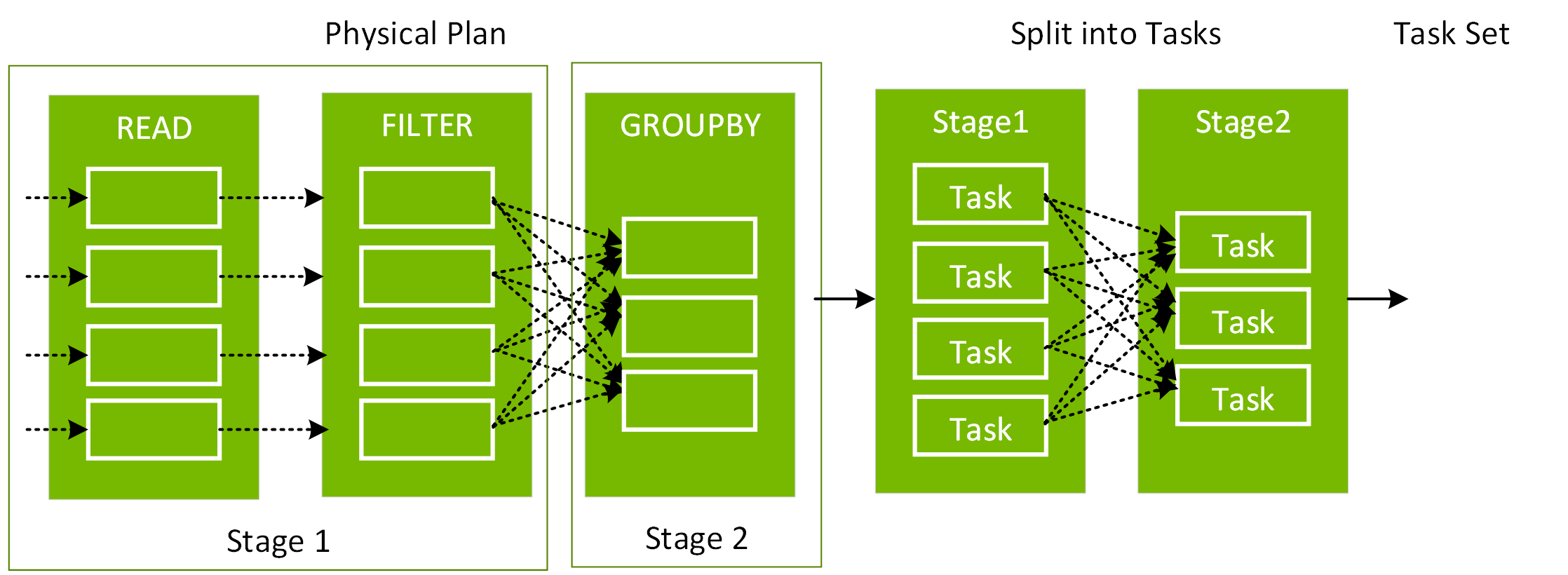
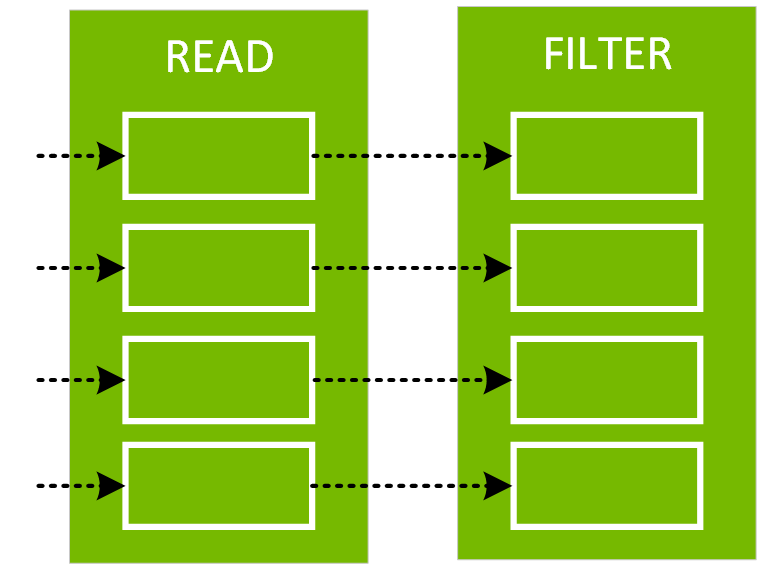
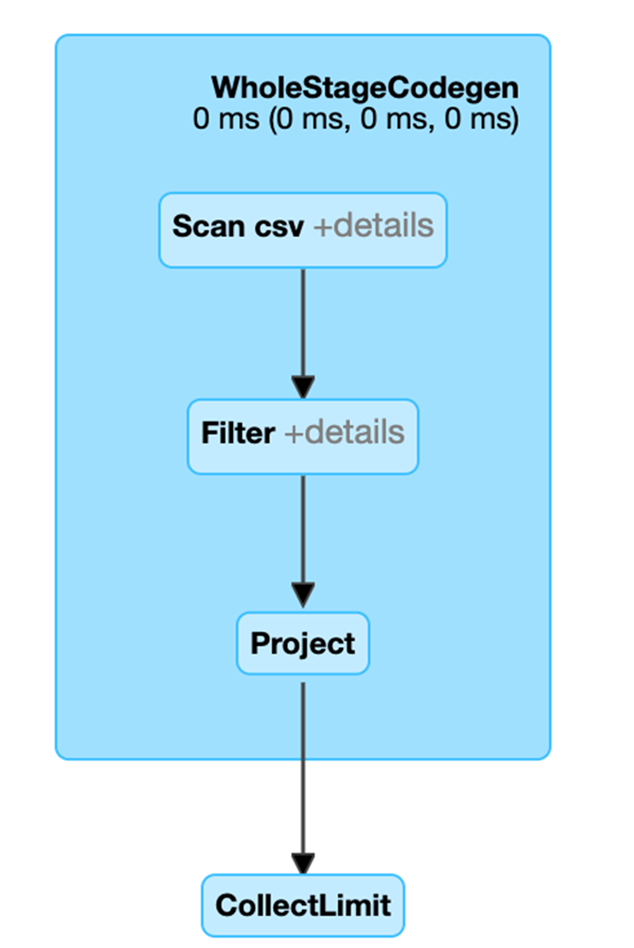
您可以呼叫 explain (「格式化」) 方法查看 DataFrame 的格式化實體計畫。在下面的實體計畫中,df2 的 DAG 包括掃描 CSV 檔、day_of_week 上的篩選條件以及 hour、fare_amount 和 day_of_week 組成的專案 (選擇欄位)。
val df =spark.read.option("inferSchema", "false") .option("header", true).schema(schema).csv(file)
