NVIDIA NeMo
Eine agentenorientierte, offene Bibliothekensuite zur Beschleunigung der Spezialisierung, Optimierung und Steuerung von KI-Agenten.
Überblick
Was ist NVIDIA NeMo?
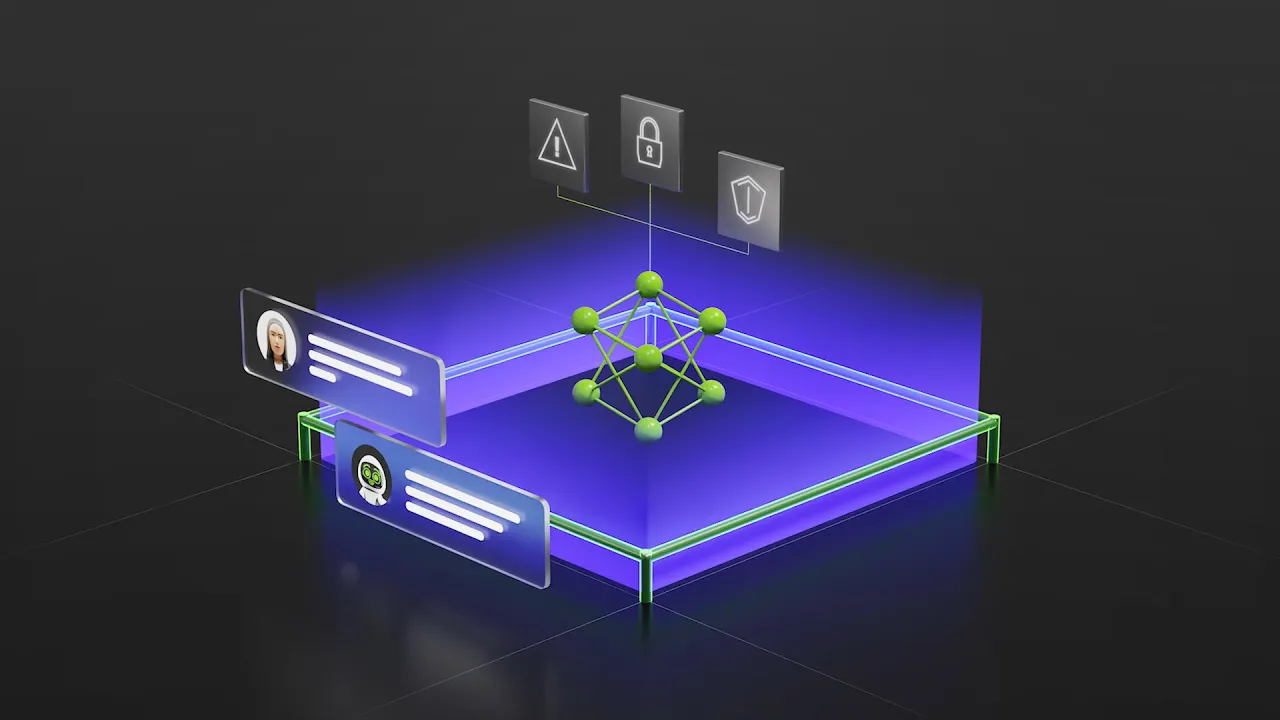
NVIDIA NeMo™ ist eine agentenorientierte, offene Bibliothekensuite mit Fähigkeiten zur Beschleunigung der Spezialisierung, Optimierung und Regulierung von KI-Agenten.
NeMo lässt sich in bestehende KI-Tools und Agenten-Frameworks integrieren, um spezialisierte Agenten in jeder Cloud, lokalen oder hybriden Umgebung zu optimieren.
Merkmale
Tools und Fähigkeiten für die Beschleunigung der Optimierung spezialisierter KI-Agenten
Der Lebenszyklus von KI-Agenten ist ein End-to-End-Prozess für die Entwicklung und kontinuierliche Verbesserung von KI-Agenten in Produktionsanwendungen. NeMo lässt sich in bestehende KI-Tools und Agenten-Frameworks integrieren, um spezialisierte Agenten während ihres gesamten Lebenszyklus zu optimieren.

