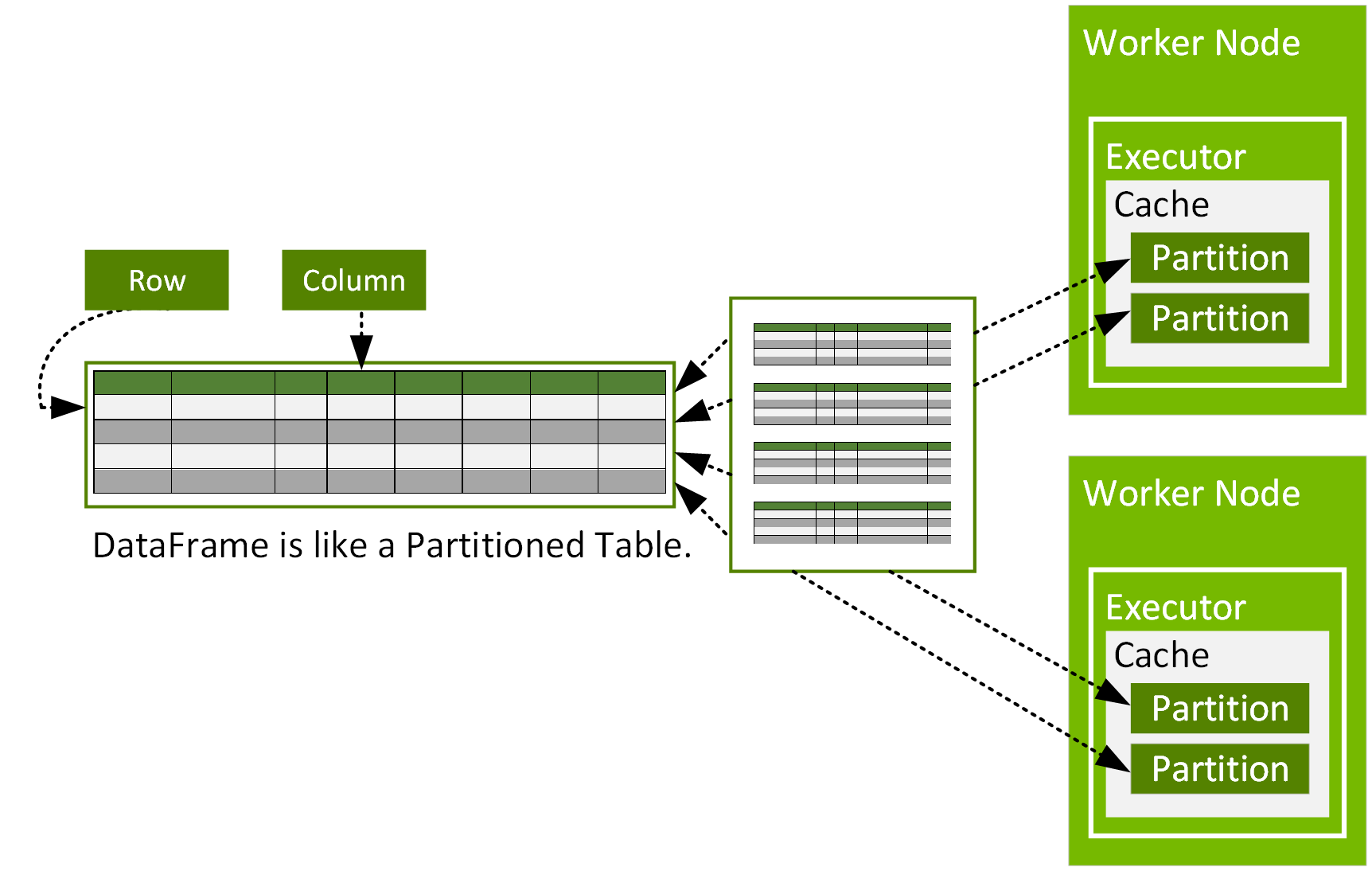
Spark DataFrame 是 org.apache.spark.sql.Row 物件的分散式資料集,這些物件分隔在叢集的多個節點中,可以平行方式操作。DataFrame 以包含列與欄的資料表顯示,與 R 或 Python 的 DataFrame 相似,不過 DataFrame 具備 Spark 最佳化功能。DataFrame 由分割區組成,每個分割區在資料節點快取中皆以一系列的列來表示。
DataFrame 可根據資料來源建立,例如 csv、parquet、JSON 檔案、Hive 表格或外部資料庫。只要透過關聯式轉換及 Spark SQL 查詢,即可在 DataFrame 上操作。
Spark 殼層或 Spark 筆記本提供了輕鬆與 Spark 互動的方式。 使用以下指令即可在本機模式中啟動殼層:
$ /[installation path]/bin/spark-shell --master local[2]
接著只要將本章中其他程式碼輸入殼層,即可以互動方式查看結果。 在程式碼範例中,殼層的輸出便以結果作為開頭。
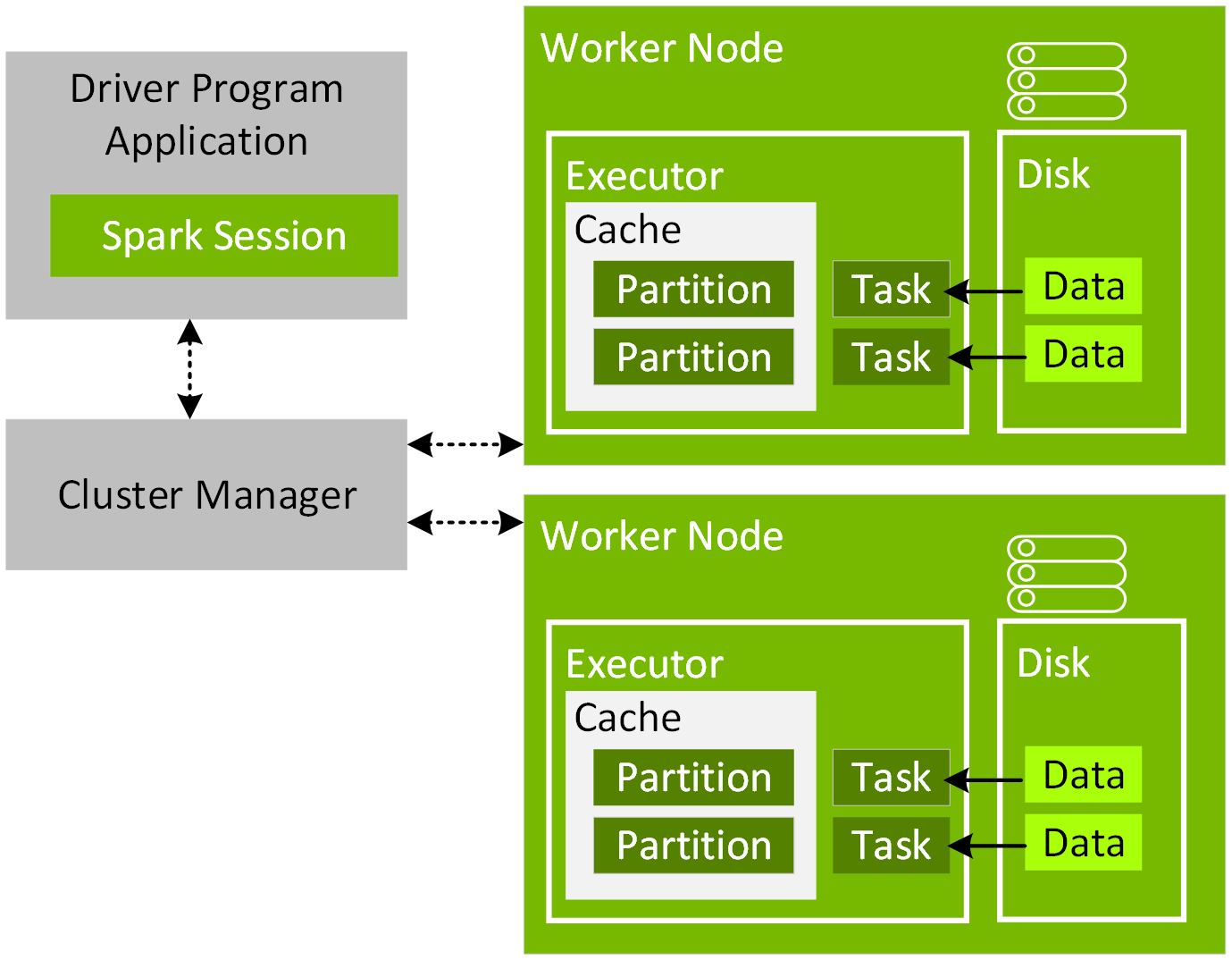
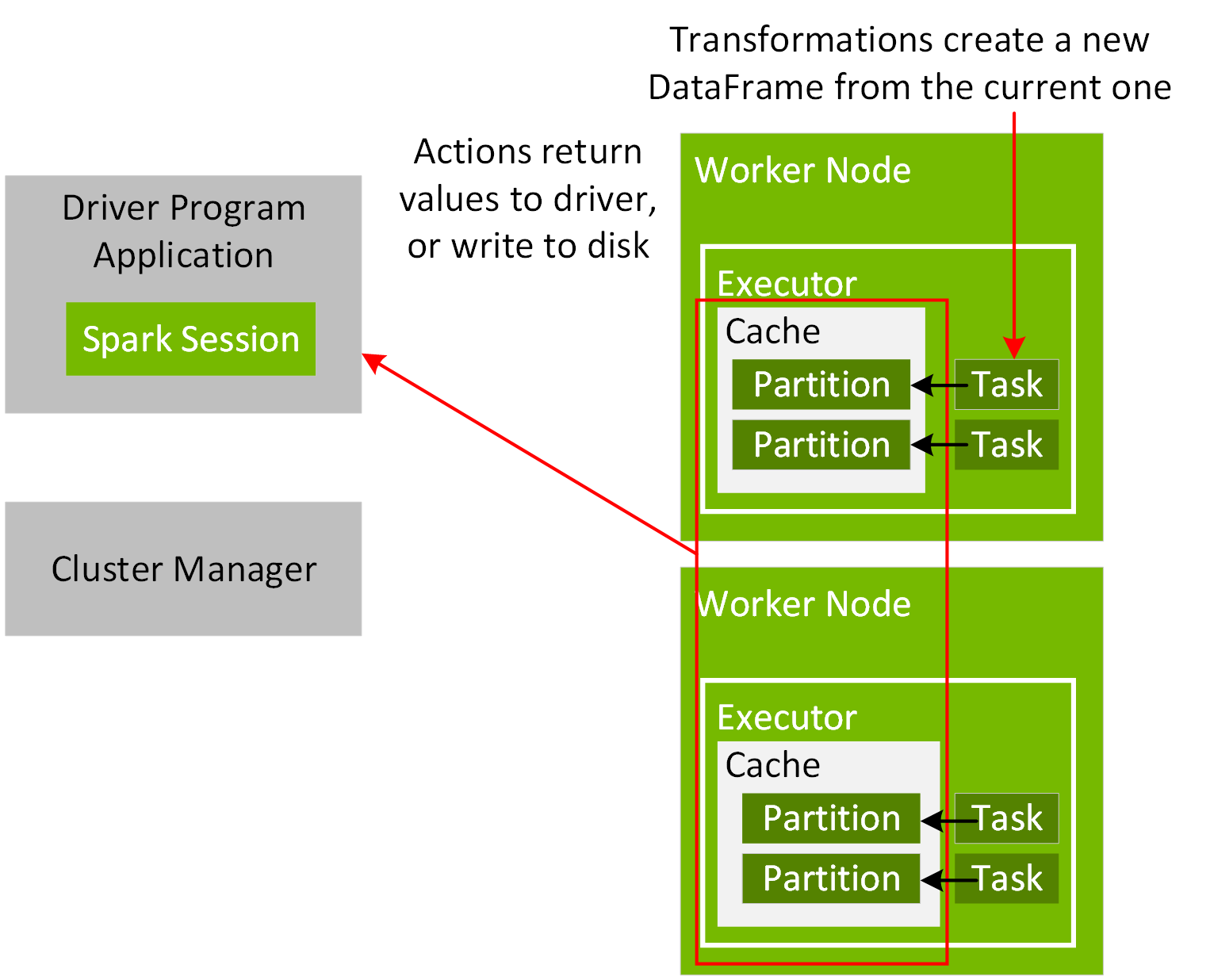
為了協調應用驅動程式和叢集管理員之間的執行過程,請在程式中建立一個 SparkSession 物件,如下方程式碼範例所示:
val spark =SparkSession.builder.appName("Simple Application").master("local[2]").getOrCreate()