val df2 =df.select($"hour", $"fare_amount", $"day_of_week").filter($"day_of_week" === "6.0" )
df2.show(3)
result:
+----+-----------+-----------+
|hour|fare_amount|day_of_week|
+----+-----------+-----------+
|10.0| 11.5| 6.0|
|10.0| 5.5| 6.0|
|10.0| 13.0| 6.0|
+----+-----------+-----------+
df2.explain(“formatted”)
result:
== Physical Plan ==
* Project (3)
+- * Filter (2)
+- Scan csv (1)
(1) Scan csv
Location: [dbfs:/FileStore/tables/taxi_tsmall.csv]
Output [3]: [fare_amount#143, hour#144, day_of_week#148]
PushedFilters: [IsNotNull(day_of_week), EqualTo(day_of_week,6.0)]
(2) Filter [codegen id : 1]
Input [3]: [fare_amount#143, hour#144, day_of_week#148]
Condition : (isnotnull(day_of_week#148) AND (day_of_week#148 =6.0))
(3) Project [codegen id : 1]
Output [3]: [hour#144, fare_amount#143, day_of_week#148]
Input [3]: [fare_amount#143, hour#144, day_of_week#148]
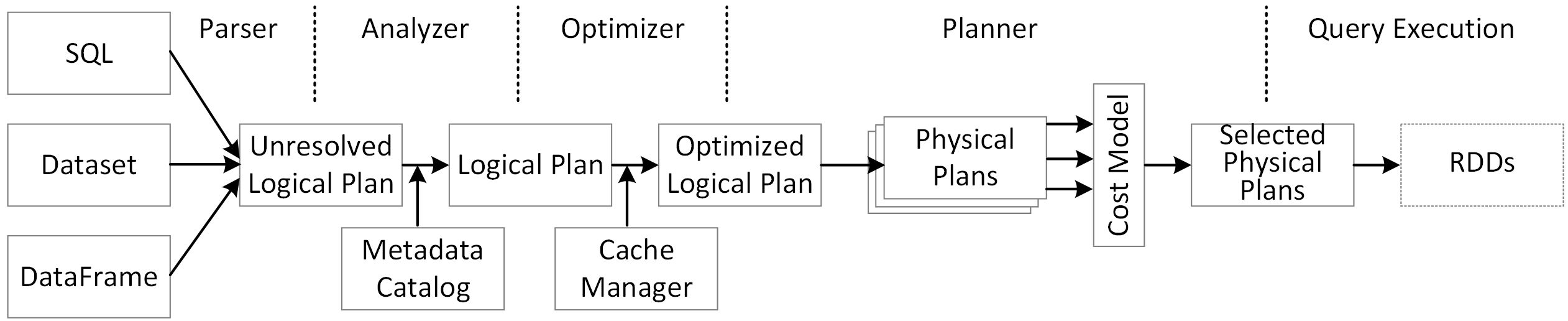
歡迎在 Web UI SQL 分頁上查看 Catalyst 產生計畫的更多詳細資訊。按一下查詢描述連結以查看 DAG 和查詢的詳細資訊。
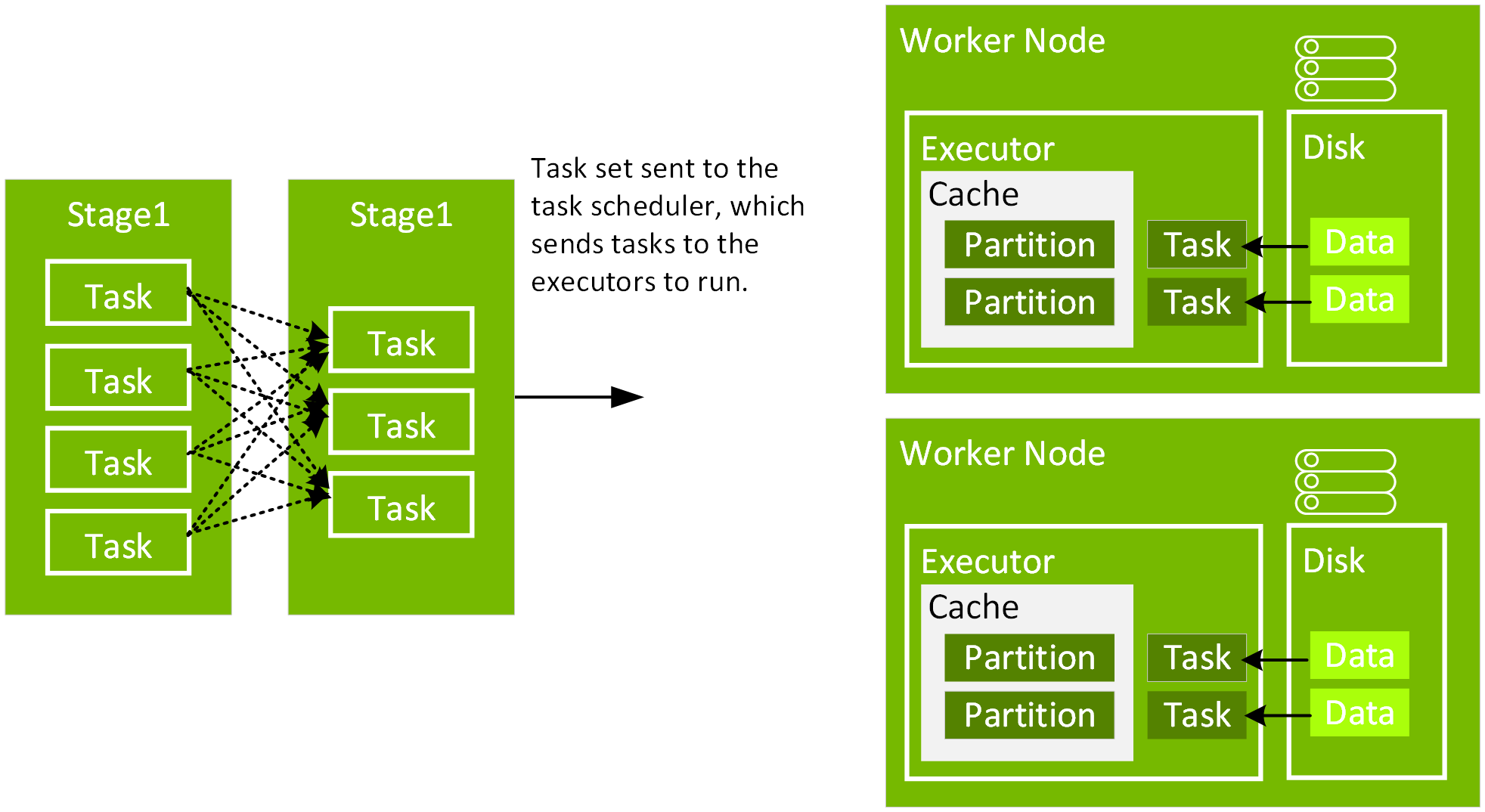
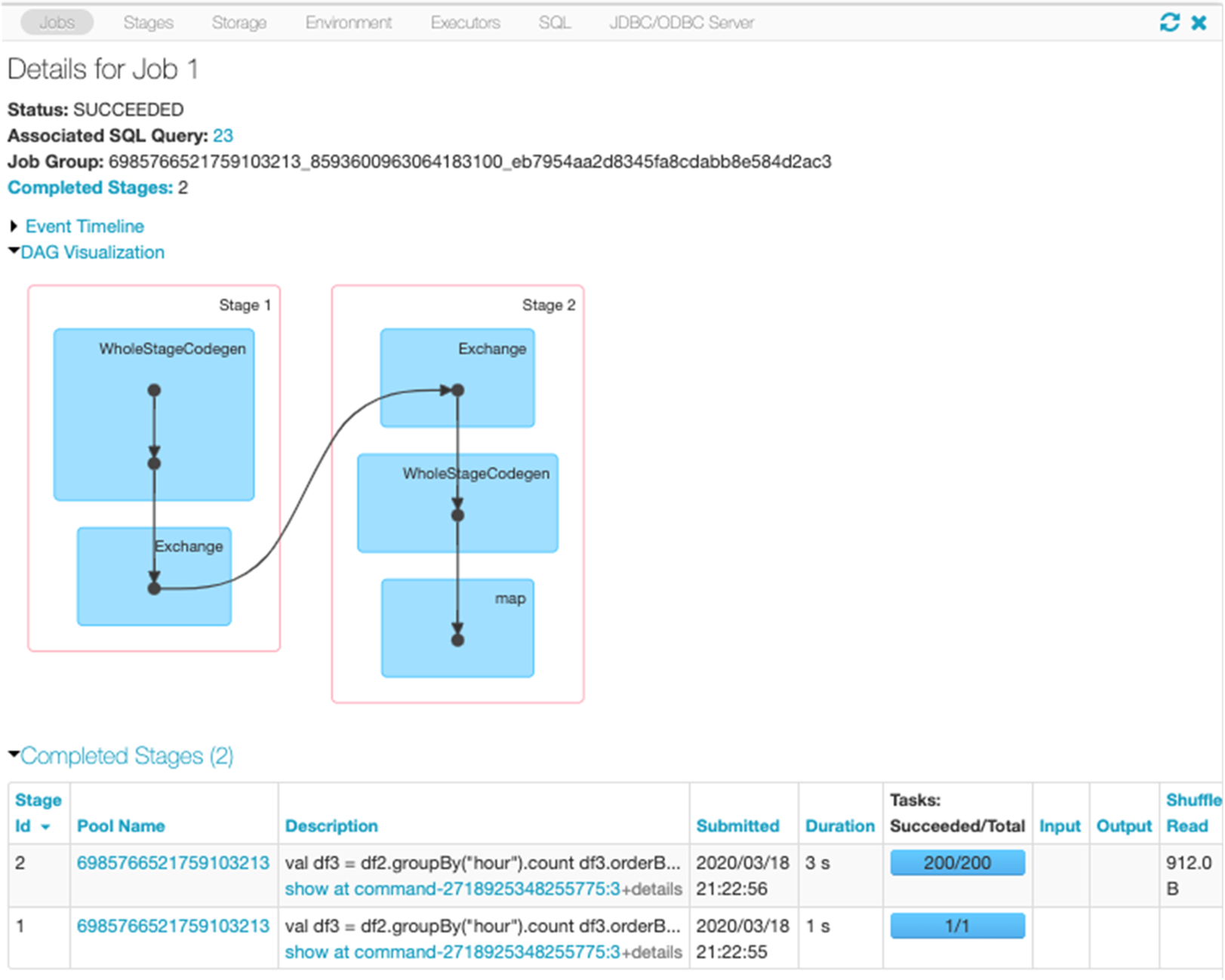
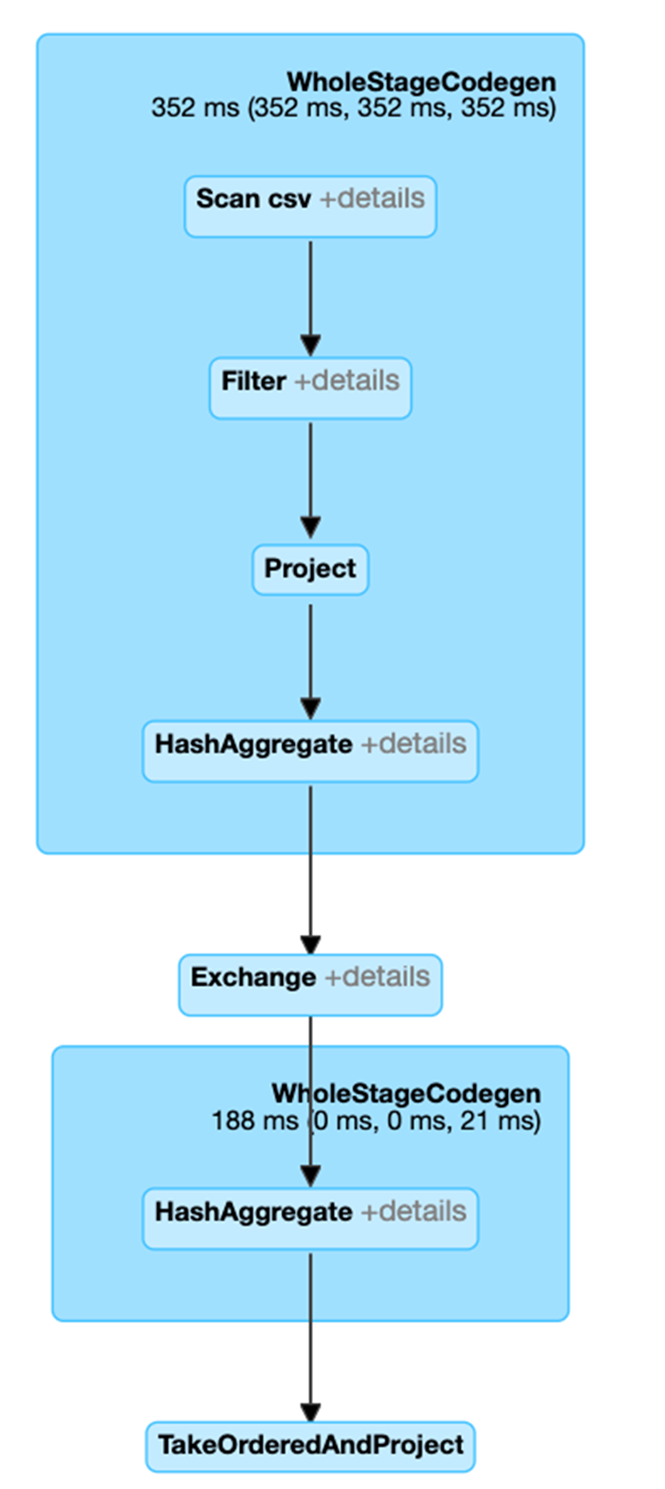