| Entwickeln | |
|---|---|
| Bereiten Sie KI-fähige Daten vor Verarbeiten Sie bestehende multimodale Datensätze in hochwertige, KI-fähige Formate für Entwicklungspipelines und generieren Sie synthetische Daten, um kritische Datenlücken zu schließen. |
|
| Wählen Sie das richtige Modell oder erstellen Sie Modelle, die für den Anwendungsfall geeignet sind: aus Nemotron™ oder anderen offenen Modellen, anderen offenen oder proprietären Optionen oder trainieren Sie von Grund auf neu. Validieren Sie mit Evaluierungsläufen und optimieren Sie bei Bedarf. |
|
| Bereitstellen | |
| Stellen Sie Ihren Agenten mit maximaler Leistung bereit Optimieren Sie Ihren Agenten für die Produktion mit Inferenz mit hohem Durchsatz und geringer Latenz, um sicherzustellen, dass er skaliert werden kann, um den Anforderungen von Unternehmen gerecht zu werden und schnelle, zuverlässige Antworten zu liefern. |
|
| Bleiben Sie datengestützt und setzen Sie Guardrails ein. Nutzen Sie Retrieval-Augmented Generation (RAG), um die Antworten von Agenten in vertrauenswürdigem Wissen zu verankern und gleichzeitig Sicherheits-, Compliance- und Inhaltsmoderations-Guardrails anzuwenden. |
|
| Validieren Sie die Sicherheit von Agenten und Modellen vor der Einführung Identifizieren und beheben Sie Sicherheitslücken in Modellen und Agenten, bevor sie in die Produktion gehen. |
|
| Optimieren | |
| Profilieren und optimieren Sie Ihre Agenten. Verfolgen Sie die realen Interaktionen des Agenten mit Benutzern und anderen Systemen. Bewerten Sie systematisch die Leistung und Genauigkeit und finden Sie Möglichkeiten zur kontinuierlichen Verbesserung. |
|
| Nutzen Sie das Feedback und die Daten die aus der Überwachung gewonnen wurden, um ein datengestütztes Flywheel zu erstellen und den Agenten iterativ neu zu trainieren, um kontinuierlich zu optimieren und im Laufe der Zeit effektiv zu bleiben. |
|
Anwendungsfälle
Wie NeMo zum Einsatz kommt
Erfahren Sie, wie NVIDIA NeMo Anwendungsfälle der Branche unterstützt und Ihre KI-Entwicklung beschleunigt.
-
KI-Agenten
-
SDG für agentische KI
-
KI-Assistent
-
Informationsabruf
-
Generierung von Inhalten
-
Der humanoide Roboter
KI-Agenten
KI-Agenten verändern den Kundenservice in allen Branchen und helfen Unternehmen dabei, Kundengespräche zu verbessern, hohe Lösungsraten zu erzielen und die Produktivität der „humanen“ Mitarbeitenden zu steigern. KI-Agenten können prädiktive Aufgaben übernehmen, logische Schlussfolgerungen ziehen und Probleme lösen, sie können geschult werden, um branchenspezifische Begriffe zu verstehen, und sie können relevante Informationen aus den Wissensdatenbanken eines Unternehmens abrufen – unabhängig davon, wo sich diese Daten befinden.

Generierung synthetischer Daten für agentische KI
Spezialisierte agentenbasierte Systeme benötigen riesige, hochwertige Datensätze, deren Sammlung aus realen Quellen langsam und kostspielig ist. Synthetische Daten, die durch Simulationen oder generative KI-Modelle erstellt werden, können diesen Engpass beseitigen, indem sie unbegrenzte Trainingsszenarien ohne Datenschutzbeschränkungen oder Qualitätsprobleme erstellen. Dies ermöglicht eine schnellere Entwicklung von logischen LLMs, mehrstufigen Entscheidungsträgern und multimodalen KI-Assistenten.

KI-Assistent
Unternehmen setzen KI-Assistenten ein, um die Fragen von Millionen von Kunden und Mitarbeitern rund um die Uhr effizient zu beantworten. Mit kundenspezifischen NVIDIA NIM-Microservices für LLMs, RAG sowie Sprach- und Übersetzungs-KI liefern diese KI-Assistenten sofortige und präzise gesprochene Antworten, auch bei Hintergrundgeräuschen, schlechter Tonqualität oder verschiedenen Dialekten und Akzenten.