Spark 應用程式啟動後,便會透過主要 URL 連接叢集管理員。主要 URL 可設定為叢集管理員或本機 [N],以便於建立 SparkSession 物件或於提交 Spark 應用程式時以 N 執行緒於本機執行。使用 Spark 殼層或筆記本時,SparkSession 物件已建立且可作為變數 Spark 使用。只要連接上,叢集管理員便會根據叢集中的節點配置分配資源並啟動執行程式流程。執行 Spark 應用程式時,SparkSession 會將工作發送至執行程式來運作。
透過 SparkSession Read 方法,即可將檔案資料讀取為 DataFrame,同時指定檔案類型、檔案路徑以及用於架構的輸入選項。
import org.apache.spark.sql.types._
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
val schema =
StructType(Array(
StructField("vendor_id", DoubleType),
StructField("passenger_count", DoubleType),
StructField("trip_distance", DoubleType),
StructField("pickup_longitude", DoubleType),
StructField("pickup_latitude", DoubleType),
StructField("rate_code", DoubleType),
StructField("store_and_fwd", DoubleType),
StructField("dropoff_longitude", DoubleType),
StructField("dropoff_latitude", DoubleType),
StructField("fare_amount", DoubleType),
StructField("hour", DoubleType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", DoubleType),
StructField("day_of_week", DoubleType),
StructField("is_weekend", DoubleType)
))
val file ="/data/taxi_small.csv"
val df =spark.read.option("inferSchema", "false")
.option("header", true).schema(schema).csv(file)
result:
df: org.apache.spark.sql.DataFrame =[vendor_id: double, passenger_count:
double ... 14 more fields]
Take 方法會傳回此 DataFrame 中的物件陣列,這些物件屬於 org.apache.spark.sql.Row 類型。
df.take(1)
result:
Array[org.apache.spark.sql.Row] =
Array([4.52563162E8,5.0,2.72,-73.948132,40.829826999999995,-6.77418915E8,-1.0,-73.969648,40.797472000000006,11.5,10.0,2012,11,13.0,6.0,1.0])