Inferenz
NVIDIA Triton Inference Server
KI für jede beliebige Anwendung auf jeder beliebigen Plattform bereitstellen, ausführen und skalieren.
Inferenz für jede KI-Workload
Mit dem NVIDIA Triton™ Inference Server können Sie Inferenz an trainierten Modellen für maschinelles Lernen oder Deep Learning aus jedem beliebigen Framework auf jedem beliebigen Prozessor – Grafikprozessor, CPU oder Sonstiges – ausführen. Triton Inference Server ist Teil der KI-Plattform von NVIDIA und verfügbar mit NVIDIA AI Enterprise Es ist eine Open-Source-Software, die die Bereitstellung und Ausführung von KI-Modellen für jede Workload standardisiert.
Die Vorteile von Triton Inference Server

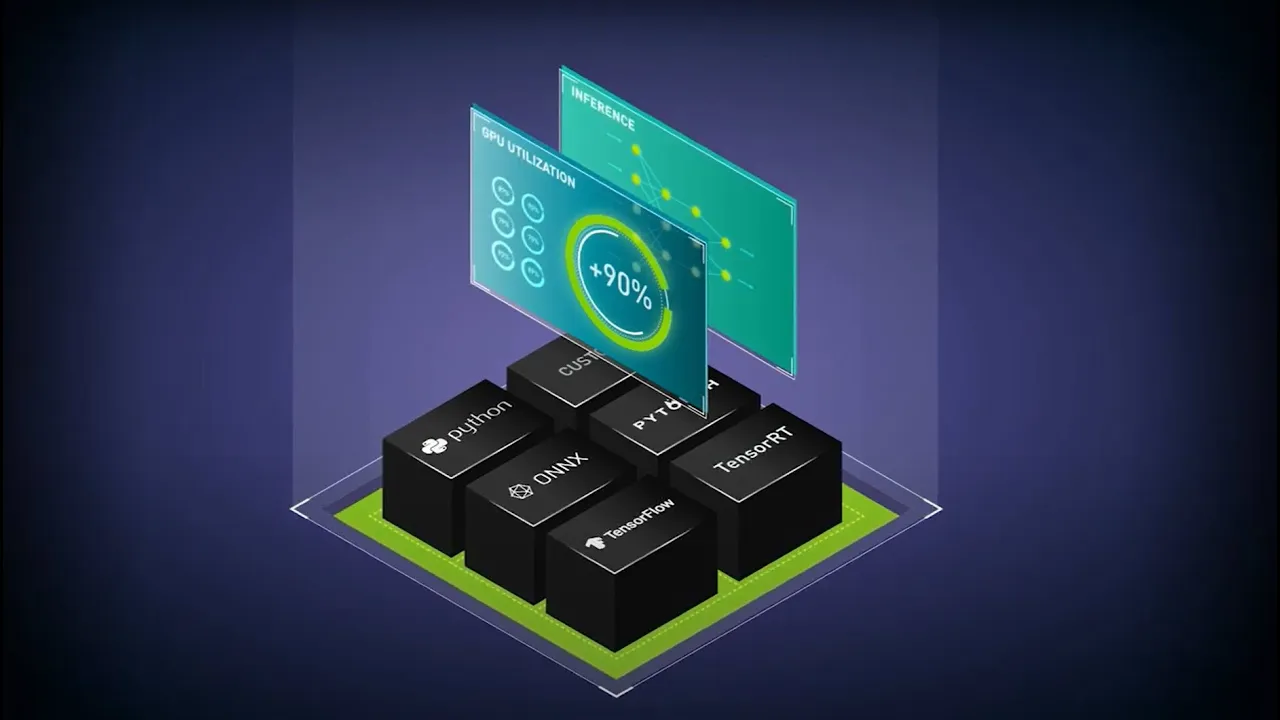
Unterstützt alle Frameworks für Training und Inferenz
Bereitstellung von KI-Modellen auf jedem wichtigen Framework mit Triton Inference Server – einschließlich TensorFlow, PyTorch, Python, ONNX, NVIDIA® TensorRT™, RAPIDS™ cuML, XGBoost, scikit-learn RandomForest, OpenVINO, Custom C++ und mehr.