經過解釋後,我們可以從以下的程式碼中瞭解到,df3 的實體計畫包括掃描、篩選條件、專案、雜湊彙總 (HashAggregate)、Exchange 和雜湊彙總。交換是指以 groupBy 轉換進行隨機置換。在隨機置換 Exchange 中的資料前,Spark 會對每個分割執行雜湊彙總。經過交換後,會產生前一個子彙總的雜湊彙總。請注意,如果快取 df2,則此 DAG 中會進行記憶體內掃描而非檔案掃描。
val df3 =df2.groupBy("hour").count
df3.orderBy(asc("hour"))show(5)
result:
+----+-----+
|hour|count|
+----+-----+
| 0.0| 12|
| 1.0| 47|
| 2.0| 658|
| 3.0| 742|
| 4.0| 812|
+----+-----+
df3.explain
result:
== Physical Plan ==
* HashAggregate (6)
+- Exchange (5)
+- * HashAggregate (4)
+- * Project (3)
+- * Filter (2)
+- Scan csv (1)
(1) Scan csv
Output [2]: [hour, day_of_week]
(2) Filter [codegen id : 1]
Input [2]: [hour, day_of_week]
Condition : (isnotnull(day_of_week) AND (day_of_week =6.0))
(3) Project [codegen id : 1]
Output [1]: [hour]
Input [2]: [hour, day_of_week]
(4) HashAggregate [codegen id : 1]