Unternehmenssuche
Unternehmen generieren jährlich Billionen von Dokumenten – darunter PDFs, Berichte und Präsentationen – die jeweils Text, Bilder, Diagramme und Tabellen enthalten, die über nicht verbundene Systeme verteilt sind. Die KI-gestützte Unternehmenssuche wandelt diese verstreuten Daten in eine einheitliche Wissensdatenbank um, sodass Mitarbeiter sofort Erkenntnisse mithilfe natürlicher Sprache abrufen und schnellere Entscheidungen zu geringeren Kosten treffen können.

Generierung von Inhalten
Generative KI ermöglicht die Generierung von hochrelevanten, maßgeschneiderten und präzisen Inhalten, die auf der Bereichskompetenz und dem proprietären geistigen Eigentum Ihres Unternehmens basieren.

Der humanoide Roboter
Humanoide Roboter sind so gebaut, dass sie sich schnell an bestehende, auf den Menschen ausgerichtete städtische und industrielle Arbeitsbereiche anpassen und mühsame, sich wiederholende oder körperlich anstrengende Aufgaben übernehmen können. Ihre Vielseitigkeit hat sie an so unterschiedlichen Orten eingesetzt, von Fabrikgebäuden bis hin zu Gesundheitseinrichtungen, wo diese Roboter Menschen unterstützen und den Arbeitskräftemangel durch Automatisierung lindern.

Apptronik
Vorteile
Entdecken Sie die Vorteile von NVIDIA NeMo für agentische KI-Systeme

Agenten-orientierte Entwicklung mit Skills
Verwalten Sie den gesamten Agenten-Lebenszyklus von der Datenkuration und dem Nachtrainieren bis hin zu Evaluierung, Guardrails, Beobachtbarkeit und kontinuierlicher Optimierung mit einer agentenfreundlichen Suite von Agenten-Fähigkeiten.

Skalierbares Wachstum beschleunigen
Stellen Sie Daten-Flywheels mithilfe von Unternehmensdaten bereit, mit GPU-beschleunigtem Training, Inferenz, Multi-Knoten-Skalierung und kosteneffizienter Optimierung für Agenten-Workloads mit hohem Durchsatz.

Höherer ROI
Spezialisierte agentenbasierte Systeme schneller entwickeln, anpassen und bereitstellen – dies verkürzt die Produktionszeit und maximiert die Rendite von KI-Investitionen.

Sicher und produktionsbereit
Schützen Sie sensible Daten, setzen Sie Richtlinien und Prompt-Guardrails durch, validieren Sie Modelle und erkennen Sie kontinuierlich Schwachstellen. Profotieren Sie von einer sicheren Bereitstellung mit Unterstützung und Stabilität auf Unternehmensniveau in der Cloud, im Rechenzentrum und am Edge mit NVIDIA AI Enterprise.
Erfolgsgeschichten
Wie Branchenführer mit NeMo Innovationen vorantreiben
Anwender
Führende Anwender in allen Branchen
-
Kunden
-
Partner
Ressourcen
Die neuesten NVIDIA NeMo-Ressourcen
-
Blogs
-
Sessions
-
Schulungen
-
Videos