Hochleistungs-Inferenz auf jeder beliebigen Plattform
Maximieren Sie den Durchsatz und die Auslastung mit dynamischem Batching, simultaner Ausführung, optimaler Konfiguration sowie Audio- und Video-Streaming. Triton Inference Server unterstützt alle NVIDIA-Grafikprozessoren, x86- und Arm-CPUs sowie AWS Inferentia.

Quelloffen und entwickelt für DevOps und MLOps
Integrieren Sie Triton Inference Server in DevOps- und MLOps-Lösungen wie Kubernetes zur Skalierung und Prometheus zur Überwachung. Außerdem kann die Lösung auf allen wichtigen Cloud- und lokalen KI- und MLOps- Plattformen verwendet werden.

Sicherheit, Verwaltbarkeit und API-Stabilität auf Unternehmensniveau
NVIDIA AI Enterprise, einschließlich NVIDIA Triton Inference Server, ist eine sichere, produktionsbereite KI-Softwareplattform, die darauf ausgelegt ist, die Wertschöpfung durch Support, Sicherheit und API-Stabilität zu beschleunigen.
Entdecken Sie die Funktionen und Tools des NVIDIA Triton Inference Server

Inferenz für große Sprachmodelle
Triton bietet eine niedrige Latenz und einen hohen Durchsatz für die Inferenz mit großen Sprachmodellen (Large Language Models, LLM). Es unterstützt TensorRT-LLMs, eine Open-Source-Bibliothek zum Definieren, Optimieren und Ausführen von LLMs für die Inferenz in der Produktion.

Modell-Ensembles
Triton Modell-Ensembles ermöglicht Ihnen die Ausführung von KI-Workloads mit mehreren Modellen, Pipelines sowie Vor- und Nachverarbeitungsschritten. Es können verschiedene Teile des Ensembles auf der CPU oder dem Grafikprozessor ausgeführt werden und unterstützt somit mehrere Frameworks innerhalb des Ensembles.

NVIDIA PyTriton
PyTriton ermöglicht Python-Entwicklern, Triton mit einer einzigen Codezeile aufzurufen und es zur Bereitstellung von Modellen, einfachen Verarbeitungsfunktionen oder ganzen Inferenzpipelines zu verwenden, um Prototyping und Tests zu beschleunigen.

NVIDIA Triton Model Analyzer
Der Model Analyzer reduziert die Zeit, die benötigt wird, um die optimale Konfiguration für die Modellbereitstellung zu finden, z. B. für Batchgröße, Präzision und Instanzen für simultane Ausführung. Er hilft bei der Auswahl der optimalen Konfiguration, um Anwendungslatenz, Durchsatz und Speicheranforderungen zu erfüllen.
Führende Anwender in allen Branchen
-
Kunde
-
Ökosystemintegrationen
Erste Schritte mit NVIDIA Triton
Nutzen Sie die richtigen Tools, um KI für verschiedenste Anwendungen auf sämtlichen Plattformen bereitzustellen, auszuführen und zu skalieren.
Beginnen Sie mit der Entwicklung via Code oder Container
Für diejenigen, die für die Entwicklung auf den Open-Source-Code und die Container von Triton zugreifen möchten, gibt es zwei kostenlose Einstiegsmöglichkeiten:
Erst testen, dann kaufen
Für Unternehmen, die Triton testen möchten, bevor sie NVIDIA AI Enterprise für die Produktion kaufen, gibt es zwei kostenlose Einstiegsoptionen:
Ressourcen
-
Videos
-
Schulung
-
Blogs
-
Sessions
-
Erfolgsgeschichten
-
Community


















Wie geht es weiter?
Sind Sie bereit?
Finden Sie die richtige Lizenz, um KI für verschiedenste Anwendungen auf sämtlichen Plattformen bereitzustellen, auszuführen und zu skalieren, oder entdecken Sie weitere Entwicklungsressourcen.
Kontakt aufnehmen
Sprechen Sie mit einem NVIDIA-Produktspezialisten über den Wechsel von der Pilotphase zur Produktionsumgebung mit der Sicherheit, der API-Stabilität und dem Support von NVIDIA AI Enterprise.
Erhalten Sie aktuelle Infos zu NVIDIA Triton Inference Server
Ich möchte aktuelle Neuigkeiten, Updates und weitere Informationen von NVIDIA erhalten.