Input [1]: [hour]
Functions [1]: [partial_count(1) AS count]
Aggregate Attributes [1]: [count]
Results [2]: [hour, count]
(5) Exchange
Input [2]: [hour, count]
Arguments: hashpartitioning(hour, 200), true, [id=]
(6) HashAggregate [codegen id : 2]
Input [2]: [hour, count]
Keys [1]: [hour]
Functions [1]: [finalmerge_count(merge count) AS count(1)]
Aggregate Attributes [1]: [count(1)]
Results [2]: [hour, count(1) AS count]
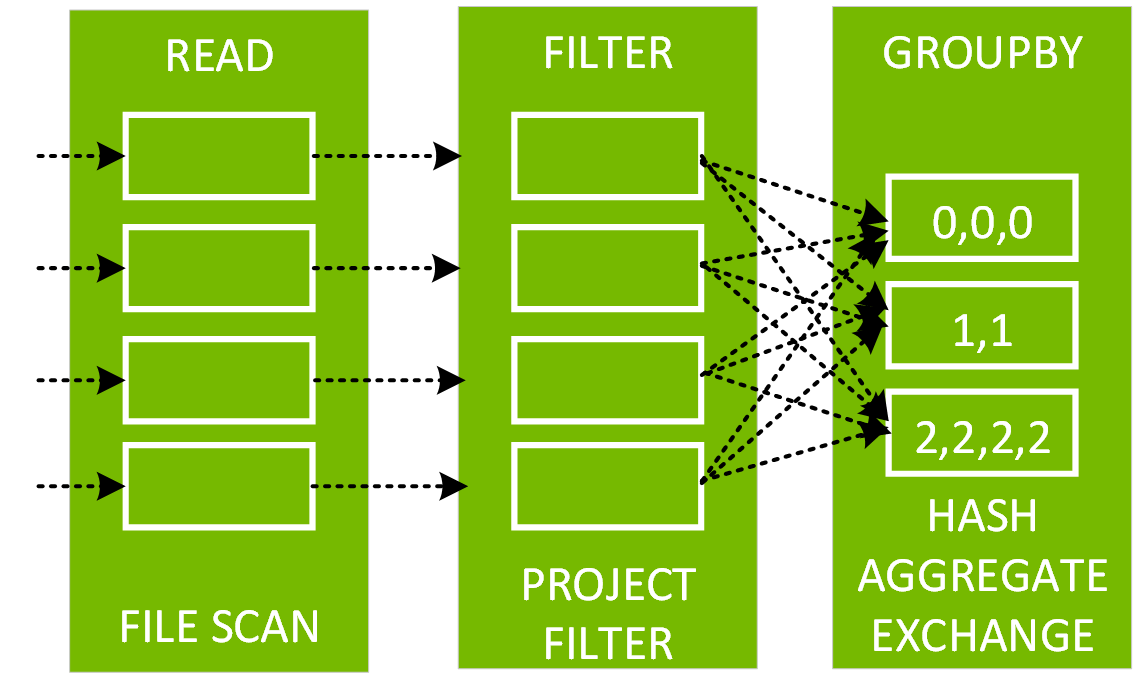
按一下此查詢的 SQL 分頁連結以顯示作業的 DAG。
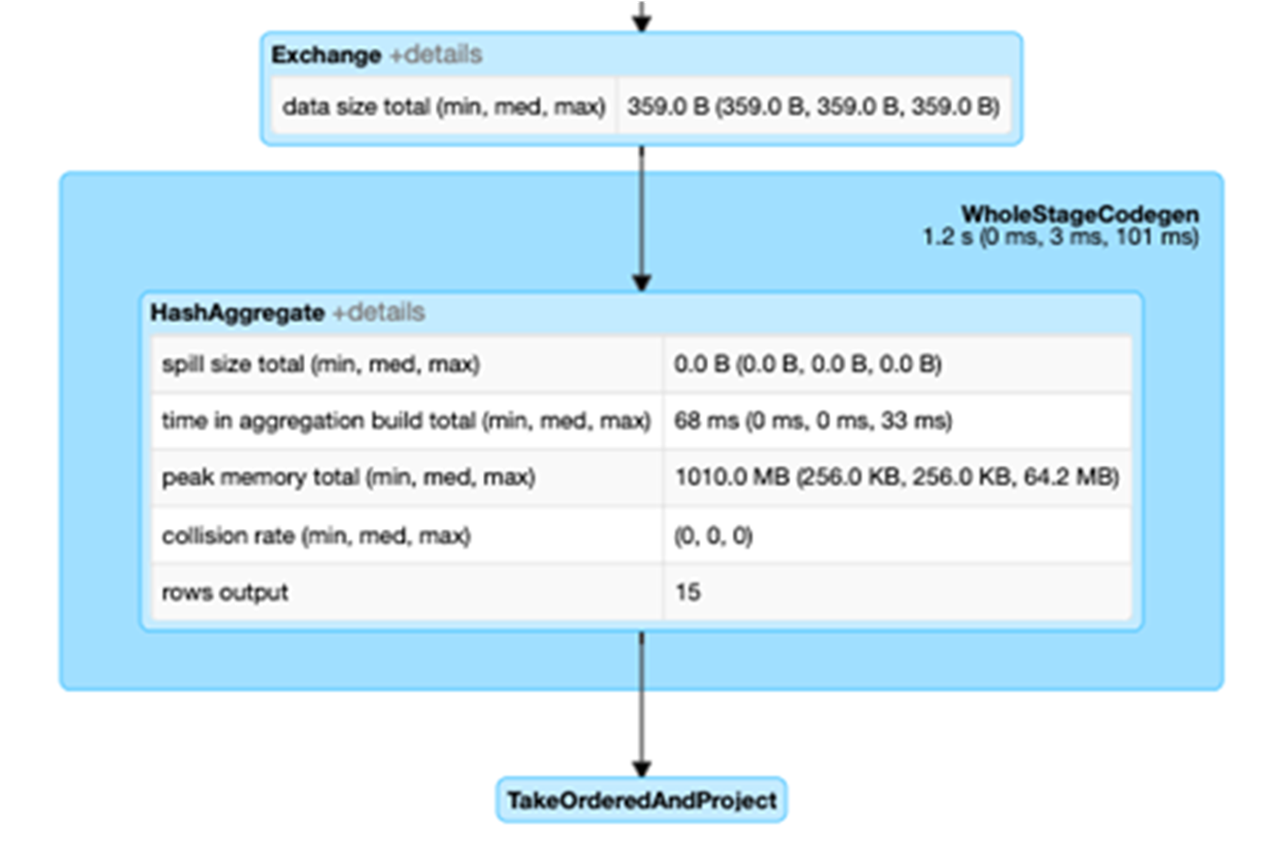
選擇「展開詳細資訊」核取方塊,顯示每個階段的詳細資訊。第一個區塊「全階段程式碼」(WholeStageCodegen) 將多個運算子 (掃描 CSV 檔、篩選條件、專案和雜湊彙總) 編譯成一個單一的 Java 函數,以提高效能。下方螢幕顯示列數和溢出大小 (spill size) 等指標。
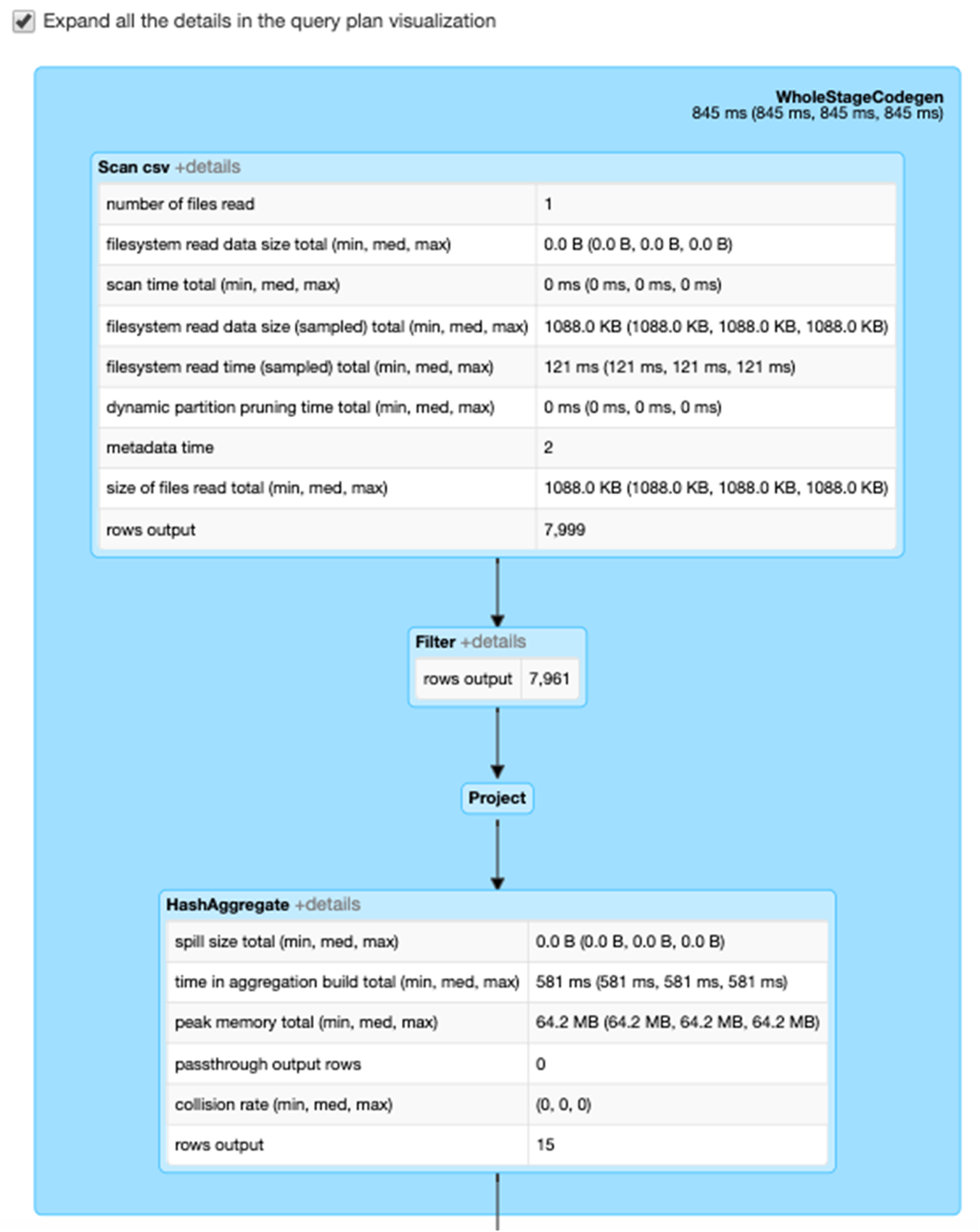
第二個區塊標題為 Exchange,顯示隨機置換的指標,包括寫入換的隨機置記錄數量和總資料大小。