Nächste Schritte
Sind Sie bereit?
Nutzen Sie die richtigen Tools und Technologien, um Ihre agentischen KI-Anwendungen von der Entwicklung in die Produktion zu überführen.
Für Entwickler
Entdecken Sie alles, was Sie benötigen, um mit der Entwicklung mit NVIDIA NeMo zu beginnen, einschließlich der neuesten Dokumentation, Tutorials, technischen Blogs und mehr.
Kontaktieren Sie uns
Sprechen Sie mit einem NVIDIA-Produktexperten über den Wechsel von der Pilotphase in den Produktivbetrieb inklusive der Sicherheit, API-Stabilität und Unterstützung von NVIDIA AI Enterprise.
Shell
Shell trainiert einen benutzerdefinierten KI-Chatbot mit NVIDIA NeMo, um Betriebsabläufe zu verbessern
Shell, ein weltweit führendes Unternehmen in der Energiebranche, nutzt NVIDIA NeMo™, um die Entwicklung eines maßgeschneiderten KI-Chatbots für chemisches Fachwissen zu voranzutreiben. Diese innovative Lösung hat das Potenzial, die Mitarbeiterproduktivität erheblich zu steigern, indem sie Suchprozesse optimiert, die Entscheidungsfindung verbessert und die Forschung und Entwicklung in Produktivumgebungen unterstützt.
AI Sweden
Beschleunigen von Branchenanwendungen mit LLMs
AI Sweden hat Anwendungen für regionale Sprachmodelle erleichtert, indem es einfachen Zugriff auf ein leistungsstarkes Modell mit 100 Milliarden Parametern gewährt. Dazu digitalisierte das Unternehmen historische Aufzeichnungen, um Sprachmodelle für die kommerzielle Nutzung zu entwickeln.
Amazon
Wie Amazon und NVIDIA Verkäufern helfen, bessere Produktangebote mit KI zu erstellen
Amazon verdoppelt die Inferenzgeschwindigkeit neuer KI-Funktionen mithilfe von NVIDIA TensorRT-LLM und GPUs, die Verkäufern helfen, Produktangebote schneller zu optimieren.
Amdocs
NVIDIA und Amdocs stellen kundenspezifische generative KI für globale Telekommunikationsunternehmen bereit
Amdocs plant, mithilfe des NVIDIA AI Foundry-Diensts auf Microsoft Azure maßgeschneiderte LLMs für die 1,7 Billionen US-Dollar schwere globale Telekommunikationsbranche zu entwickeln.
AT&T
AT&T steigert die Genauigkeit, Effizienz und Leistung der KI-Agenten im Kundenservice mit NVIDIA NeMo
AT&T, eines der weltweit größten Telekommunikationsunternehmen, gestaltet den Kundenservice durch die Kraft von KI neu. Angesichts von Herausforderungen wie Modellabweichungen, steigenden Rechenanforderungen und dem Bedarf an Echtzeit-Datenzugriff entschied sich AT&T für NVIDIA NeMo™ Microservices, um eine feedback-basierte KI-Plattform zu entwickeln, die die Leistung kontinuierlich verbessert und gleichzeitig Kosten, Geschwindigkeit und Compliance optimiert.
AWS
NVIDIA unterstützt das Training für einige der größten Amazon Titan Foundation-Modelle
Amazon nutzte das NVIDIA NeMo Framework, GPUs und AWS EFAs, um sein LLM der nächsten Generation zu trainieren. So bietet Amazon Kunden mit einigen der größten Amazon Titan Foundation-Modelle eine schnellere, zugänglichere Lösung für generative KI.
Accenture
Beschleunigen Sie die Einführung generativer KI für Unternehmen
ServiceNow, NVIDIA und Accenture haben die Einführung von AI Lighthouse angekündigt, einem einzigartigen Programm, das entwickelt wurde, um die Entwicklung und Einführung von generativen KI-Funktionen in Unternehmen zu beschleunigen.
Azure
Nutzen der Leistung von NVIDIA AI Enterprise mit Azure Machine Learning
Holen Sie sich Zugriff auf ein vollständiges Ökosystem mit Tools, Bibliotheken, Frameworks und Supportdiensten, die speziell auf Unternehmensumgebungen zugeschnitten sind, die Microsoft Azure verwenden.
Bria
Bria entwickelt verantwortungsvolle generative KI für Unternehmen mit NVIDIA NeMo und Picasso
Bria ist ein in Tel Aviv ansässiges Start-up, das Unternehmen unterstützt, die nach verantwortlichen Möglichkeiten suchen, eine visuelle generative KI-Technologie mit einem generativen KI-Service in ihre Unternehmensprodukte zu integrieren, der neben fairer Namensnennung und Urheberrechtsschutz auch Wert legt auf Modelltransparenz.
