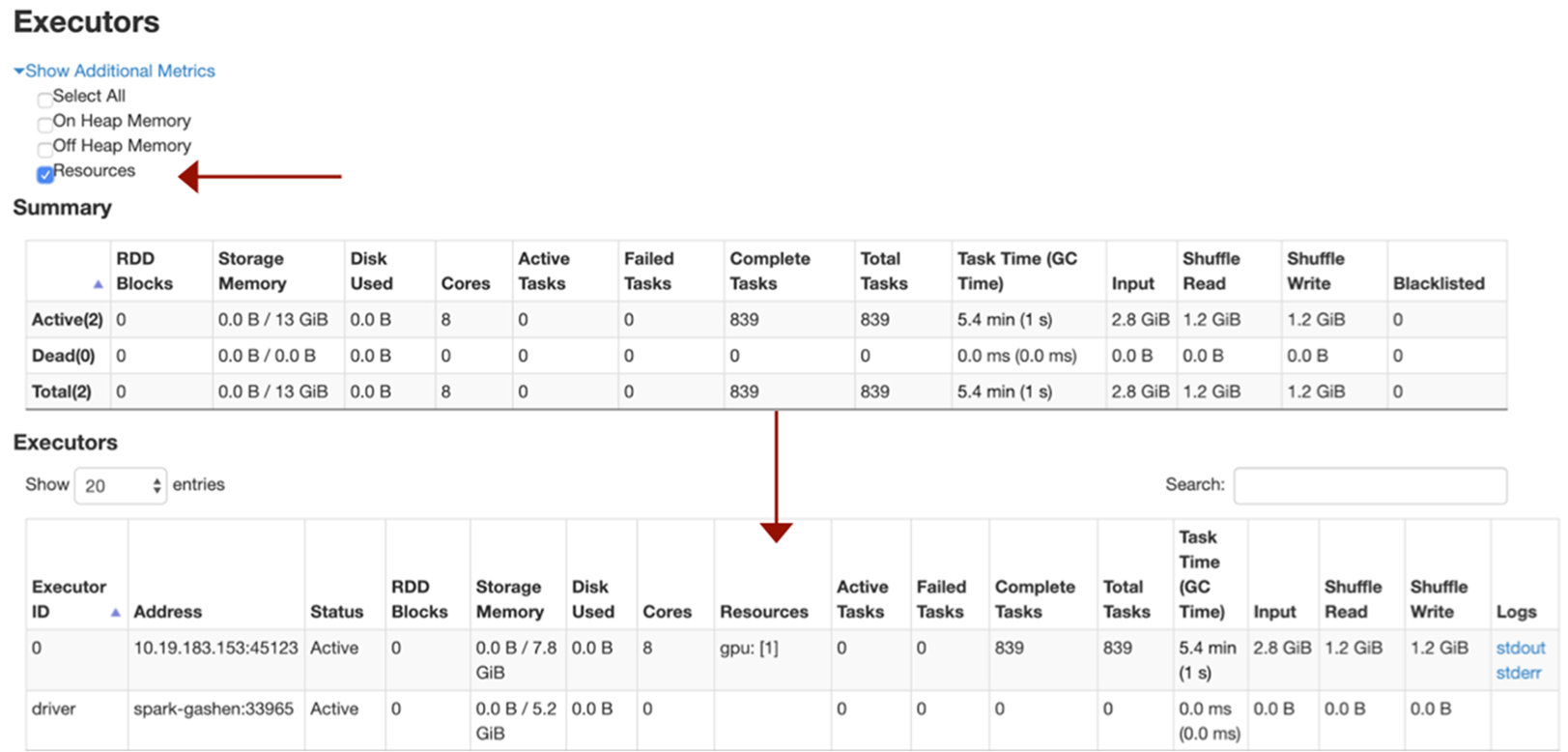
在第 3 章中,我們探討了 GPU 加速在 Spark 3.x 的功能。在本章中,我們會介紹使用適用於 Apache Spark 3.x 的全新 RAPIDS 加速器的入門基礎知識,這款加速器透過 RAPIDS 函式庫運用 GPU 加速處理 (詳情請參閱開始使用適用於 Apache Spark 的 RAPIDS 加速器)。
適用於 Apache Spark 的 RAPIDS 加速器具有以下功能和限制:
- 可以欄式處理在 GPU 上執行 Spark SQL
- 使用者無需變更 API
- 可從列式轉換為欄式,反之亦然
- 採用 Rapids cuDF 函式庫
- 可在 GPU 上執行支援的 SQL 作業,若作業未採用或與 GPU 不相容,則會切換回 Spark CPU 版本。
- 外掛程式無法加速直接操控彈性分散式資料集 (RDD) 的作業。
- 加速器函式庫亦提供 Spark 隨機置換功能實作,在盡可能保留 GPU 中資料的情況下運用 UCX 最佳化 GPU 資料傳輸,並繞過 CPU 執行 GPU 對 GPU 傳輸。
若要啟用這項 GPU 加速,需要以下項目:
- Apache Spark 3.0 或以上版本
- 以符合 RAPIDS Dataframe 函式庫 cuDF 版本要求的 GPU 所設定的 Spark 叢集。
- 每個執行程式一個 GPU。
- 請新增以下 jar:
- 與叢集上可用 CUDA 版本相符的 cudf jar。
- RAPIDS Spark 加速器外掛程式 jar。
- 將 spark.plugins 設定為 com.nvidia.spark.SQLPlugin