Cohesity
Entfesseln Sie Ihre Daten-Superkraft: NVIDIA Microservices ermöglichen sichere generative KI in Unternehmensqualität für Cohesity.
Mit NVIDIA NIM und optimierten Modellen können Cohesity DataProtect-Kunden zu Datensicherungen und -archiven generative KI-Intelligenz hinzufügen. Das ermöglicht es Cohesity und NVIDIA, die Vorteile generativer KI allen Kunden von Cohesity DataProtect anzubieten. Durch Nutzung der von NIM und NVIDIA optimierten Modelle können sich Kunden von Cohesity DataProtect aus ihren Datensicherungen und -archiven datengestützte Erkenntnisse verschaffen und so von einem unübertroffenen Maß an Effizienz, Innovation und Wachstum profitieren.
CrowdStrike
Gestaltung der Zukunft der KI im Bereich Cybersicherheit
CrowdStrike und NVIDIA nutzen beschleunigtes Computing und generative KI, um Kunden eine innovative Reihe von KI-gestützten Lösungen zu bieten, die auf die effiziente Bewältigung von Sicherheitsbedrohungen zugeschnitten sind.
Dell
Dell validierte Design für generative KI mit NVIDIA
Dell Technologies und NVIDIA planen ein Programm, um es Unternehmen zu erleichtern, generative KI-Modelle schnell und sicher vor Ort zu erstellen und zu verwenden.
Deloitte
Nutzen Sie die Vorteile generativer KI auf allen Unternehmenssoftwareplattformen
Deloitte greift auf NVIDIA-KI-Technologie und -Know-how zurück, um hochleistungsfähige generative KI-Lösungen für Unternehmenssoftwareplattformen zu entwickeln und so einen erheblichen Geschäftswert zu schaffen.
Domino Data Lab
Domino bietet produktionsreife, mit NVIDIA-Technologie entwickelte generative KI
Mit NVIDIA NeMo können Datenwissenschaftler LLMs auf der Plattform von Domino's für fachspezifische Anwendungsfälle auf der Grundlage von proprietären Daten und geistigem Eigentum optimieren, ohne von vorn anfangen zu müssen.
Dropbox
Dropbox und NVIDIA werden personalisierte generative KI Millionen von Kunden bereitstellen.
Dropbox plant, die KI-Foundry von NVIDIA zu nutzen, um maßgeschneiderte Modelle zu entwickeln und die KI-gestützte Wissensarbeit mit dem universellen Suchtool Dropbox Dash und Dropbox AI zu verbessern.
Google Cloud
KI-Riesen entwickeln gemeinsam generative KI
Auf seiner Next-Konferenz kündigte Google Cloud die Verfügbarkeit seiner A3-Instanzen an, die von NVIDIA H100 Tensor Core GPUs unterstützt werden. Entwicklungsteams beider Unternehmen arbeiteten zusammen, um NVIDIA NeMo mir den A3-Instanzen für schnelleres Training und Inferenz zu kombinieren.
HuggingFace
Führende KI-Community zur Beschleunigung der Datenkuration
Hugging Face, die führende offene Plattform für KI-Entwickler, arbeitet mit NVIDIA zusammen, um NeMo Curator zu integrieren und DataTrove, ihre Bibliothek zur Datenfilterung und Deduplizierung, zu beschleunigen. „Wir sind begeistert von den GPU-Beschleunigungsfunktionen von NeMo Curator und können es kaum erwarten, dass sie zu DataTrove beitragen!“ sagt Jeff Boudier, Product Director bei Hugging Face.
KT
Ein neues Kundenerlebnis dank LLMs
Südkoreas führender Mobilfunkbetreiber erstellt LLMs mit Milliarden von Parametern, die mit der NVIDIA DGX SuperPOD-Plattform und dem NeMo Framework trainiert werden, um smarte Lautsprecher und Kundenzentren zu unterstützen.
Lenovo
Neue Referenzarchitektur für generative KI auf Basis von LLMs
Lösung zur schnelleren Entwicklung von Innovationen, die es Partnern und Kunden weltweit ermöglicht, KI in großem Maßstab und branchenübergreifend mit höchster Sicherheit und Effizienz zu entwickeln, zu trainieren und bereitzustellen.
Quantiphi
Für die schnellere Implementierung von KI in Unternehmen
Quantiphi ist auf das Training und die Feinabstimmung von Grundmodellen mit dem NVIDIA NeMo-Framework sowie auf die Optimierung von Bereitstellungen in großem Maßstab mit der NVIDIA AI Enterprise-Softwareplattform spezialisiert. Dabei legt Quantiphi immer Wert darauf, nach den Prinzipien für verantwortliche KI zu handeln
SAP
SAP und NVIDIA beschleunigen die Einführung generativer KI in Unternehmensanwendungen
Kunden können ihre Geschäftsdaten in Cloud-Lösungen von SAP mit maßgeschneiderten LLMs nutzen, die mit NVIDIA AI Foundry-Services und NVIDIA NIM Microservices bereitgestellt werden.
ServiceNow
Generative KI über die gesamte Unternehmens-IT hinweg
ServiceNow entwickelt kundenspezifische LLMs auf seiner ServiceNow-Plattform, um intelligente Workflow-Automatisierung zu ermöglichen und die Produktivität der gesamten IT-Prozesse in Unternehmen zu steigern.
Perplexity
Verbessern Sie die Modellleistung für KI-gestützte Suchmaschinen
Mithilfe von NVIDIA NeMo zielt Perplexity auf die schnelle Anpassung von „Frontier“-Modellen ab, um die Genauigkeit und Qualität der Suchergebnisse zu optimieren und durch geringere Latenz und einen hohen Durchsatz das Benutzererlebnis zu verbessern.
VMware
VMware und NVIDIA fördern den Einsatz von generativer KI für Unternehmen
VMware Private AI Foundation und NVIDIA ermöglichen Unternehmen, Modelle anzupassen und generative KI-Anwendungen auszuführen, einschließlich intelligenter Chatbots, Assistenten, Suchen und Zusammenfassung.
Weights & Biases
LLM-Pipelines debuggen, optimieren und überwachen
Weights & Biases hilft Teams, die an generativen KI-Anwendungsfällen oder mit LLMs arbeiten, alle Prompt-Engineering-Experimente zu verfolgen und zu visualisieren, um Benutzern beim Debuggen und Optimieren von LLMs zu helfen. Außerdem bietet es Überwachungs- und Beobachtbarkeitsfunktionen für LLMs.
Writer
Start-up schreibt generative KI-Erfolgsgeschichte mit NVIDIA NeMo
Mit NVIDIA NeMo entwickelt Writer LLMs, die Hunderten von Unternehmen helfen, maßgeschneiderte Inhalte für Unternehmensanwendungen in den Bereichen Marketing, Schulung, Support und mehr zu erstellen.
Arize
Arize unterstützt selbstverbessernde KI-Daten-Flywheels
Die LLM-Engineering- und Beobachtbarkeitsplattform von Arize integriert NVIDIA NeMo Microservices, um KI-Daten-Flywheels zu unterstützen und eine kontinuierliche Modellverfeinerung durch reales Feedback zu ermöglichen. Mit NeMo Customizer, Evaluator und Guardrails stellt Arize sicher, dass agentenbasierte Systeme leistungsstark, sicher und auf sich entwickelnde Unternehmensanforderungen ausgerichtet sind. Diese Zusammenarbeit unterstützt die Entwicklung von adaptiver KI, die im Laufe der Zeit lernt und sich weiterentwickelt.
DataRobot
Unternehmensfähige, vertrauenswürdige KI-Agenten mit NeMo auf DataRobot
Mit NVIDIA NeMo, das in die DataRobot Unternehmens-KI Suite eingebettet ist, können Unternehmen sicherstellen, dass agentische Systeme sicher, konform und auf unternehmensspezifischen Daten basieren. Diese Integration erleichtert die Entwicklung von KI-Agenten, die genaue, kontextbezogene Antworten liefern und gleichzeitig die Unternehmensstandards einhalten.
Datastax
DataStax und NVIDIA entwickeln Daten- und KI-Plattform
Im vergangenen Jahr hat DataStax mit NVIDIA zusammengearbeitet, um die NVIDIA NeMo Microservices einzuführen, um generative KI, Retrieval-Augmented Generation und hybride Suche in seinen Datenbank- und KI-Angeboten zu verbessern. Die Ergebnisse sind beeindruckend: 19-mal bessere Leistung beim Durchsatz, eine erhebliche Kostensenkung und verbesserte Latenz.
Galileo
Galileo und NVIDIA NeMo: Risikominderung agentischer KI in der Produktion
Galileo integriert NVIDIA NeMo Microservices, um KI-Daten-Flywheels zu entwickeln, die die Leistung, Zuverlässigkeit und Vertrauen von Agenten stärken. NeMo ergänzt die Galileo-Plattform um ergänzende Funktionen, ermöglicht eine kontinuierliche fachspezifische Feinabstimmung über NeMo Customizer, fortschrittliche Bewertung mit NeMo Evaluator und den Schutz von Benutzerinteraktionen mit NeMo Guardrails, um KI-Teams in die Lage zu versetzen, agentische KI-Systeme zu entwickeln, zu bewerten und zu überwachen, die in realen Umgebungen kontinuierlich lernen und sich verbessern.